 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Visual Explanations to Counterfactual Explanations with Latent Diffusion
Apr 12, 2025



Visual counterfactual explanations are ideal hypothetical images that change the decision-making of the classifier with high confidence toward the desired class while remaining visually plausible and close to the initial image. In this paper, we propose a new approach to tackle two key challenges in recent prominent works: i) determining which specific counterfactual features are crucial for distinguishing the "concept" of the target class from the original class, and ii) supplying valuable explanations for the non-robust classifier without relying on the support of an adversarially robust model. Our method identifies the essential region for modification through algorithms that provide visual explanations, and then our framework generates realistic counterfactual explanations by combining adversarial attacks based on pruning the adversarial gradient of the target classifier and the latent diffusion model. The proposed method outperforms previous state-of-the-art results on various evaluation criteria on ImageNet and CelebA-HQ datasets. In general, our method can be applied to arbitrary classifiers, highlight the strong association between visual and counterfactual explanations, make semantically meaningful changes from the target classifier, and provide observers with subtle counterfactual images.
* 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
TEAM: Topological Evolution-aware Framework for Traffic Forecasting--Extended Version
Oct 24, 2024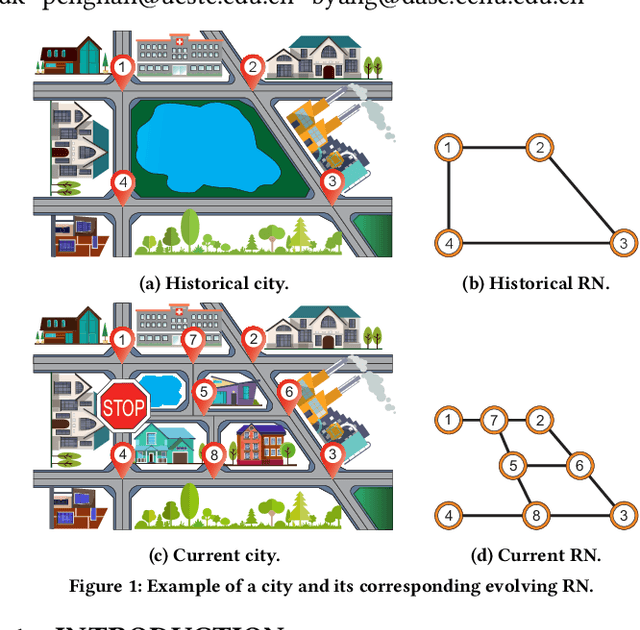
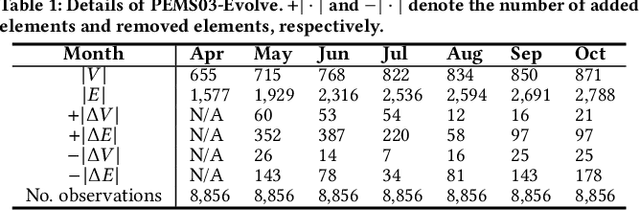
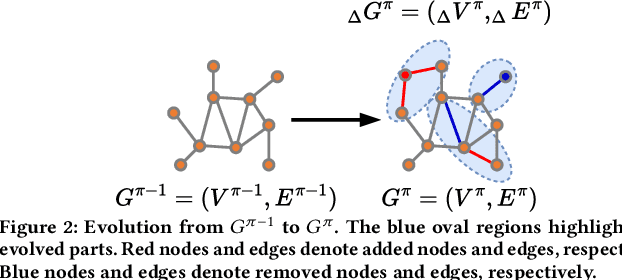
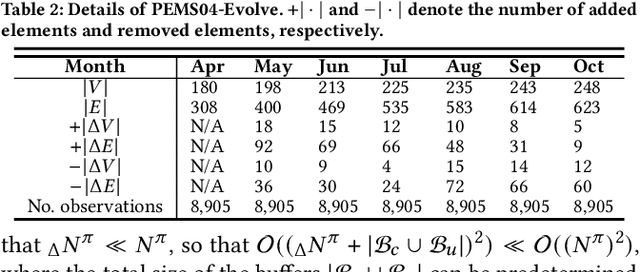
Due to the global trend towards urbanization, people increasingly move to and live in cities that then continue to grow. Traffic forecasting plays an important role in the intelligent transportation systems of cities as well as in spatio-temporal data mining. State-of-the-art forecasting is achieved by deep-learning approaches due to their ability to contend with complex spatio-temporal dynamics. However, existing methods assume the input is fixed-topology road networks and static traffic time series. These assumptions fail to align with urbanization, where time series are collected continuously and road networks evolve over time. In such settings, deep-learning models require frequent re-initialization and re-training, imposing high computational costs. To enable much more efficient training without jeopardizing model accuracy, we propose the Topological Evolution-aware Framework (TEAM) for traffic forecasting that incorporates convolution and attention. This combination of mechanisms enables better adaptation to newly collected time series, while being able to maintain learned knowledge from old time series. TEAM features a continual learning module based on the Wasserstein metric that acts as a buffer that can identify the most stable and the most changing network nodes. Then, only data related to stable nodes is employed for re-training when consolidating a model. Further, only data of new nodes and their adjacent nodes as well as data pertaining to changing nodes are used to re-train the model. Empirical studies with two real-world traffic datasets offer evidence that TEAM is capable of much lower re-training costs than existing methods are, without jeopardizing forecasting accuracy.
