 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Group Choreography via Variational Phase Manifold Learning
Jul 26, 2024



Generating group dance motion from the music is a challenging task with several industrial applications. Although several methods have been proposed to tackle this problem, most of them prioritize optimizing the fidelity in dancing movement, constrained by predetermined dancer counts in datasets. This limitation impedes adaptability to real-world applications. Our study addresses the scalability problem in group choreography while preserving naturalness and synchronization. In particular, we propose a phase-based variational generative model for group dance generation on learning a generative manifold. Our method achieves high-fidelity group dance motion and enables the generation with an unlimited number of dancers while consuming only a minimal and constant amount of memory. The intensive experiments on two public datasets show that our proposed method outperforms recent state-of-the-art approaches by a large margin and is scalable to a great number of dancers beyond the training data.
Interpretability analysis on a pathology foundation model reveals biologically relevant embeddings across modalities
Jul 15, 2024Mechanistic interpretability has been explored in detail for large language models (LLMs). For the first time, we provide a preliminary investigation with similar interpretability methods for medical imaging. Specifically, we analyze the features from a ViT-Small encoder obtained from a pathology Foundation Model via application to two datasets: one dataset of pathology images, and one dataset of pathology images paired with spatial transcriptomics. We discover an interpretable representation of cell and tissue morphology, along with gene expression within the model embedding space. Our work paves the way for further exploration around interpretable feature dimensions and their utility for medical and clinical applications.
Controllable Group Choreography using Contrastive Diffusion
Nov 03, 2023
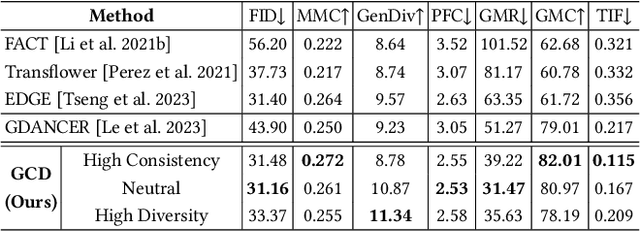
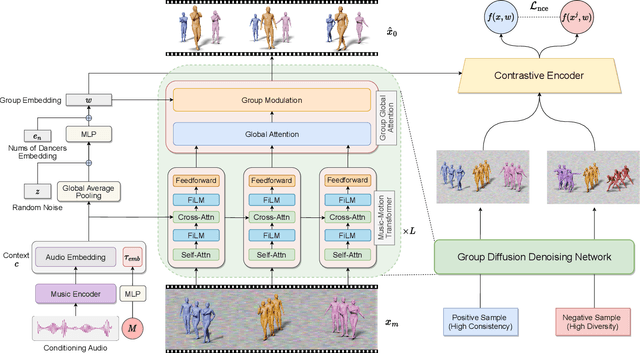
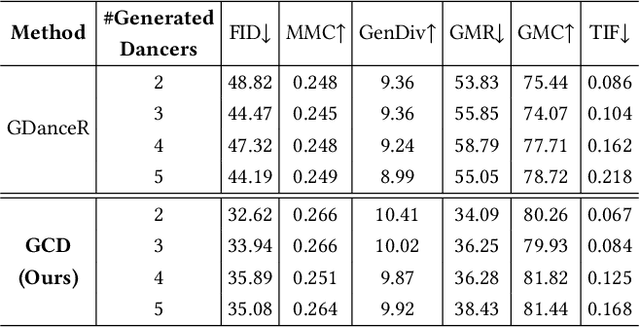
