 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboDesign1M: A Large-scale Dataset for Robot Design Understanding
Mar 09, 2025Robot design is a complex and time-consuming process that requires specialized expertise. Gaining a deeper understanding of robot design data can enable various applications, including automated design generation, retrieving example designs from text, and developing AI-powered design assistants. While recent advancements in foundation models present promising approaches to addressing these challenges, progress in this field is hindered by the lack of large-scale design datasets. In this paper, we introduce RoboDesign1M, a large-scale dataset comprising 1 million samples. Our dataset features multimodal data collected from scientific literature, covering various robotics domains. We propose a semi-automated data collection pipeline, enabling efficient and diverse data acquisition. To assess the effectiveness of RoboDesign1M, we conduct extensive experiments across multiple tasks, including design image generation, visual question answering about designs, and design image retrieval. The results demonstrate that our dataset serves as a challenging new benchmark for design understanding tasks and has the potential to advance research in this field. RoboDesign1M will be released to support further developments in AI-driven robotic design automation.
Guide3D: A Bi-planar X-ray Dataset for 3D Shape Reconstruction
Oct 29, 2024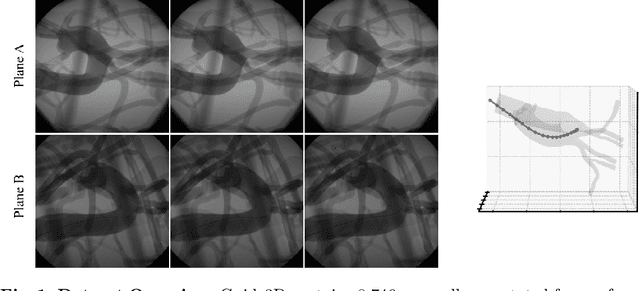
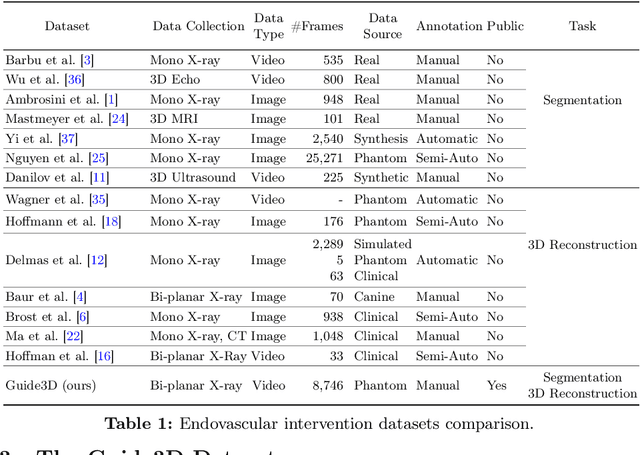

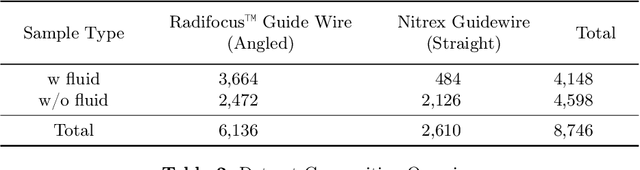
Endovascular surgical tool reconstruction represents an important factor in advancing endovascular tool navigation, which is an important step in endovascular surgery. However, the lack of publicly available datasets significantly restricts the development and validation of novel machine learning approaches. Moreover, due to the need for specialized equipment such as biplanar scanners, most of the previous research employs monoplanar fluoroscopic technologies, hence only capturing the data from a single view and significantly limiting the reconstruction accuracy. To bridge this gap, we introduce Guide3D, a bi-planar X-ray dataset for 3D reconstruction. The dataset represents a collection of high resolution bi-planar, manually annotated fluoroscopic videos, captured in real-world settings. Validating our dataset within a simulated environment reflective of clinical settings confirms its applicability for real-world applications. Furthermore, we propose a new benchmark for guidewrite shape prediction, serving as a strong baseline for future work. Guide3D not only addresses an essential need by offering a platform for advancing segmentation and 3D reconstruction techniques but also aids the development of more accurate and efficient endovascular surgery interventions. Our project is available at https://airvlab.github.io/guide3d/.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
Predicting Agricultural Commodities Prices with Machine Learning: A Review of Current Research
Oct 28, 2023



Agricultural price prediction is crucial for farmers, policymakers, and other stakeholders in the agricultural sector. However, it is a challenging task due to the complex and dynamic nature of agricultural markets. Machine learning algorithms have the potential to revolutionize agricultural price prediction by improving accuracy, real-time prediction, customization, and integration. This paper reviews recent research on machine learning algorithms for agricultural price prediction. We discuss the importance of agriculture in developing countries and the problems associated with crop price falls. We then identify the challenges of predicting agricultural prices and highlight how machine learning algorithms can support better prediction. Next, we present a comprehensive analysis of recent research, discussing the strengths and weaknesses of various machine learning techniques. We conclude that machine learning has the potential to revolutionize agricultural price prediction, but further research is essential to address the limitations and challenges associated with this approach.
