 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Context Alignment and Answer-Context Dependencies for Effective Answer Sentence Selection
Jun 03, 2023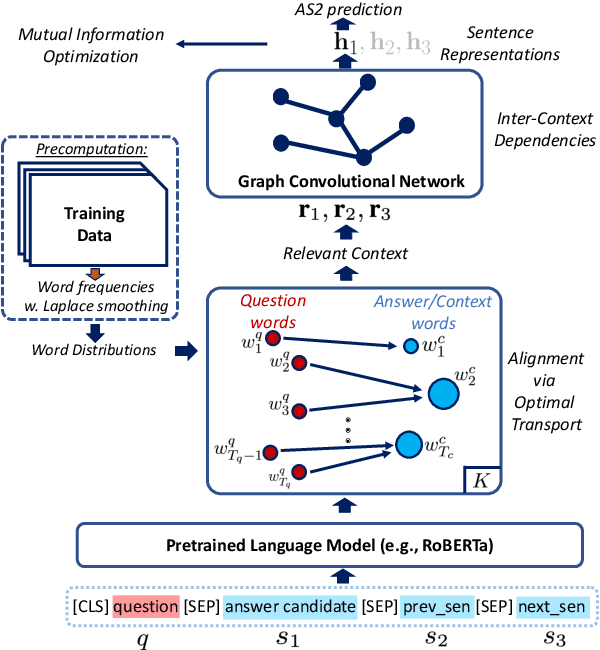
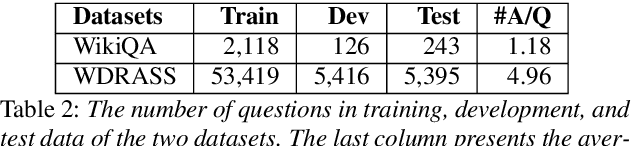
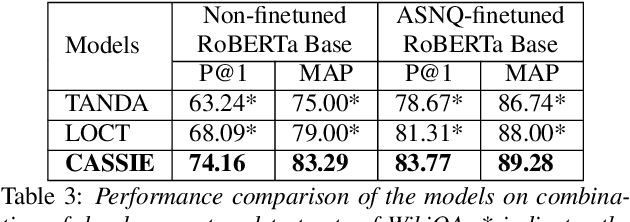
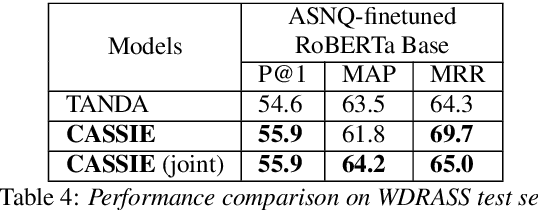
Answer sentence selection (AS2) in open-domain question answering finds answer for a question by ranking candidate sentences extracted from web documents. Recent work exploits answer context, i.e., sentences around a candidate, by incorporating them as additional input string to the Transformer models to improve the correctness scoring. In this paper, we propose to improve the candidate scoring by explicitly incorporating the dependencies between question-context and answer-context into the final representation of a candidate. Specifically, we use Optimal Transport to compute the question-based dependencies among sentences in the passage where the answer is extracted from. We then represent these dependencies as edges in a graph and use Graph Convolutional Network to derive the representation of a candidate, a node in the graph. Our proposed model achieves significant improvements on popular AS2 benchmarks, i.e., WikiQA and WDRASS, obtaining new state-of-the-art on all benchmarks.