Language-Conditioned Affordance-Pose Detection in 3D Point Clouds
Sep 19, 2023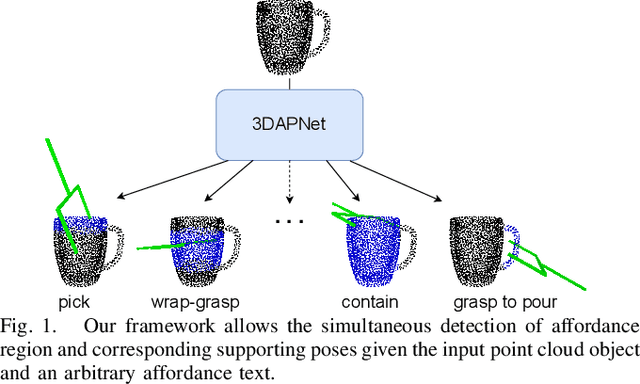

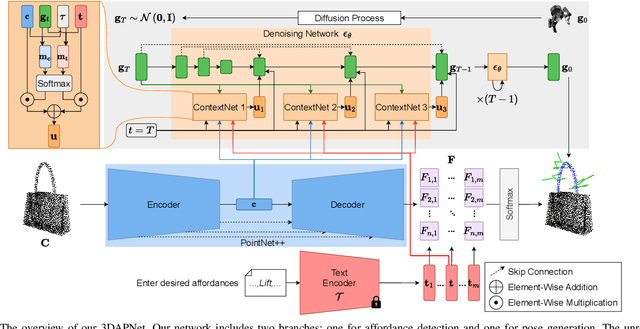
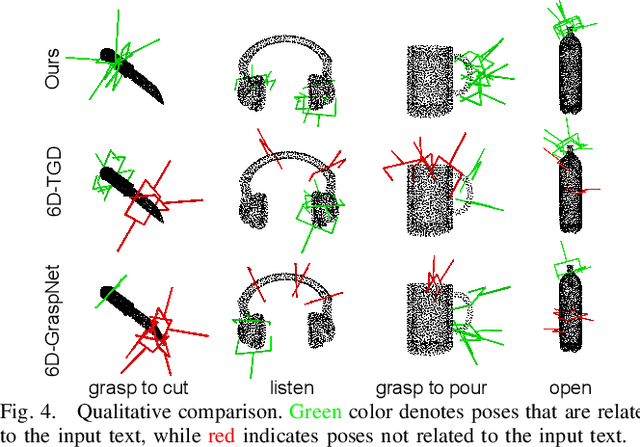
Affordance detection and pose estimation are of great importance in many robotic applications. Their combination helps the robot gain an enhanced manipulation capability, in which the generated pose can facilitate the corresponding affordance task. Previous methods for affodance-pose joint learning are limited to a predefined set of affordances, thus limiting the adaptability of robots in real-world environments. In this paper, we propose a new method for language-conditioned affordance-pose joint learning in 3D point clouds. Given a 3D point cloud object, our method detects the affordance region and generates appropriate 6-DoF poses for any unconstrained affordance label. Our method consists of an open-vocabulary affordance detection branch and a language-guided diffusion model that generates 6-DoF poses based on the affordance text. We also introduce a new high-quality dataset for the task of language-driven affordance-pose joint learning. Intensive experimental results demonstrate that our proposed method works effectively on a wide range of open-vocabulary affordances and outperforms other baselines by a large margin. In addition, we illustrate the usefulness of our method in real-world robotic applications. Our code and dataset are publicly available at https://3DAPNet.github.io