Uncertainty-aware Label Distribution Learning for Facial Expression Recognition
Sep 21, 2022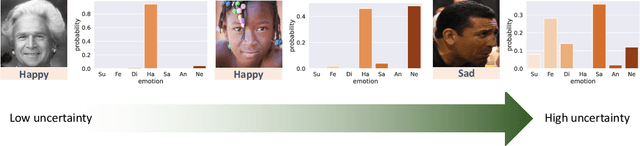
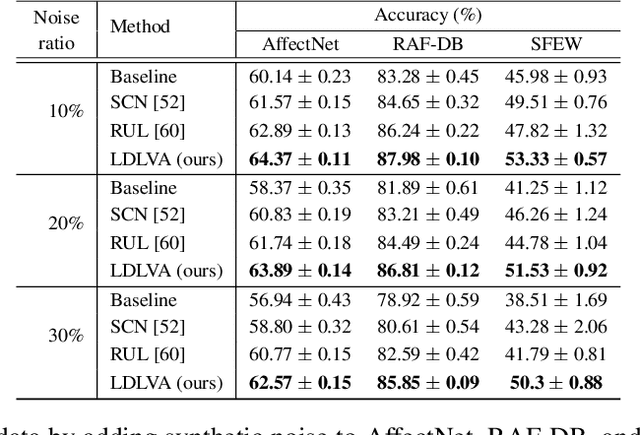
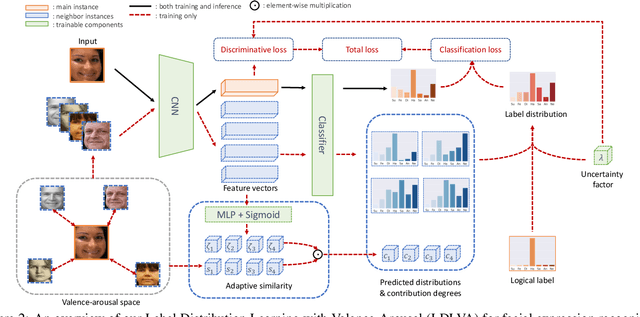
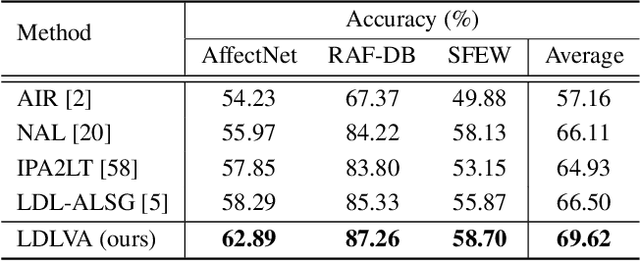
Despite significant progress over the past few years, ambiguity is still a key challenge in Facial Expression Recognition (FER). It can lead to noisy and inconsistent annotation, which hinders the performance of deep learning models in real-world scenarios. In this paper, we propose a new uncertainty-aware label distribution learning method to improve the robustness of deep models against uncertainty and ambiguity. We leverage neighborhood information in the valence-arousal space to adaptively construct emotion distributions for training samples. We also consider the uncertainty of provided labels when incorporating them into the label distributions. Our method can be easily integrated into a deep network to obtain more training supervision and improve recognition accuracy. Intensive experiments on several datasets under various noisy and ambiguous settings show that our method achieves competitive results and outperforms recent state-of-the-art approaches. Our code and models are available at https://github.com/minhnhatvt/label-distribution-learning-fer-tf.
