 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Instance-Level Self-Supervision in 3D Multi-Modal Medical Imaging
May 14, 2026Self-supervised pre-training methods in medical imaging typically treat each individual as an isolated instance, learning representations through augmentation-based objectives or masked reconstruction. They often do not adequately capitalize on a key characteristic of physiological features: anatomical structures maintain consistent spatial relationships across individuals (instances), such as the thalamus being medial to the basal ganglia, regardless of variations in brain size, shape, or pathology. We propose leveraging this cross-instance topological consistency as a supervisory signal. The challenge arises from the inherent variability in medical imaging, which can differ significantly across instances and modalities. To tackle this, we focus on two alignment regimes. (i) Intra-instance: with pixel-level correspondences available, a cross-modal triplet objective explicitly preserves local neighborhood topology. (ii) Inter-instance: without such supervision, we derive pseudo-correspondences to control partial neighborhood alignment and prevent topology collapse across modalities. We validate our approach across 7 downstream multi-modal tasks, achieving average improvements of 1.1% and 5.94% in segmentation and classification tasks, respectively, and demonstrating significantly better robustness when modalities are missing at test time.
GAST: Gradient-aligned Sparse Tuning of Large Language Models with Data-layer Selection
Mar 10, 2026Parameter-Efficient Fine-Tuning (PEFT) has become a key strategy for adapting large language models, with recent advances in sparse tuning reducing overhead by selectively updating key parameters or subsets of data. Existing approaches generally focus on two distinct paradigms: layer-selective methods aiming to fine-tune critical layers to minimize computational load, and data-selective methods aiming to select effective training subsets to boost training. However, current methods typically overlook the fact that different data points contribute varying degrees to distinct model layers, and they often discard potentially valuable information from data perceived as of low quality. To address these limitations, we propose Gradient-aligned Sparse Tuning (GAST), an innovative method that simultaneously performs selective fine-tuning at both data and layer dimensions as integral components of a unified optimization strategy. GAST specifically targets redundancy in information by employing a layer-sparse strategy that adaptively selects the most impactful data points for each layer, providing a more comprehensive and sophisticated solution than approaches restricted to a single dimension. Experiments demonstrate that GAST consistently outperforms baseline methods, establishing a promising direction for future research in PEFT strategies.
Minimal Semantic Sufficiency Meets Unsupervised Domain Generalization
Sep 19, 2025The generalization ability of deep learning has been extensively studied in supervised settings, yet it remains less explored in unsupervised scenarios. Recently, the Unsupervised Domain Generalization (UDG) task has been proposed to enhance the generalization of models trained with prevalent unsupervised learning techniques, such as Self-Supervised Learning (SSL). UDG confronts the challenge of distinguishing semantics from variations without category labels. Although some recent methods have employed domain labels to tackle this issue, such domain labels are often unavailable in real-world contexts. In this paper, we address these limitations by formalizing UDG as the task of learning a Minimal Sufficient Semantic Representation: a representation that (i) preserves all semantic information shared across augmented views (sufficiency), and (ii) maximally removes information irrelevant to semantics (minimality). We theoretically ground these objectives from the perspective of information theory, demonstrating that optimizing representations to achieve sufficiency and minimality directly reduces out-of-distribution risk. Practically, we implement this optimization through Minimal-Sufficient UDG (MS-UDG), a learnable model by integrating (a) an InfoNCE-based objective to achieve sufficiency; (b) two complementary components to promote minimality: a novel semantic-variation disentanglement loss and a reconstruction-based mechanism for capturing adequate variation. Empirically, MS-UDG sets a new state-of-the-art on popular unsupervised domain-generalization benchmarks, consistently outperforming existing SSL and UDG methods, without category or domain labels during representation learning.
Exploiting Layer Normalization Fine-tuning in Visual Transformer Foundation Models for Classification
Aug 11, 2025LayerNorm is pivotal in Vision Transformers (ViTs), yet its fine-tuning dynamics under data scarcity and domain shifts remain underexplored. This paper shows that shifts in LayerNorm parameters after fine-tuning (LayerNorm shifts) are indicative of the transitions between source and target domains; its efficacy is contingent upon the degree to which the target training samples accurately represent the target domain, as quantified by our proposed Fine-tuning Shift Ratio ($FSR$). Building on this, we propose a simple yet effective rescaling mechanism using a scalar $\lambda$ that is negatively correlated to $FSR$ to align learned LayerNorm shifts with those ideal shifts achieved under fully representative data, combined with a cyclic framework that further enhances the LayerNorm fine-tuning. Extensive experiments across natural and pathological images, in both in-distribution (ID) and out-of-distribution (OOD) settings, and various target training sample regimes validate our framework. Notably, OOD tasks tend to yield lower $FSR$ and higher $\lambda$ in comparison to ID cases, especially with scarce data, indicating under-represented target training samples. Moreover, ViTFs fine-tuned on pathological data behave more like ID settings, favoring conservative LayerNorm updates. Our findings illuminate the underexplored dynamics of LayerNorm in transfer learning and provide practical strategies for LayerNorm fine-tuning.