DP-KB: Data Programming with Knowledge Bases Improves Transformer Fine Tuning for Answer Sentence Selection
Mar 17, 2022
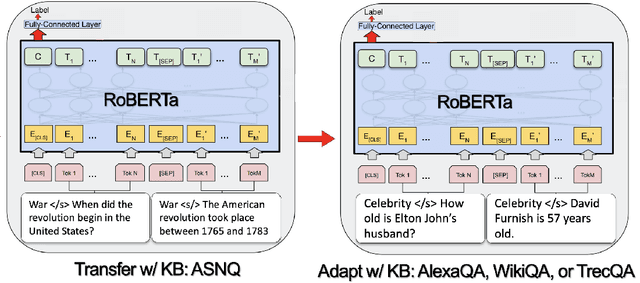
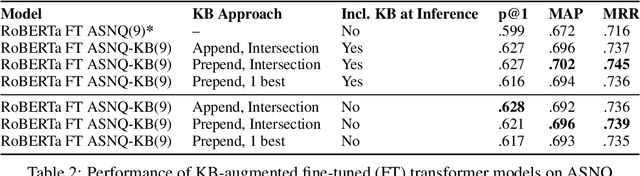
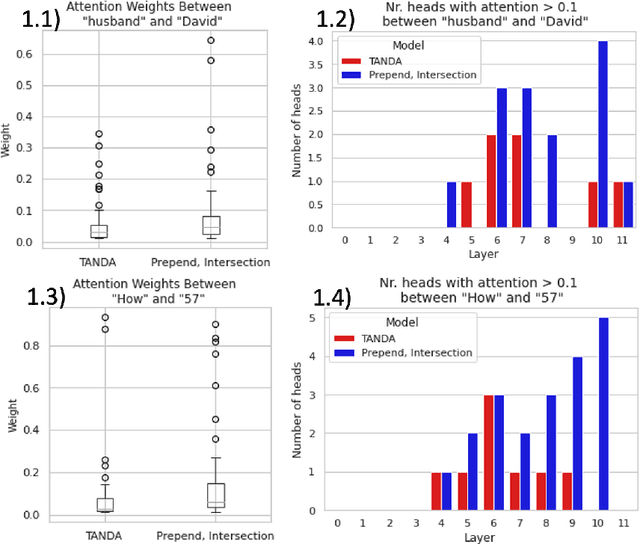
While transformers demonstrate impressive performance on many knowledge intensive (KI) tasks, their ability to serve as implicit knowledge bases (KBs) remains limited, as shown on several slot-filling, question-answering (QA), fact verification, and entity-linking tasks. In this paper, we implement an efficient, data-programming technique that enriches training data with KB-derived context and improves transformer utilization of encoded knowledge when fine-tuning for a particular QA task, namely answer sentence selection (AS2). Our method outperforms state of the art transformer approach on WikiQA and TrecQA, two widely studied AS2 benchmarks, increasing by 2.0% p@1, 1.3% MAP, 1.1% MRR, and 4.4% p@1, 0.9% MAP, 2.4% MRR, respectively. To demonstrate our improvements in an industry setting, we additionally evaluate our approach on a proprietary dataset of Alexa QA pairs, and show increase of 2.3% F1 and 2.0% MAP. We additionally find that these improvements remain even when KB context is omitted at inference time, allowing for the use of our models within existing transformer workflows without additional latency or deployment costs.
Question-Answer Sentence Graph for Joint Modeling Answer Selection
Feb 16, 2022
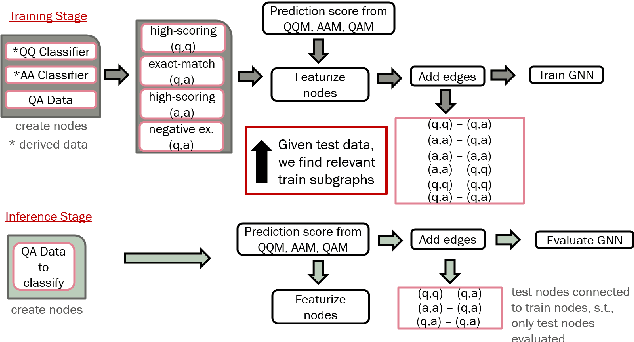
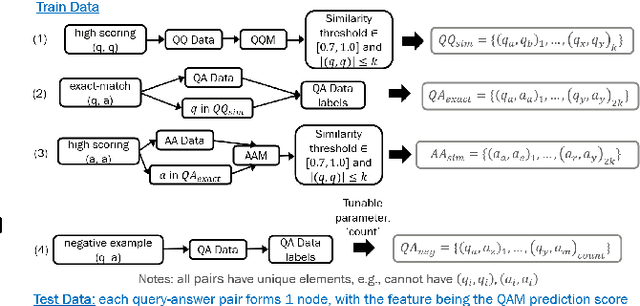
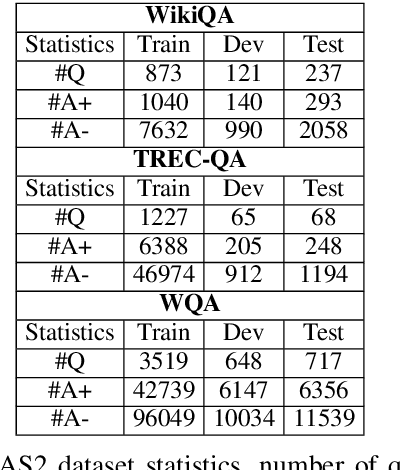
This research studies graph-based approaches for Answer Sentence Selection (AS2), an essential component for building retrieval-based Question Answering systems. Given a question, our model creates a small-scale relevant training graph to perform more accurate AS2. The nodes of the graphs are question-answer pairs, where the answers are also sentences. We train and apply state-of-the-art models for computing scores between question-question, question-answer, and answer-answer pairs. We apply thresholding to the relevance scores for creating edges between nodes. Finally, we apply Graph Neural Networks to the obtained graph to perform joint learning and inference for solving the AS2 task. The experiments on two well-known academic benchmarks and a real-world dataset show that our approach consistently outperforms state-of-the-art models.