Multigraph Topology Design for Cross-Silo Federated Learning
Jul 21, 2022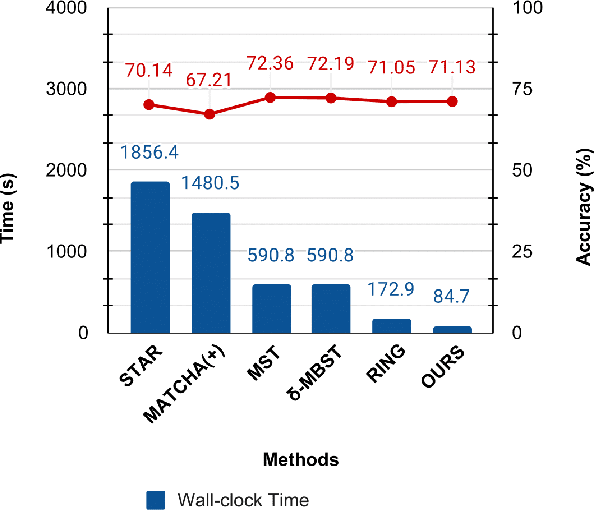
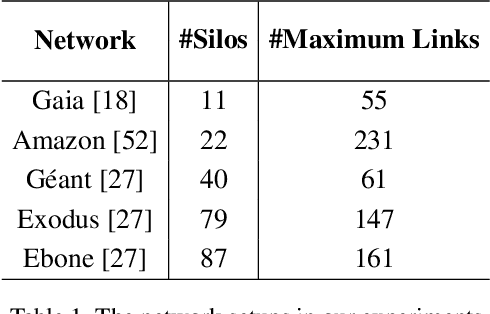
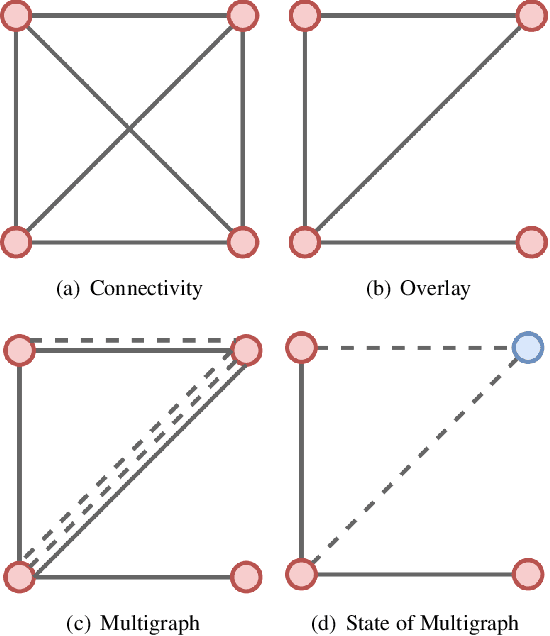
Cross-silo federated learning utilizes a few hundred reliable data silos with high-speed access links to jointly train a model. While this approach becomes a popular setting in federated learning, designing a robust topology to reduce the training time is still an open problem. In this paper, we present a new multigraph topology for cross-silo federated learning. We first construct the multigraph using the overlay graph. We then parse this multigraph into different simple graphs with isolated nodes. The existence of isolated nodes allows us to perform model aggregation without waiting for other nodes, hence reducing the training time. We further propose a new distributed learning algorithm to use with our multigraph topology. The intensive experiments on public datasets show that our proposed method significantly reduces the training time compared with recent state-of-the-art topologies while ensuring convergence and maintaining the model's accuracy.
Autonomous Navigation with Mobile Robots using Deep Learning and the Robot Operating System
Dec 07, 2020
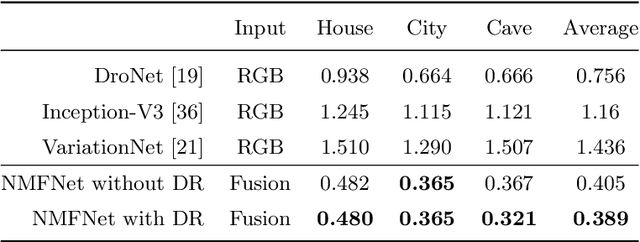


Autonomous navigation is a long-standing field of robotics research, which provides an essential capability for mobile robots to execute a series of tasks on the same environments performed by human everyday. In this chapter, we present a set of algorithms to train and deploy deep networks for autonomous navigation of mobile robots using the Robot Operation System (ROS). We describe three main steps to tackle this problem: i) collecting data in simulation environments using ROS and Gazebo; ii) designing deep network for autonomous navigation, and iii) deploying the learned policy on mobile robots in both simulation and real-world. Theoretically, we present deep learning architectures for robust navigation in normal environments (e.g., man-made houses, roads) and complex environments (e.g., collapsed cities, or natural caves). We further show that the use of visual modalities such as RGB, Lidar, and point cloud is essential to improve the autonomy of mobile robots. Our project website and demonstration video can be found at https://sites.google.com/site/autonomousnavigationros.