Structure-aware Semantic Discrepancy and Consistency for 3D Medical Image Self-supervised Learning
Jul 03, 20253D medical image self-supervised learning (mSSL) holds great promise for medical analysis. Effectively supporting broader applications requires considering anatomical structure variations in location, scale, and morphology, which are crucial for capturing meaningful distinctions. However, previous mSSL methods partition images with fixed-size patches, often ignoring the structure variations. In this work, we introduce a novel perspective on 3D medical images with the goal of learning structure-aware representations. We assume that patches within the same structure share the same semantics (semantic consistency) while those from different structures exhibit distinct semantics (semantic discrepancy). Based on this assumption, we propose an mSSL framework named $S^2DC$, achieving Structure-aware Semantic Discrepancy and Consistency in two steps. First, $S^2DC$ enforces distinct representations for different patches to increase semantic discrepancy by leveraging an optimal transport strategy. Second, $S^2DC$ advances semantic consistency at the structural level based on neighborhood similarity distribution. By bridging patch-level and structure-level representations, $S^2DC$ achieves structure-aware representations. Thoroughly evaluated across 10 datasets, 4 tasks, and 3 modalities, our proposed method consistently outperforms the state-of-the-art methods in mSSL.
ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
Dec 13, 2024Offsite-tuning is a privacy-preserving method for tuning large language models (LLMs) by sharing a lossy compressed emulator from the LLM owners with data owners for downstream task tuning. This approach protects the privacy of both the model and data owners. However, current offsite tuning methods often suffer from adaptation degradation, high computational costs, and limited protection strength due to uniformly dropping LLM layers or relying on expensive knowledge distillation. To address these issues, we propose ScaleOT, a novel privacy-utility-scalable offsite-tuning framework that effectively balances privacy and utility. ScaleOT introduces a novel layerwise lossy compression algorithm that uses reinforcement learning to obtain the importance of each layer. It employs lightweight networks, termed harmonizers, to replace the raw LLM layers. By combining important original LLM layers and harmonizers in different ratios, ScaleOT generates emulators tailored for optimal performance with various model scales for enhanced privacy protection. Additionally, we present a rank reduction method to further compress the original LLM layers, significantly enhancing privacy with negligible impact on utility. Comprehensive experiments show that ScaleOT can achieve nearly lossless offsite tuning performance compared with full fine-tuning while obtaining better model privacy.
Personalize to generalize: Towards a universal medical multi-modality generalization through personalization
Nov 13, 2024The differences among medical imaging modalities, driven by distinct underlying principles, pose significant challenges for generalization in multi-modal medical tasks. Beyond modality gaps, individual variations, such as differences in organ size and metabolic rate, further impede a model's ability to generalize effectively across both modalities and diverse populations. Despite the importance of personalization, existing approaches to multi-modal generalization often neglect individual differences, focusing solely on common anatomical features. This limitation may result in weakened generalization in various medical tasks. In this paper, we unveil that personalization is critical for multi-modal generalization. Specifically, we propose an approach to achieve personalized generalization through approximating the underlying personalized invariant representation ${X}_h$ across various modalities by leveraging individual-level constraints and a learnable biological prior. We validate the feasibility and benefits of learning a personalized ${X}_h$, showing that this representation is highly generalizable and transferable across various multi-modal medical tasks. Extensive experimental results consistently show that the additionally incorporated personalization significantly improves performance and generalization across diverse scenarios, confirming its effectiveness.
Disentangling Tabular Data towards Better One-Class Anomaly Detection
Nov 12, 2024Tabular anomaly detection under the one-class classification setting poses a significant challenge, as it involves accurately conceptualizing "normal" derived exclusively from a single category to discern anomalies from normal data variations. Capturing the intrinsic correlation among attributes within normal samples presents one promising method for learning the concept. To do so, the most recent effort relies on a learnable mask strategy with a reconstruction task. However, this wisdom may suffer from the risk of producing uniform masks, i.e., essentially nothing is masked, leading to less effective correlation learning. To address this issue, we presume that attributes related to others in normal samples can be divided into two non-overlapping and correlated subsets, defined as CorrSets, to capture the intrinsic correlation effectively. Accordingly, we introduce an innovative method that disentangles CorrSets from normal tabular data. To our knowledge, this is a pioneering effort to apply the concept of disentanglement for one-class anomaly detection on tabular data. Extensive experiments on 20 tabular datasets show that our method substantially outperforms the state-of-the-art methods and leads to an average performance improvement of 6.1% on AUC-PR and 2.1% on AUC-ROC.