Music-driven group choreography poses a considerable challenge but holds significant potential for a wide range of industrial applications. The ability to generate synchronized and visually appealing group dance motions that are aligned with music opens up opportunities in many fields such as entertainment, advertising, and virtual performances. However, most of the recent works are not able to generate high-fidelity long-term motions, or fail to enable controllable experience. In this work, we aim to address the demand for high-quality and customizable group dance generation by effectively governing the consistency and diversity of group choreographies. In particular, we utilize a diffusion-based generative approach to enable the synthesis of flexible number of dancers and long-term group dances, while ensuring coherence to the input music. Ultimately, we introduce a Group Contrastive Diffusion (GCD) strategy to enhance the connection between dancers and their group, presenting the ability to control the consistency or diversity level of the synthesized group animation via the classifier-guidance sampling technique. Through intensive experiments and evaluation, we demonstrate the effectiveness of our approach in producing visually captivating and consistent group dance motions. The experimental results show the capability of our method to achieve the desired levels of consistency and diversity, while maintaining the overall quality of the generated group choreography. The source code can be found at https://aioz-ai.github.io/GCD
Improved statistical benchmarking of digital pathology models using pairwise frames evaluation
Jun 07, 2023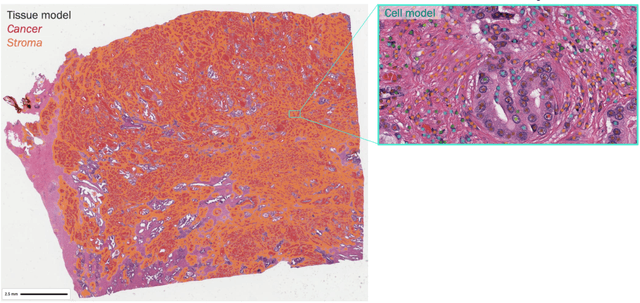
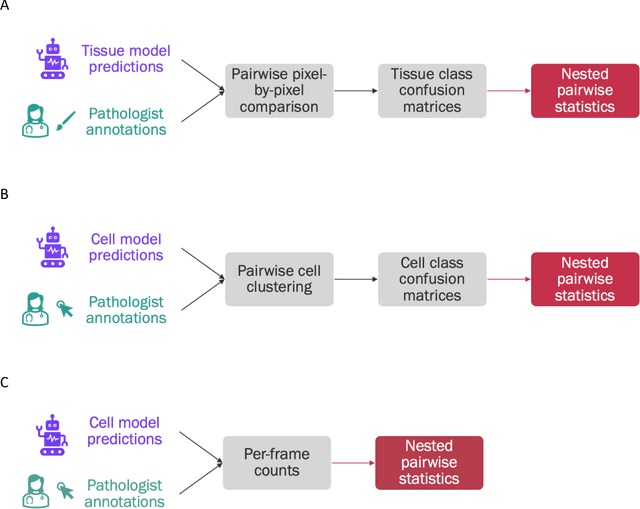
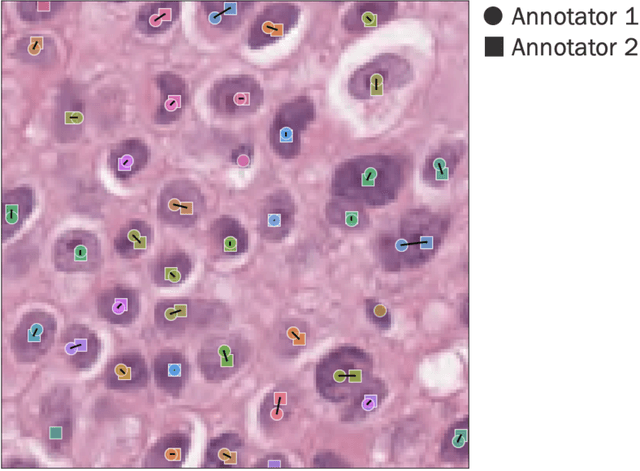
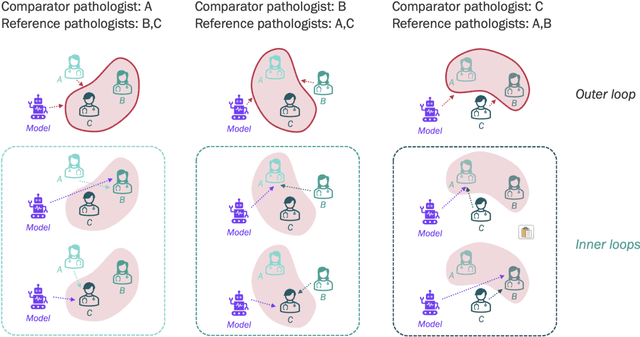
Nested pairwise frames is a method for relative benchmarking of cell or tissue digital pathology models against manual pathologist annotations on a set of sampled patches. At a high level, the method compares agreement between a candidate model and pathologist annotations with agreement among pathologists' annotations. This evaluation framework addresses fundamental issues of data size and annotator variability in using manual pathologist annotations as a source of ground truth for model validation. We implemented nested pairwise frames evaluation for tissue classification, cell classification, and cell count prediction tasks and show results for cell and tissue models deployed on an H&E-stained melanoma dataset.
