 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGLE-Pangu: Accelerator-Safe Tree Speculative Decoding on Ascend NPUs
Mar 09, 2026Autoregressive decoding remains a primary bottleneck in large language model (LLM) serving, motivating speculative decoding methods that reduce expensive teacher-model invocations by verifying multiple candidate tokens per step. Tree-structured speculation further increases parallelism, but is often brittle when ported across heterogeneous backends and accelerator stacks, where attention masking, KV-cache layouts, and indexing semantics are not interchangeable. We present EAGLE-Pangu, a reproducible system that ports EAGLE-3-style tree speculative decoding to a Pangu teacher backend on Ascend NPUs. EAGLE-Pangu contributes (i) an explicit branch/commit cache manager built on the Cache API, (ii) accelerator-safe tree tensorization that removes undefined negative indices by construction and validates structural invariants, and (iii) a fused-kernel-compatible teacher verification path with a debuggable eager fallback. On 240 turns from MT-Bench and HumanEval-style prompts, EAGLE-Pangu improves end-to-end decoding throughput by 1.27x on average, up to 2.46x at p99, over teacher-only greedy decoding in the fused-kernel performance path. We also provide a fused-kernel-free reference path with structured traces and invariant checks to support reproducible debugging and ablation across execution modes and tree budgets.
HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Can MLLMs Absorb Math Reasoning Abilities from LLMs as Free Lunch?
Oct 16, 2025Math reasoning has been one crucial ability of large language models (LLMs), where significant advancements have been achieved in recent years. However, most efforts focus on LLMs by curating high-quality annotation data and intricate training (or inference) paradigms, while the math reasoning performance of multi-modal LLMs (MLLMs) remains lagging behind. Since the MLLM typically consists of an LLM and a vision block, we wonder: Can MLLMs directly absorb math reasoning abilities from off-the-shelf math LLMs without tuning? Recent model-merging approaches may offer insights into this question. However, they overlook the alignment between the MLLM and LLM, where we find that there is a large gap between their parameter spaces, resulting in lower performance. Our empirical evidence reveals two key factors behind this issue: the identification of crucial reasoning-associated layers in the model and the mitigation of the gaps in parameter space. Based on the empirical insights, we propose IP-Merging that first identifies the reasoning-associated parameters in both MLLM and Math LLM, then projects them into the subspace of MLLM, aiming to maintain the alignment, and finally merges parameters in this subspace. IP-Merging is a tuning-free approach since parameters are directly adjusted. Extensive experiments demonstrate that our IP-Merging method can enhance the math reasoning ability of MLLMs directly from Math LLMs without compromising their other capabilities.
Disentangling Tabular Data towards Better One-Class Anomaly Detection
Nov 12, 2024Tabular anomaly detection under the one-class classification setting poses a significant challenge, as it involves accurately conceptualizing "normal" derived exclusively from a single category to discern anomalies from normal data variations. Capturing the intrinsic correlation among attributes within normal samples presents one promising method for learning the concept. To do so, the most recent effort relies on a learnable mask strategy with a reconstruction task. However, this wisdom may suffer from the risk of producing uniform masks, i.e., essentially nothing is masked, leading to less effective correlation learning. To address this issue, we presume that attributes related to others in normal samples can be divided into two non-overlapping and correlated subsets, defined as CorrSets, to capture the intrinsic correlation effectively. Accordingly, we introduce an innovative method that disentangles CorrSets from normal tabular data. To our knowledge, this is a pioneering effort to apply the concept of disentanglement for one-class anomaly detection on tabular data. Extensive experiments on 20 tabular datasets show that our method substantially outperforms the state-of-the-art methods and leads to an average performance improvement of 6.1% on AUC-PR and 2.1% on AUC-ROC.
