 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordMatcher: Affordance Learning in 3D Scenes from Visual Signifiers
Mar 30, 2026Affordance learning is a complex challenge in many applications, where existing approaches primarily focus on the geometric structures, visual knowledge, and affordance labels of objects to determine interactable regions. However, extending this learning capability to a scene is significantly more complicated, as incorporating object- and scene-level semantics is not straightforward. In this work, we introduce AffordBridge, a large-scale dataset with 291,637 functional interaction annotations across 685 high-resolution indoor scenes in the form of point clouds. Our affordance annotations are complemented by RGB images that are linked to the same instances within the scenes. Building upon our dataset, we propose AffordMatcher, an affordance learning method that establishes coherent semantic correspondences between image-based and point cloud-based instances for keypoint matching, enabling a more precise identification of affordance regions based on cues, so-called visual signifiers. Experimental results on our dataset demonstrate the effectiveness of our approach compared to other methods.
AeroScene: Progressive Scene Synthesis for Aerial Robotics
Mar 24, 2026Generative models have shown substantial impact across multiple domains, their potential for scene synthesis remains underexplored in robotics. This gap is more evident in drone simulators, where simulation environments still rely heavily on manual efforts, which are time-consuming to create and difficult to scale. In this work, we introduce AeroScene, a hierarchical diffusion model for progressive 3D scene synthesis. Our approach leverages hierarchy-aware tokenization and multi-branch feature extraction to reason across both global layouts and local details, ensuring physical plausibility and semantic consistency. This makes AeroScene particularly suited for generating realistic scenes for aerial robotics tasks such as navigation, landing, and perching. We demonstrate its effectiveness through extensive