Music-Driven Group Choreography
Mar 27, 2023



Music-driven choreography is a challenging problem with a wide variety of industrial applications. Recently, many methods have been proposed to synthesize dance motions from music for a single dancer. However, generating dance motion for a group remains an open problem. In this paper, we present $\rm AIOZ-GDANCE$, a new large-scale dataset for music-driven group dance generation. Unlike existing datasets that only support single dance, our new dataset contains group dance videos, hence supporting the study of group choreography. We propose a semi-autonomous labeling method with humans in the loop to obtain the 3D ground truth for our dataset. The proposed dataset consists of 16.7 hours of paired music and 3D motion from in-the-wild videos, covering 7 dance styles and 16 music genres. We show that naively applying single dance generation technique to creating group dance motion may lead to unsatisfactory results, such as inconsistent movements and collisions between dancers. Based on our new dataset, we propose a new method that takes an input music sequence and a set of 3D positions of dancers to efficiently produce multiple group-coherent choreographies. We propose new evaluation metrics for measuring group dance quality and perform intensive experiments to demonstrate the effectiveness of our method. Our project facilitates future research on group dance generation and is available at: https://aioz-ai.github.io/AIOZ-GDANCE/
Style Transfer for 2D Talking Head Animation
Mar 22, 2023



Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
A Quantum Neural Network Regression for Modeling Lithium-ion Battery Capacity Degradation
Feb 06, 2023



Given the high power density low discharge rate and decreasing cost rechargeable lithium-ion batteries LiBs have found a wide range of applications such as power grid level storage systems electric vehicles and mobile devices. Developing a framework to accurately model the nonlinear degradation process of LiBs which is indeed a supervised learning problem becomes an important research topic. This paper presents a classical-quantum hybrid machine learning approach to capture the LiB degradation model that assesses battery cell life loss from operating profiles. Our work is motivated by recent advances in quantum computers as well as the similarity between neural networks and quantum circuits. Similar to adjusting weight parameters in conventional neural networks the parameters of the quantum circuit namely the qubits degree of freedom can be tuned to learn a nonlinear function in a supervised learning fashion. As a proof of concept paper our obtained numerical results with the battery dataset provided by NASA demonstrate the ability of the quantum neural networks in modeling the nonlinear relationship between the degraded capacity and the operating cycles. We also discuss the potential advantage of the quantum approach compared to conventional neural networks in classical computers in dealing with massive data especially in the context of future penetration of EVs and energy storage.