In Situ Answer Sentence Selection at Web-scale
Jan 16, 2022



Current answer sentence selection (AS2) applied in open-domain question answering (ODQA) selects answers by ranking a large set of possible candidates, i.e., sentences, extracted from the retrieved text. In this paper, we present Passage-based Extracting Answer Sentence In-place (PEASI), a novel design for AS2 optimized for Web-scale setting, that, instead, computes such answer without processing each candidate individually. Specifically, we design a Transformer-based framework that jointly (i) reranks passages retrieved for a question and (ii) identifies a probable answer from the top passages in place. We train PEASI in a multi-task learning framework that encourages feature sharing between the components: passage reranker and passage-based answer sentence extractor. To facilitate our development, we construct a new Web-sourced large-scale QA dataset consisting of 800,000+ labeled passages/sentences for 60,000+ questions. The experiments show that our proposed design effectively outperforms the current state-of-the-art setting for AS2, i.e., a point-wise model for ranking sentences independently, by 6.51% in accuracy, from 48.86% to 55.37%. In addition, PEASI is exceptionally efficient in computing answer sentences, requiring only ~20% inferences compared to the standard setting, i.e., reranking all possible candidates. We believe the release of PEASI, both the dataset and our proposed design, can contribute to advancing the research and development in deploying question answering services at Web scale.
Double Retrieval and Ranking for Accurate Question Answering
Jan 16, 2022
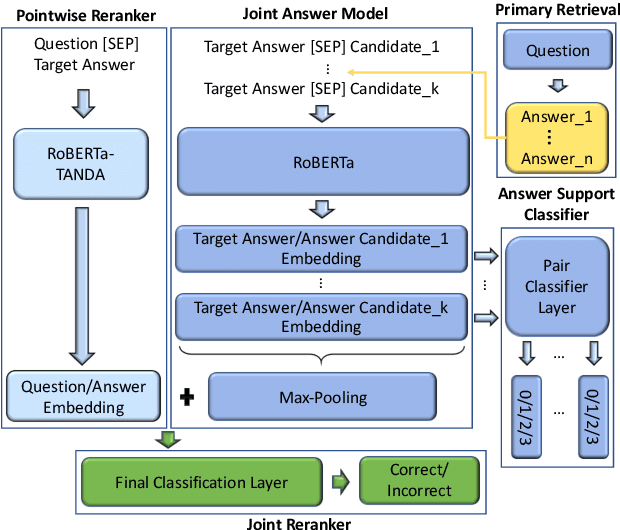
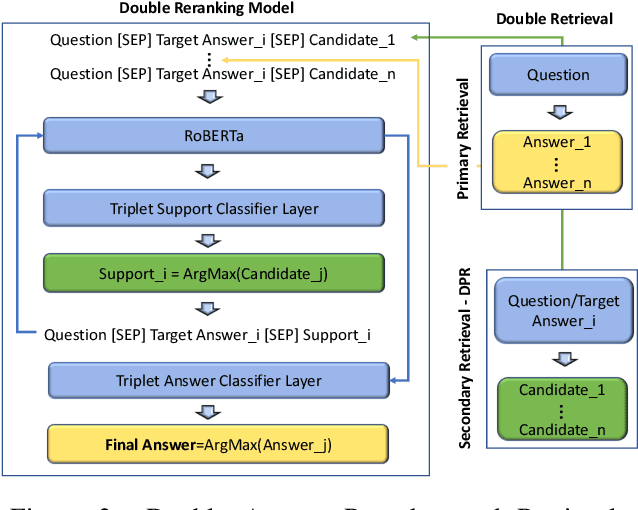
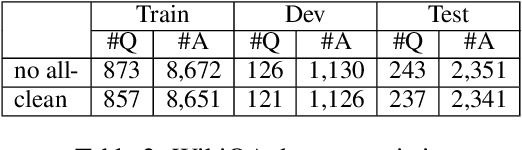
Recent work has shown that an answer verification step introduced in Transformer-based answer selection models can significantly improve the state of the art in Question Answering. This step is performed by aggregating the embeddings of top $k$ answer candidates to support the verification of a target answer. Although the approach is intuitive and sound still shows two limitations: (i) the supporting candidates are ranked only according to the relevancy with the question and not with the answer, and (ii) the support provided by the other answer candidates is suboptimal as these are retrieved independently of the target answer. In this paper, we address both drawbacks by proposing (i) a double reranking model, which, for each target answer, selects the best support; and (ii) a second neural retrieval stage designed to encode question and answer pair as the query, which finds more specific verification information. The results on three well-known datasets for AS2 show consistent and significant improvement of the state of the art.
