 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOGO: Forgetting-aware Orthogonalization Optimizer
Jun 09, 2026We argue that forgetting is not confined to continual learning but is a general optimization phenomenon: during standard training, dominant mini-batch gradients suppress rare but useful update directions, causing short-term forgetting at every step. When such knowledge is never revisited, these losses compound into long-term forgetting-the classical failure mode of continual learning. We introduce FOGO, a scalable optimizer that continuously detects and resolves gradient interference across both regimes. FOGO spectrally orthogonalizes momentum updates to prevent dominant directions from monopolizing optimization, then stores representative past directions in a compact codebook memory built on random projection, where pairwise distances are provably preserved in low-dimensional space. At each step, conflicts between the current update and stored directions are resolved via lightweight orthogonal correction and lifted back through a proximal step, with minimal overhead and no data storage. Across class-imbalanced classification, continual visual learning under domain and class shifts, continual fine-tuning of LLaVA-7B, and GPT-2 pretraining, FOGO consistently improves convergence and knowledge retention, outperforming Adam and Muon.
ByteRover: Agent-Native Memory Through LLM-Curated Hierarchical Context
Apr 02, 2026Memory-Augmented Generation (MAG) extends large language models with external memory to support long-context reasoning, but existing approaches universally treat memory as an external service that agents call into, delegating storage to separate pipelines of chunking, embedding, and graph extraction. This architectural separation means the system that stores knowledge does not understand it, leading to semantic drift between what the agent intended to remember and what the pipeline actually captured, loss of coordination context across agents, and fragile recovery after failures. In this paper, we propose ByteRover, an agent-native memory architecture that inverts the memory pipeline: the same LLM that reasons about a task also curates, structures, and retrieves knowledge. ByteRover represents knowledge in a hierarchical Context Tree, a file-based knowledge graph organized as Domain, Topic, Subtopic, and Entry, where each entry carries explicit relations, provenance, and an Adaptive Knowledge Lifecycle (AKL) with importance scoring, maturity tiers, and recency decay. Retrieval uses a 5-tier progressive strategy that resolves most queries at sub-100 ms latency without LLM calls, escalating to agentic reasoning only for novel questions. Experiments on LoCoMo and LongMemEval demonstrate that ByteRover achieves state-of-the-art accuracy on LoCoMo and competitive results on LongMemEval while requiring zero external infrastructure, no vector database, no graph database, no embedding service, with all knowledge stored as human-readable markdown files on the local filesystem.
Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
RoboDesign1M: A Large-scale Dataset for Robot Design Understanding
Mar 09, 2025Robot design is a complex and time-consuming process that requires specialized expertise. Gaining a deeper understanding of robot design data can enable various applications, including automated design generation, retrieving example designs from text, and developing AI-powered design assistants. While recent advancements in foundation models present promising approaches to addressing these challenges, progress in this field is hindered by the lack of large-scale design datasets. In this paper, we introduce RoboDesign1M, a large-scale dataset comprising 1 million samples. Our dataset features multimodal data collected from scientific literature, covering various robotics domains. We propose a semi-automated data collection pipeline, enabling efficient and diverse data acquisition. To assess the effectiveness of RoboDesign1M, we conduct extensive experiments across multiple tasks, including design image generation, visual question answering about designs, and design image retrieval. The results demonstrate that our dataset serves as a challenging new benchmark for design understanding tasks and has the potential to advance research in this field. RoboDesign1M will be released to support further developments in AI-driven robotic design automation.
h-Edit: Effective and Flexible Diffusion-Based Editing via Doob's h-Transform
Mar 04, 2025We introduce a theoretical framework for diffusion-based image editing by formulating it as a reverse-time bridge modeling problem. This approach modifies the backward process of a pretrained diffusion model to construct a bridge that converges to an implicit distribution associated with the editing target at time 0. Building on this framework, we propose h-Edit, a novel editing method that utilizes Doob's h-transform and Langevin Monte Carlo to decompose the update of an intermediate edited sample into two components: a "reconstruction" term and an "editing" term. This decomposition provides flexibility, allowing the reconstruction term to be computed via existing inversion techniques and enabling the combination of multiple editing terms to handle complex editing tasks. To our knowledge, h-Edit is the first training-free method capable of performing simultaneous text-guided and reward-model-based editing. Extensive experiments, both quantitative and qualitative, show that h-Edit outperforms state-of-the-art baselines in terms of editing effectiveness and faithfulness. Our source code is available at https://github.com/nktoan/h-edit.
Deep-Wide Learning Assistance for Insect Pest Classification
Sep 16, 2024


Accurate insect pest recognition plays a critical role in agriculture. It is a challenging problem due to the intricate characteristics of insects. In this paper, we present DeWi, novel learning assistance for insect pest classification. With a one-stage and alternating training strategy, DeWi simultaneously improves several Convolutional Neural Networks in two perspectives: discrimination (by optimizing a triplet margin loss in a supervised training manner) and generalization (via data augmentation). From that, DeWi can learn discriminative and in-depth features of insect pests (deep) yet still generalize well to a large number of insect categories (wide). Experimental results show that DeWi achieves the highest performances on two insect pest classification benchmarks (76.44\% accuracy on the IP102 dataset and 99.79\% accuracy on the D0 dataset, respectively). In addition, extensive evaluations and ablation studies are conducted to thoroughly investigate our DeWi and demonstrate its superiority. Our source code is available at https://github.com/toannguyen1904/DeWi.