Automatic joint damage quantification using computer vision and deep learning
Oct 29, 2020
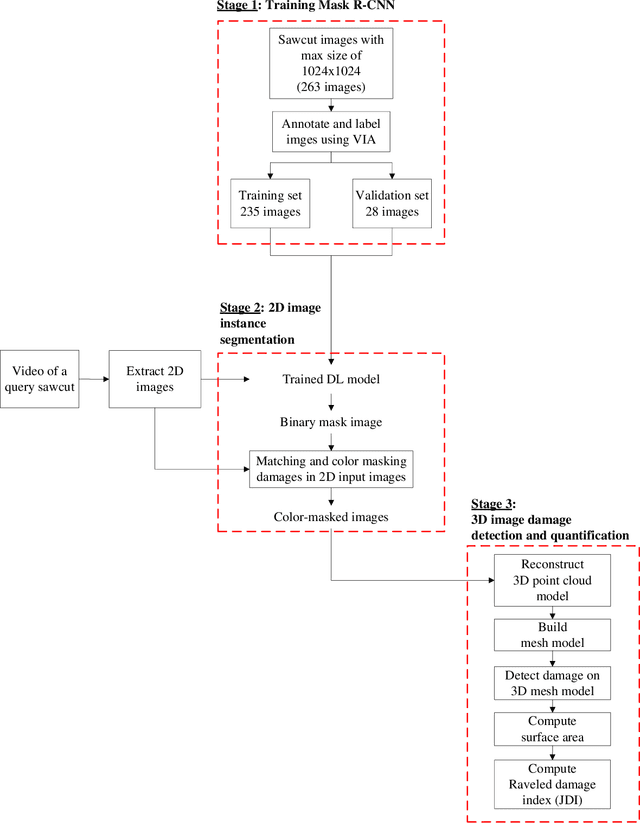
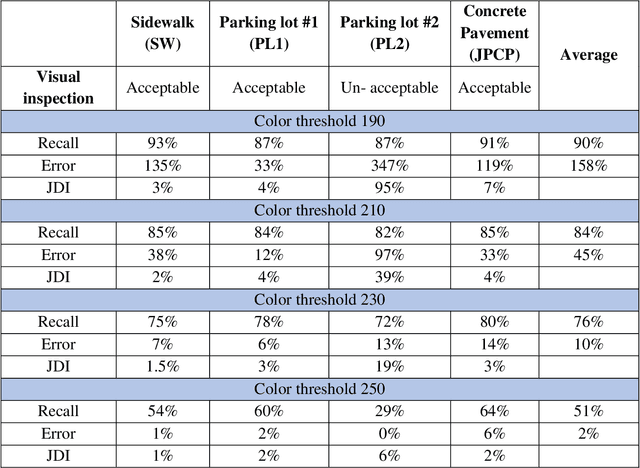
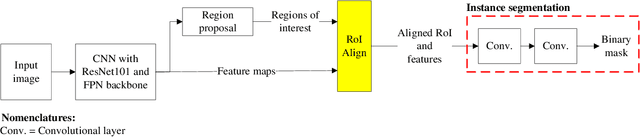
Joint raveled or spalled damage (henceforth called joint damage) can affect the safety and long-term performance of concrete pavements. It is important to assess and quantify the joint damage over time to assist in building action plans for maintenance, predicting maintenance costs, and maximize the concrete pavement service life. A framework for the accurate, autonomous, and rapid quantification of joint damage with a low-cost camera is proposed using a computer vision technique with a deep learning (DL) algorithm. The DL model is employed to train 263 images of sawcuts with joint damage. The trained DL model is used for pixel-wise color-masking joint damage in a series of query 2D images, which are used to reconstruct a 3D image using open-source structure from motion algorithm. Another damage quantification algorithm using a color threshold is applied to detect and compute the surface area of the damage in the 3D reconstructed image. The effectiveness of the framework was validated through inspecting joint damage at four transverse contraction joints in Illinois, USA, including three acceptable joints and one unacceptable joint by visual inspection. The results show the framework achieves 76% recall and 10% error.