experiments on our newly collected dataset and a public benchmark, showing that AeroScene significantly outperforms prior methods. Furthermore, we use AeroScene to generate a large-scale dataset of over 1,000 physics-ready, high fidelity 3D scenes that can be directly integrated into NVIDIA Isaac Sim. Finally, we illustrate the utility of these generated environments on downstream drone navigation tasks. Our code and dataset are publicly available at aioz-ai.github.io/AeroScene/
FedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025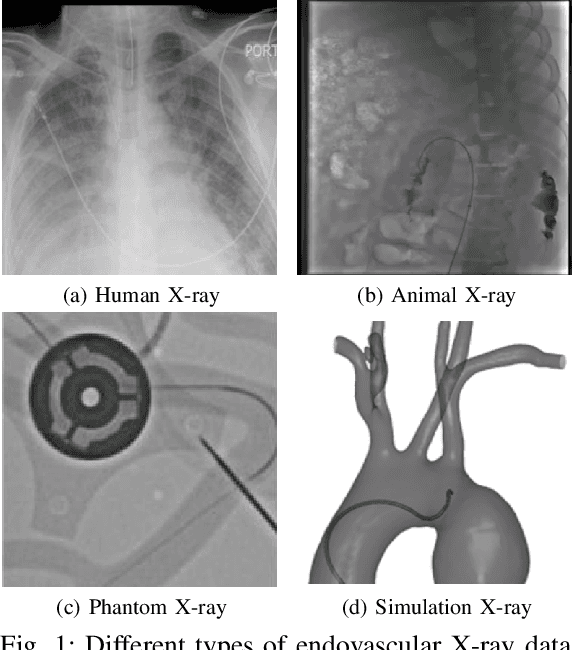
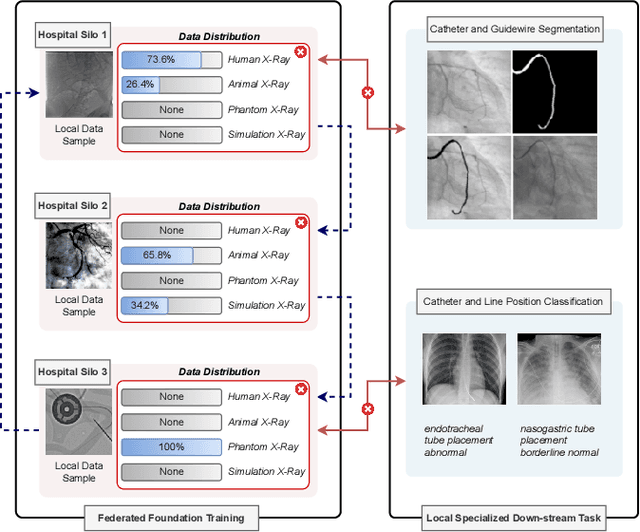

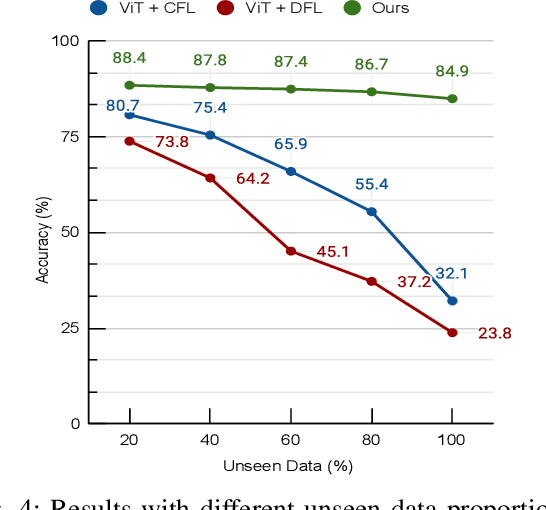
In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.
SplineFormer: An Explainable Transformer-Based Approach for Autonomous Endovascular Navigation
Jan 08, 2025


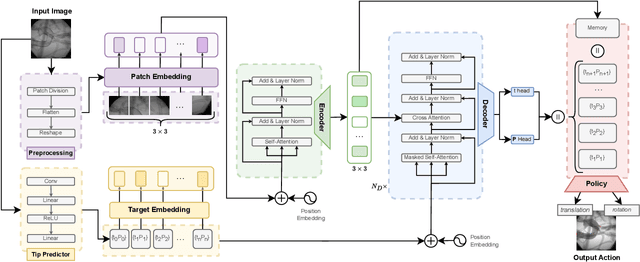
Endovascular navigation is a crucial aspect of minimally invasive procedures, where precise control of curvilinear instruments like guidewires is critical for successful interventions. A key challenge in this task is accurately predicting the evolving shape of the guidewire as it navigates through the vasculature, which presents complex deformations due to interactions with the vessel walls. Traditional segmentation methods often fail to provide accurate real-time shape predictions, limiting their effectiveness in highly dynamic environments. To address this, we propose SplineFormer, a new transformer-based architecture, designed specifically to predict the continuous, smooth shape of the guidewire in an explainable way. By leveraging the transformer's ability, our network effectively captures the intricate bending and twisting of the guidewire, representing it as a spline for greater accuracy and smoothness. We integrate our SplineFormer into an end-to-end robot navigation system by leveraging the condensed information. The experimental results demonstrate that our SplineFormer is able to perform endovascular navigation autonomously and achieves a 50% success rate when cannulating the brachiocephalic artery on the real robot.