Joint Models for Answer Verification in Question Answering Systems
Jul 09, 2021
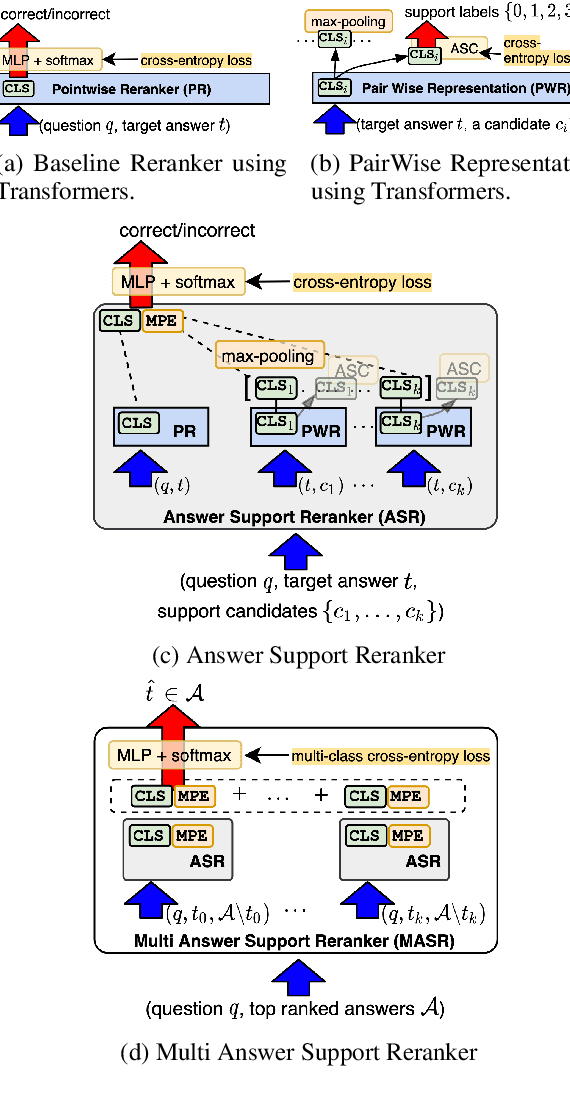
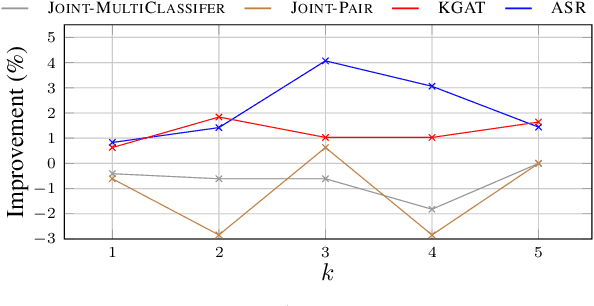
This paper studies joint models for selecting correct answer sentences among the top $k$ provided by answer sentence selection (AS2) modules, which are core components of retrieval-based Question Answering (QA) systems. Our work shows that a critical step to effectively exploit an answer set regards modeling the interrelated information between pair of answers. For this purpose, we build a three-way multi-classifier, which decides if an answer supports, refutes, or is neutral with respect to another one. More specifically, our neural architecture integrates a state-of-the-art AS2 model with the multi-classifier, and a joint layer connecting all components. We tested our models on WikiQA, TREC-QA, and a real-world dataset. The results show that our models obtain the new state of the art in AS2.