Language-Driven 6-DoF Grasp Detection Using Negative Prompt Guidance
Jul 18, 2024



6-DoF grasp detection has been a fundamental and challenging problem in robotic vision. While previous works have focused on ensuring grasp stability, they often do not consider human intention conveyed through natural language, hindering effective collaboration between robots and users in complex 3D environments. In this paper, we present a new approach for language-driven 6-DoF grasp detection in cluttered point clouds. We first introduce Grasp-Anything-6D, a large-scale dataset for the language-driven 6-DoF grasp detection task with 1M point cloud scenes and more than 200M language-associated 3D grasp poses. We further introduce a novel diffusion model that incorporates a new negative prompt guidance learning strategy. The proposed negative prompt strategy directs the detection process toward the desired object while steering away from unwanted ones given the language input. Our method enables an end-to-end framework where humans can command the robot to grasp desired objects in a cluttered scene using natural language. Intensive experimental results show the effectiveness of our method in both benchmarking experiments and real-world scenarios, surpassing other baselines. In addition, we demonstrate the practicality of our approach in real-world robotic applications. Our project is available at https://airvlab.github.io/grasp-anything.
Crossing Linguistic Horizons: Finetuning and Comprehensive Evaluation of Vietnamese Large Language Models
Mar 05, 2024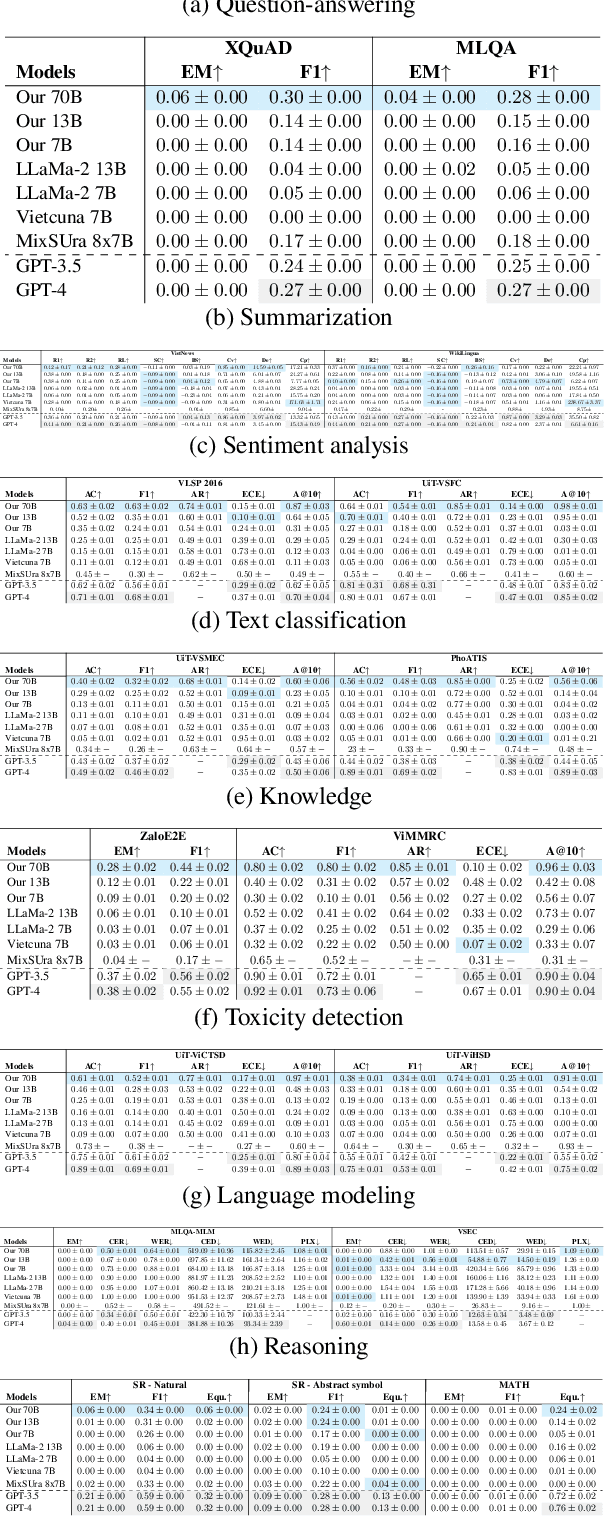
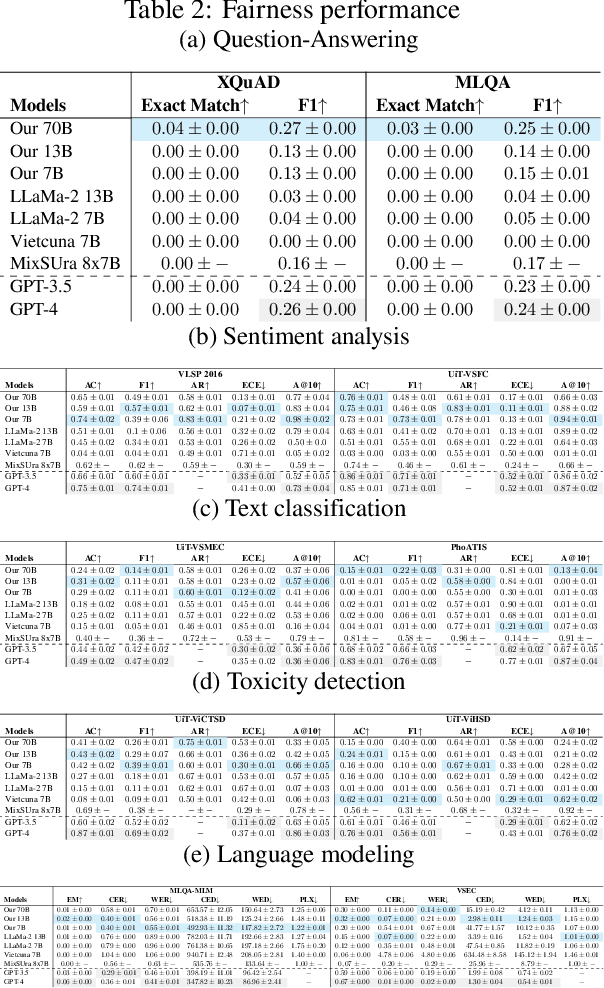
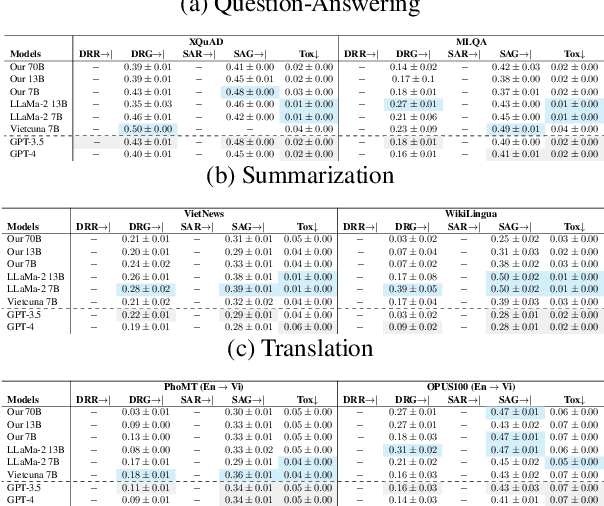
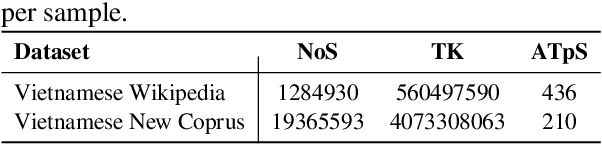