Uncertainty-aware Label Distribution Learning for Facial Expression Recognition
Sep 21, 2022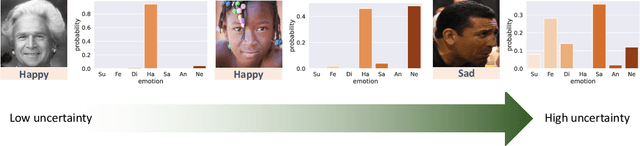
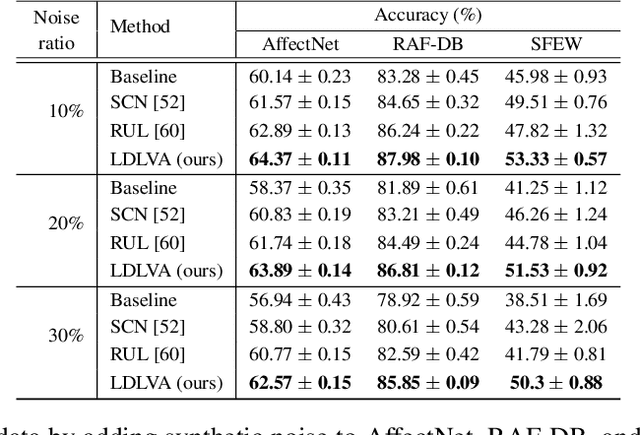
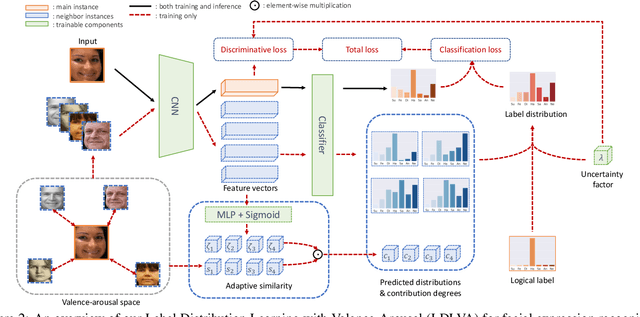
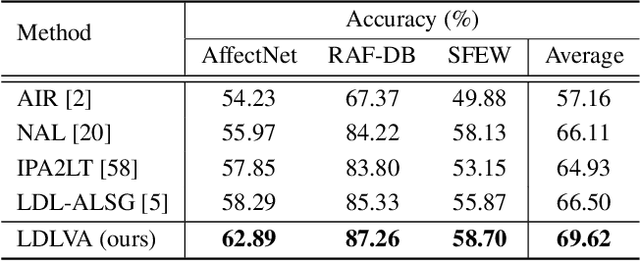
Despite significant progress over the past few years, ambiguity is still a key challenge in Facial Expression Recognition (FER). It can lead to noisy and inconsistent annotation, which hinders the performance of deep learning models in real-world scenarios. In this paper, we propose a new uncertainty-aware label distribution learning method to improve the robustness of deep models against uncertainty and ambiguity. We leverage neighborhood information in the valence-arousal space to adaptively construct emotion distributions for training samples. We also consider the uncertainty of provided labels when incorporating them into the label distributions. Our method can be easily integrated into a deep network to obtain more training supervision and improve recognition accuracy. Intensive experiments on several datasets under various noisy and ambiguous settings show that our method achieves competitive results and outperforms recent state-of-the-art approaches. Our code and models are available at https://github.com/minhnhatvt/label-distribution-learning-fer-tf.
Global-Local Attention for Emotion Recognition
Nov 07, 2021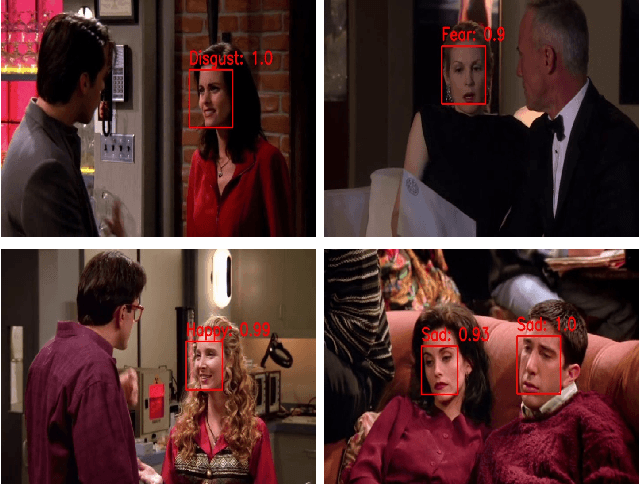
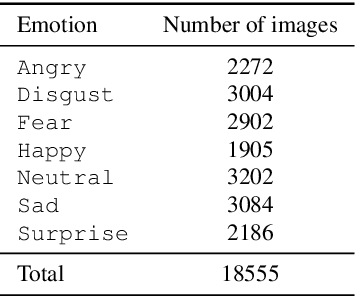
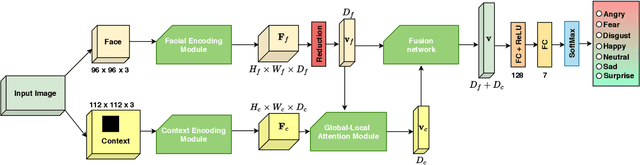

Human emotion recognition is an active research area in artificial intelligence and has made substantial progress over the past few years. Many recent works mainly focus on facial regions to infer human affection, while the surrounding context information is not effectively utilized. In this paper, we proposed a new deep network to effectively recognize human emotions using a novel global-local attention mechanism. Our network is designed to extract features from both facial and context regions independently, then learn them together using the attention module. In this way, both the facial and contextual information is used to infer human emotions, therefore enhancing the discrimination of the classifier. The intensive experiments show that our method surpasses the current state-of-the-art methods on recent emotion datasets by a fair margin. Qualitatively, our global-local attention module can extract more meaningful attention maps than previous methods. The source code and trained model of our network are available at https://github.com/minhnhatvt/glamor-net