Guide3D: A Bi-planar X-ray Dataset for 3D Shape Reconstruction
Oct 29, 2024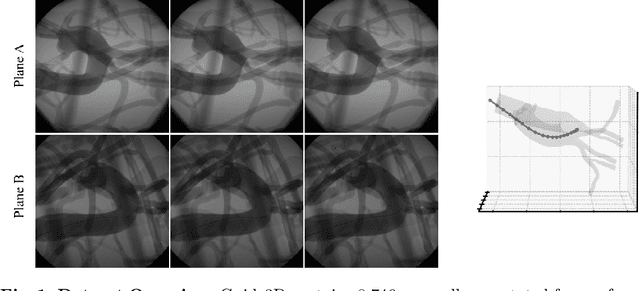
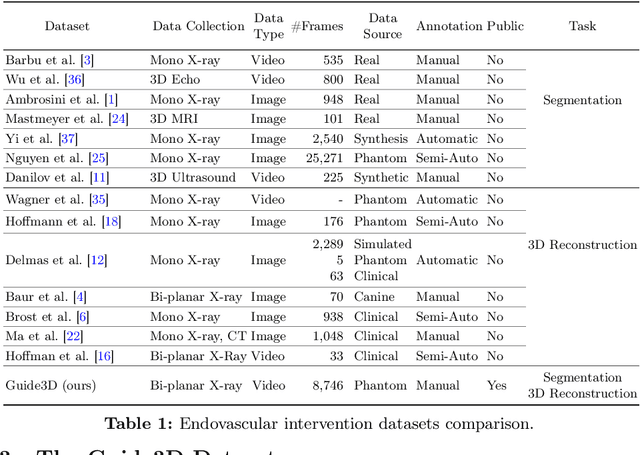

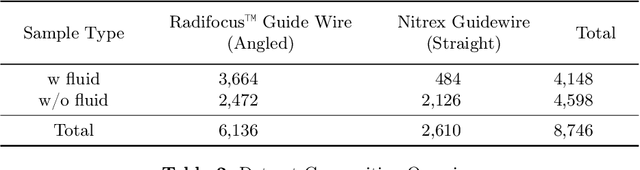
Endovascular surgical tool reconstruction represents an important factor in advancing endovascular tool navigation, which is an important step in endovascular surgery. However, the lack of publicly available datasets significantly restricts the development and validation of novel machine learning approaches. Moreover, due to the need for specialized equipment such as biplanar scanners, most of the previous research employs monoplanar fluoroscopic technologies, hence only capturing the data from a single view and significantly limiting the reconstruction accuracy. To bridge this gap, we introduce Guide3D, a bi-planar X-ray dataset for 3D reconstruction. The dataset represents a collection of high resolution bi-planar, manually annotated fluoroscopic videos, captured in real-world settings. Validating our dataset within a simulated environment reflective of clinical settings confirms its applicability for real-world applications. Furthermore, we propose a new benchmark for guidewrite shape prediction, serving as a strong baseline for future work. Guide3D not only addresses an essential need by offering a platform for advancing segmentation and 3D reconstruction techniques but also aids the development of more accurate and efficient endovascular surgery interventions. Our project is available at https://airvlab.github.io/guide3d/.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
Scalable Group Choreography via Variational Phase Manifold Learning
Jul 26, 2024



Generating group dance motion from the music is a challenging task with several industrial applications. Although several methods have been proposed to tackle this problem, most of them prioritize optimizing the fidelity in dancing movement, constrained by predetermined dancer counts in datasets. This limitation impedes adaptability to real-world applications. Our study addresses the scalability problem in group choreography while preserving naturalness and synchronization. In particular, we propose a phase-based variational generative model for group dance generation on learning a generative manifold. Our method achieves high-fidelity group dance motion and enables the generation with an unlimited number of dancers while consuming only a minimal and constant amount of memory. The intensive experiments on two public datasets show that our proposed method outperforms recent state-of-the-art approaches by a large margin and is scalable to a great number of dancers beyond the training data.