Recent advancements in large language models (LLMs) have underscored their importance in the evolution of artificial intelligence. However, despite extensive pretraining on multilingual datasets, available open-sourced LLMs exhibit limited effectiveness in processing Vietnamese. The challenge is exacerbated by the absence of systematic benchmark datasets and metrics tailored for Vietnamese LLM evaluation. To mitigate these issues, we have finetuned LLMs specifically for Vietnamese and developed a comprehensive evaluation framework encompassing 10 common tasks and 31 metrics. Our evaluation results reveal that the fine-tuned LLMs exhibit enhanced comprehension and generative capabilities in Vietnamese. Moreover, our analysis indicates that models with more parameters can introduce more biases and uncalibrated outputs and the key factor influencing LLM performance is the quality of the training or fine-tuning datasets. These insights underscore the significance of meticulous fine-tuning with high-quality datasets in enhancing LLM performance.
Variational Flow Models: Flowing in Your Style
Feb 05, 2024



We introduce a variational inference interpretation for models of "posterior flows" - generalizations of "probability flows" to a broader class of stochastic processes not necessarily diffusion processes. We coin the resulting models as "Variational Flow Models". Additionally, we propose a systematic training-free method to transform the posterior flow of a "linear" stochastic process characterized by the equation Xt = at * X0 + st * X1 into a straight constant-speed (SC) flow, reminiscent of Rectified Flow. This transformation facilitates fast sampling along the original posterior flow without training a new model of the SC flow. The flexibility of our approach allows us to extend our transformation to inter-convert two posterior flows from distinct "linear" stochastic processes. Moreover, we can easily integrate high-order numerical solvers into the transformed SC flow, further enhancing sampling accuracy and efficiency. Rigorous theoretical analysis and extensive experimental results substantiate the advantages of our framework.