Uncertainty-aware Label Distribution Learning for Facial Expression Recognition
Sep 21, 2022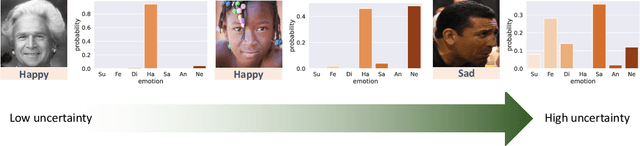
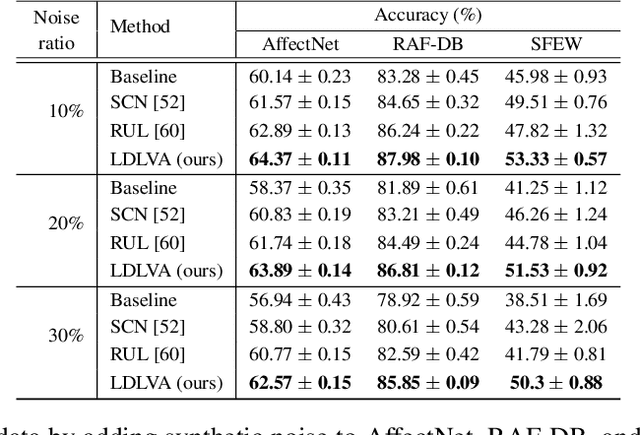
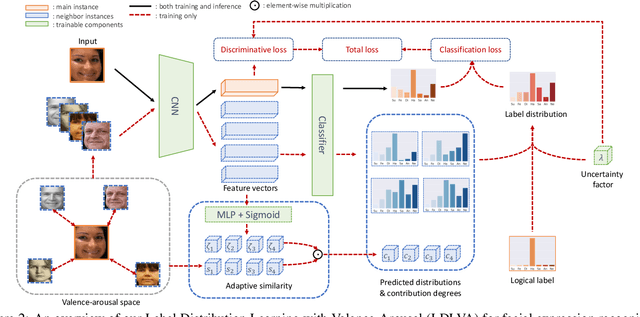
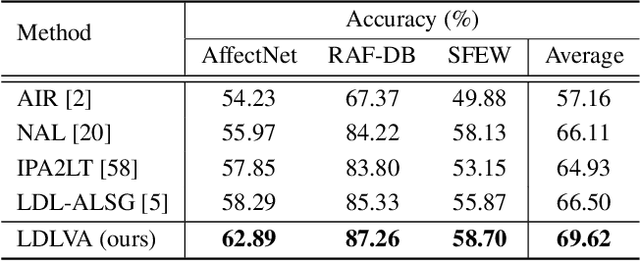
Despite significant progress over the past few years, ambiguity is still a key challenge in Facial Expression Recognition (FER). It can lead to noisy and inconsistent annotation, which hinders the performance of deep learning models in real-world scenarios. In this paper, we propose a new uncertainty-aware label distribution learning method to improve the robustness of deep models against uncertainty and ambiguity. We leverage neighborhood information in the valence-arousal space to adaptively construct emotion distributions for training samples. We also consider the uncertainty of provided labels when incorporating them into the label distributions. Our method can be easily integrated into a deep network to obtain more training supervision and improve recognition accuracy. Intensive experiments on several datasets under various noisy and ambiguous settings show that our method achieves competitive results and outperforms recent state-of-the-art approaches. Our code and models are available at https://github.com/minhnhatvt/label-distribution-learning-fer-tf.