Controllable Group Choreography using Contrastive Diffusion
Nov 03, 2023
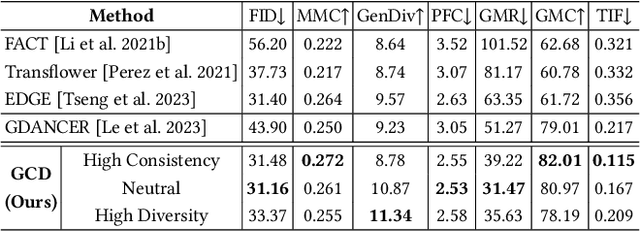
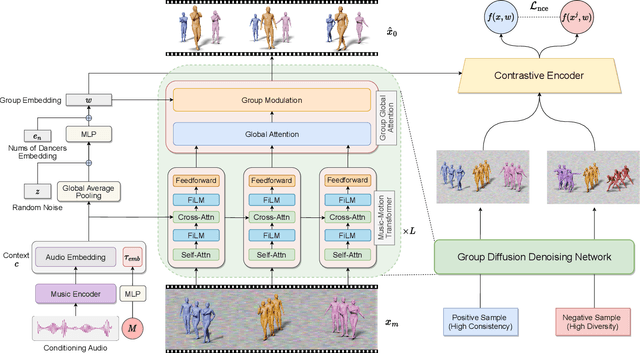
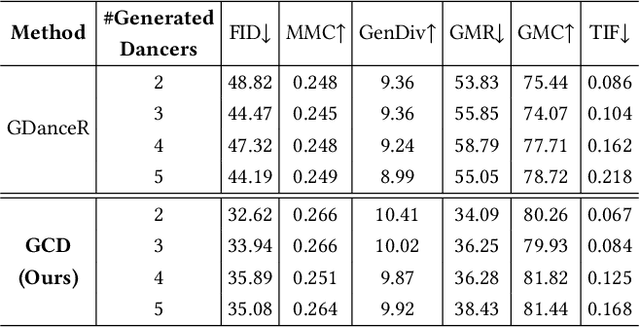
Music-driven group choreography poses a considerable challenge but holds significant potential for a wide range of industrial applications. The ability to generate synchronized and visually appealing group dance motions that are aligned with music opens up opportunities in many fields such as entertainment, advertising, and virtual performances. However, most of the recent works are not able to generate high-fidelity long-term motions, or fail to enable controllable experience. In this work, we aim to address the demand for high-quality and customizable group dance generation by effectively governing the consistency and diversity of group choreographies. In particular, we utilize a diffusion-based generative approach to enable the synthesis of flexible number of dancers and long-term group dances, while ensuring coherence to the input music. Ultimately, we introduce a Group Contrastive Diffusion (GCD) strategy to enhance the connection between dancers and their group, presenting the ability to control the consistency or diversity level of the synthesized group animation via the classifier-guidance sampling technique. Through intensive experiments and evaluation, we demonstrate the effectiveness of our approach in producing visually captivating and consistent group dance motions. The experimental results show the capability of our method to achieve the desired levels of consistency and diversity, while maintaining the overall quality of the generated group choreography. The source code can be found at https://aioz-ai.github.io/GCD
Music-Driven Group Choreography
Mar 27, 2023



Music-driven choreography is a challenging problem with a wide variety of industrial applications. Recently, many methods have been proposed to synthesize dance motions from music for a single dancer. However, generating dance motion for a group remains an open problem. In this paper, we present $\rm AIOZ-GDANCE$, a new large-scale dataset for music-driven group dance generation. Unlike existing datasets that only support single dance, our new dataset contains group dance videos, hence supporting the study of group choreography. We propose a semi-autonomous labeling method with humans in the loop to obtain the 3D ground truth for our dataset. The proposed dataset consists of 16.7 hours of paired music and 3D motion from in-the-wild videos, covering 7 dance styles and 16 music genres. We show that naively applying single dance generation technique to creating group dance motion may lead to unsatisfactory results, such as inconsistent movements and collisions between dancers. Based on our new dataset, we propose a new method that takes an input music sequence and a set of 3D positions of dancers to efficiently produce multiple group-coherent choreographies. We propose new evaluation metrics for measuring group dance quality and perform intensive experiments to demonstrate the effectiveness of our method. Our project facilitates future research on group dance generation and is available at: https://aioz-ai.github.io/AIOZ-GDANCE/
Style Transfer for 2D Talking Head Animation
Mar 22, 2023



Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.