Covariance-based Space Regularization for Few-shot Class Incremental Learning
Nov 02, 2024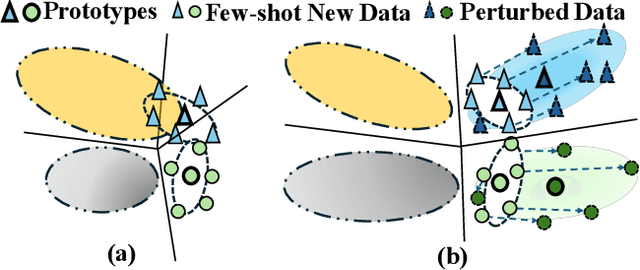
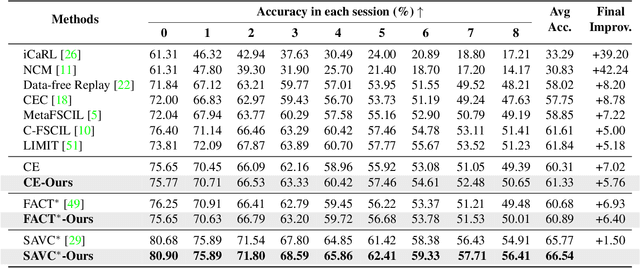
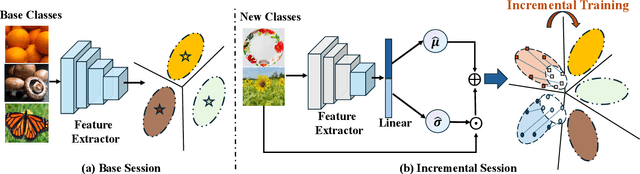
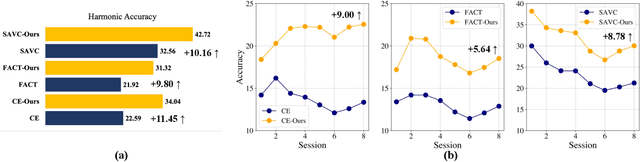
Few-shot Class Incremental Learning (FSCIL) presents a challenging yet realistic scenario, which requires the model to continually learn new classes with limited labeled data (i.e., incremental sessions) while retaining knowledge of previously learned base classes (i.e., base sessions). Due to the limited data in incremental sessions, models are prone to overfitting new classes and suffering catastrophic forgetting of base classes. To tackle these issues, recent advancements resort to prototype-based approaches to constrain the base class distribution and learn discriminative representations of new classes. Despite the progress, the limited data issue still induces ill-divided feature space, leading the model to confuse the new class with old classes or fail to facilitate good separation among new classes. In this paper, we aim to mitigate these issues by directly constraining the span of each class distribution from a covariance perspective. In detail, we propose a simple yet effective covariance constraint loss to force the model to learn each class distribution with the same covariance matrix. In addition, we propose a perturbation approach to perturb the few-shot training samples in the feature space, which encourages the samples to be away from the weighted distribution of other classes. Regarding perturbed samples as new class data, the classifier is forced to establish explicit boundaries between each new class and the existing ones. Our approach is easy to integrate into existing FSCIL approaches to boost performance. Experiments on three benchmarks validate the effectiveness of our approach, achieving a new state-of-the-art performance of FSCIL.
SaliencyCut: Augmenting Plausible Anomalies for Open-set Fine-Grained Anomaly Detection
Jun 14, 2023Open-set fine-grained anomaly detection is a challenging task that requires learning discriminative fine-grained features to detect anomalies that were even unseen during training. As a cheap yet effective approach, data augmentation has been widely used to create pseudo anomalies for better training of such models. Recent wisdom of augmentation methods focuses on generating random pseudo instances that may lead to a mixture of augmented instances with seen anomalies, or out of the typical range of anomalies. To address this issue, we propose a novel saliency-guided data augmentation method, SaliencyCut, to produce pseudo but more common anomalies which tend to stay in the plausible range of anomalies. Furthermore, we deploy a two-head learning strategy consisting of normal and anomaly learning heads, to learn the anomaly score of each sample. Theoretical analyses show that this mechanism offers a more tractable and tighter lower bound of the data log-likelihood. We then design a novel patch-wise residual module in the anomaly learning head to extract and assess the fine-grained anomaly features from each sample, facilitating the learning of discriminative representations of anomaly instances. Extensive experiments conducted on six real-world anomaly detection datasets demonstrate the superiority of our method to the baseline and other state-of-the-art methods under various settings.