Covariance-based Space Regularization for Few-shot Class Incremental Learning
Nov 02, 2024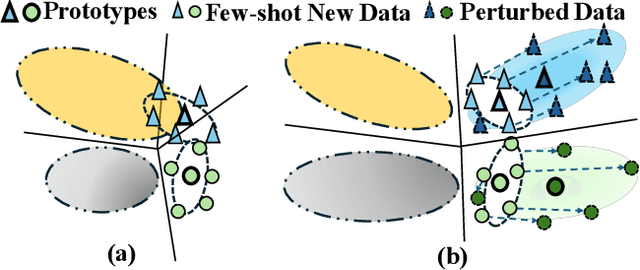
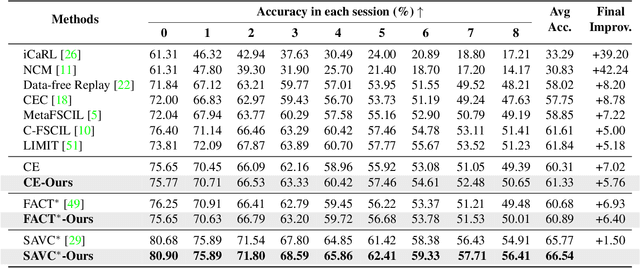
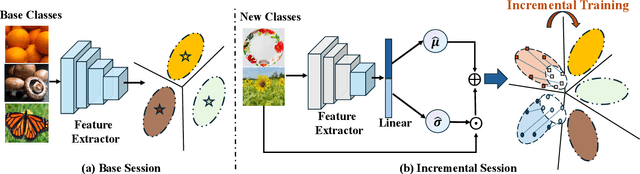
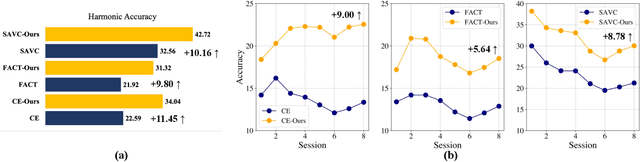
Few-shot Class Incremental Learning (FSCIL) presents a challenging yet realistic scenario, which requires the model to continually learn new classes with limited labeled data (i.e., incremental sessions) while retaining knowledge of previously learned base classes (i.e., base sessions). Due to the limited data in incremental sessions, models are prone to overfitting new classes and suffering catastrophic forgetting of base classes. To tackle these issues, recent advancements resort to prototype-based approaches to constrain the base class distribution and learn discriminative representations of new classes. Despite the progress, the limited data issue still induces ill-divided feature space, leading the model to confuse the new class with old classes or fail to facilitate good separation among new classes. In this paper, we aim to mitigate these issues by directly constraining the span of each class distribution from a covariance perspective. In detail, we propose a simple yet effective covariance constraint loss to force the model to learn each class distribution with the same covariance matrix. In addition, we propose a perturbation approach to perturb the few-shot training samples in the feature space, which encourages the samples to be away from the weighted distribution of other classes. Regarding perturbed samples as new class data, the classifier is forced to establish explicit boundaries between each new class and the existing ones. Our approach is easy to integrate into existing FSCIL approaches to boost performance. Experiments on three benchmarks validate the effectiveness of our approach, achieving a new state-of-the-art performance of FSCIL.
Interpret Your Decision: Logical Reasoning Regularization for Generalization in Visual Classification
Oct 06, 2024Vision models excel in image classification but struggle to generalize to unseen data, such as classifying images from unseen domains or discovering novel categories. In this paper, we explore the relationship between logical reasoning and deep learning generalization in visual classification. A logical regularization termed L-Reg is derived which bridges a logical analysis framework to image classification. Our work reveals that L-Reg reduces the complexity of the model in terms of the feature distribution and classifier weights. Specifically, we unveil the interpretability brought by L-Reg, as it enables the model to extract the salient features, such as faces to persons, for classification. Theoretical analysis and experiments demonstrate that L-Reg enhances generalization across various scenarios, including multi-domain generalization and generalized category discovery. In complex real-world scenarios where images span unknown classes and unseen domains, L-Reg consistently improves generalization, highlighting its practical efficacy.