Global-Local Attention for Emotion Recognition
Nov 07, 2021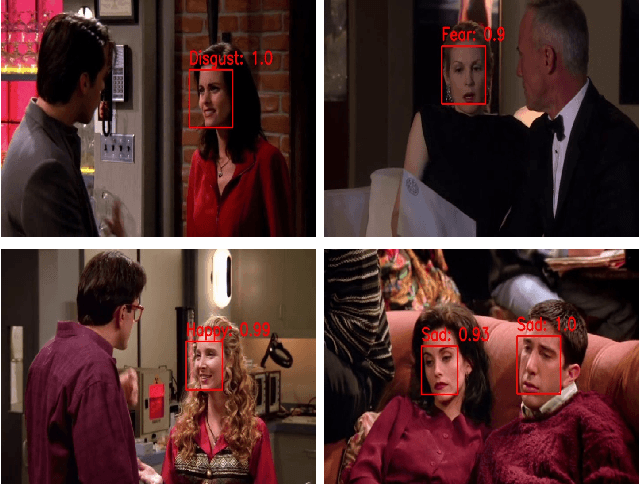
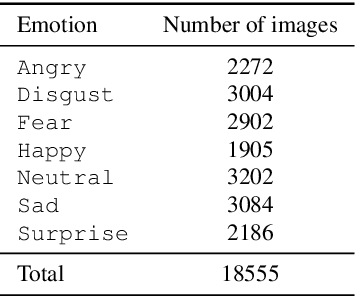
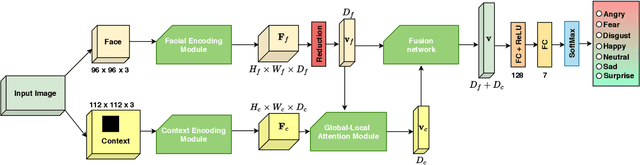

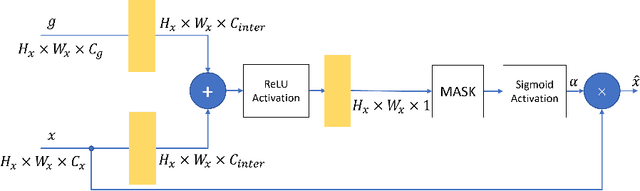
Human emotion recognition is an active research area in artificial intelligence and has made substantial progress over the past few years. Many recent works mainly focus on facial regions to infer human affection, while the surrounding context information is not effectively utilized. In this paper, we proposed a new deep network to effectively recognize human emotions using a novel global-local attention mechanism. Our network is designed to extract features from both facial and context regions independently, then learn them together using the attention module. In this way, both the facial and contextual information is used to infer human emotions, therefore enhancing the discrimination of the classifier. The intensive experiments show that our method surpasses the current state-of-the-art methods on recent emotion datasets by a fair margin. Qualitatively, our global-local attention module can extract more meaningful attention maps than previous methods. The source code and trained model of our network are available at https://github.com/minhnhatvt/glamor-net
Attention Gate in Traffic Forecasting
Sep 27, 2021


Because of increased urban complexity and growing populations, more and more challenges about predicting city-wide mobility behavior are being organized. Traffic Map Movie Forecasting Challenge 2020 is secondly held in the competition track of the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS). Similar to Traffic4Cast 2019, the task is to predict traffic flow volume, average speed in major directions on the geographical area of three big cities: Berlin, Istanbul, and Moscow. In this paper, we apply the attention mechanism on U-Net based model, especially we add an attention gate on the skip-connection between contraction path and expansion path. An attention gates filter features from the contraction path before combining with features on the expansion path, it enables our model to reduce the effect of non-traffic region features and focus more on crucial region features. In addition to the competition data, we also propose two extra features which often affect traffic flow, that are time and weekdays. We experiment with our model on the competition dataset and reproduce the winner solution in the same environment. Overall, our model archives better performance than recent methods.
Semi-Supervised Adversarial Discriminative Domain Adaptation
Sep 27, 2021


Domain adaptation is a potential method to train a powerful deep neural network, which can handle the absence of labeled data. More precisely, domain adaptation solving the limitation called dataset bias or domain shift when the training dataset and testing dataset are extremely different. Adversarial adaptation method becoming popular among other domain adaptation methods. Relies on the idea of GAN, adversarial domain adaptation tries to minimize the distribution between training and testing datasets base on the adversarial object. However, some conventional adversarial domain adaptation methods cannot handle large domain shifts between two datasets or the generalization ability of these methods are inefficient. In this paper, we propose an improved adversarial domain adaptation method called Semi-Supervised Adversarial Discriminative Domain Adaptation (SADDA), which can overcome the limitation of other domain adaptation. We also show that SADDA has better performance than other adversarial adaptation methods and illustrate the promise of our method on digit classification and emotion recognition problems.