 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model Robustness with Latent Distribution Locally and Globally
Paper and Code
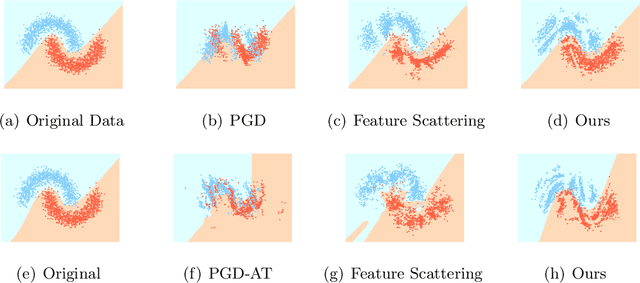
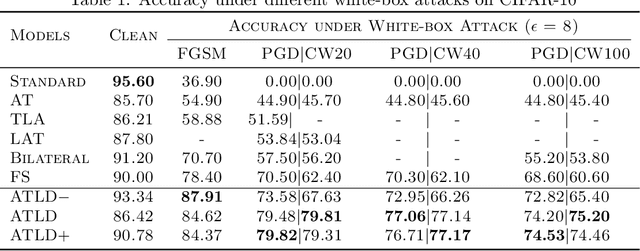
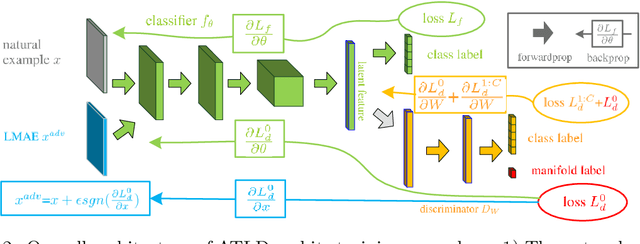
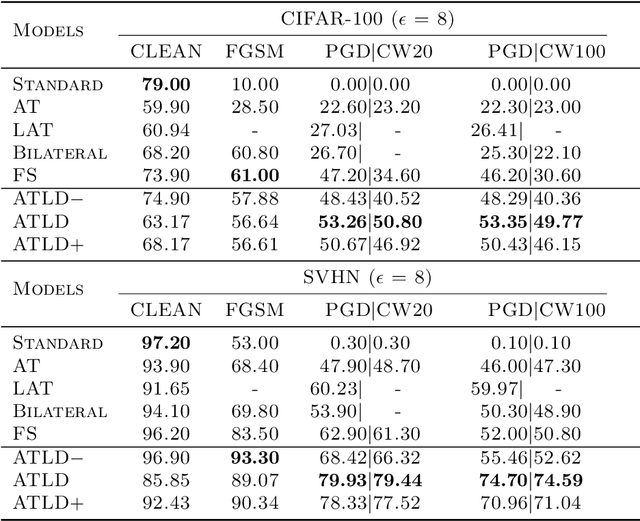
In this work, we consider model robustness of deep neural networks against adversarial attacks from a global manifold perspective. Leveraging both the local and global latent information, we propose a novel adversarial training method through robust optimization, and a tractable way to generate Latent Manifold Adversarial Examples (LMAEs) via an adversarial game between a discriminator and a classifier. The proposed adversarial training with latent distribution (ATLD) method defends against adversarial attacks by crafting LMAEs with the latent manifold in an unsupervised manner. ATLD preserves the local and global information of latent manifold and promises improved robustness against adversarial attacks. To verify the effectiveness of our proposed method, we conduct extensive experiments over different datasets (e.g., CIFAR-10, CIFAR-100, SVHN) with different adversarial attacks (e.g., PGD, CW), and show that our method substantially outperforms the state-of-the-art (e.g., Feature Scattering) in adversarial robustness by a large accuracy margin. The source codes are available at https://github.com/LitterQ/ATLD-pytorch.