Reference-based Weak Supervision for Answer Sentence Selection using Web Data
Apr 18, 2021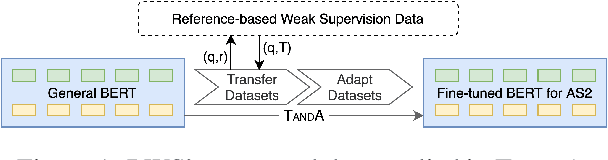


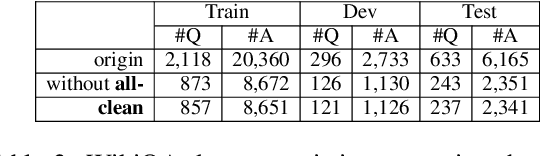
Answer sentence selection (AS2) modeling requires annotated data, i.e., hand-labeled question-answer pairs. We present a strategy to collect weakly supervised answers for a question based on its reference to improve AS2 modeling. Specifically, we introduce Reference-based Weak Supervision (RWS), a fully automatic large-scale data pipeline that harvests high-quality weakly-supervised answers from abundant Web data requiring only a question-reference pair as input. We study the efficacy and robustness of RWS in the setting of TANDA, a recent state-of-the-art fine-tuning approach specialized for AS2. Our experiments indicate that the produced data consistently bolsters TANDA. We achieve the state of the art in terms of P@1, 90.1%, and MAP, 92.9%, on WikiQA.
Multilingual Answer Sentence Reranking via Automatically Translated Data
Feb 20, 2021

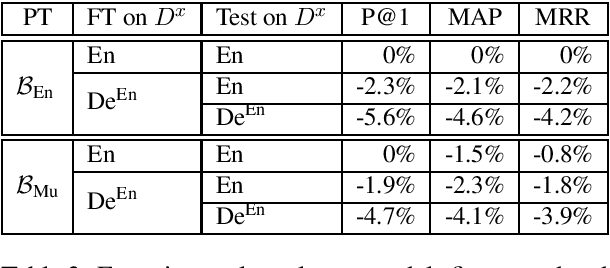
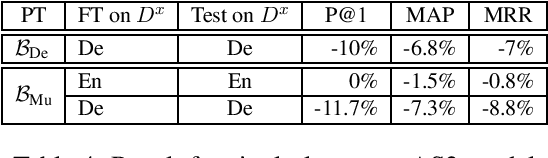
We present a study on the design of multilingual Answer Sentence Selection (AS2) models, which are a core component of modern Question Answering (QA) systems. The main idea is to transfer data, created from one resource rich language, e.g., English, to other languages, less rich in terms of resources. The main findings of this paper are: (i) the training data for AS2 translated into a target language can be used to effectively fine-tune a Transformer-based model for that language; (ii) one multilingual Transformer model it is enough to rank answers in multiple languages; and (iii) mixed-language question/answer pairs can be used to fine-tune models to select answers from any language, where the input question is just in one language. This highly reduces the complexity and technical requirement of a multilingual QA system. Our experiments validate the findings above, showing a modest drop, at most 3%, with respect to the state-of-the-art English model.
CDA: a Cost Efficient Content-based Multilingual Web Document Aligner
Feb 20, 2021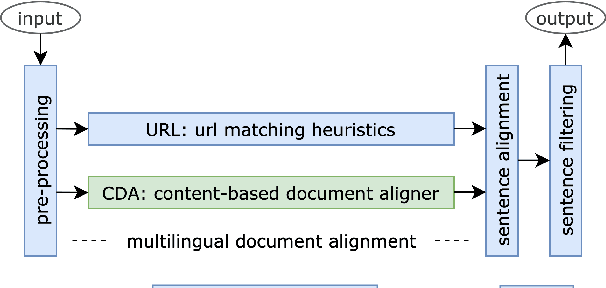
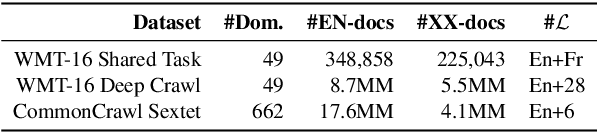
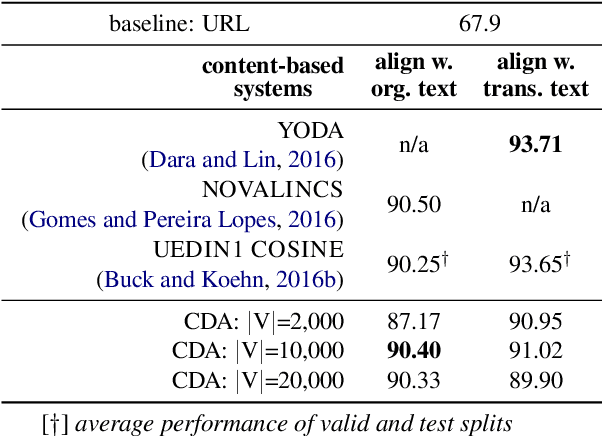
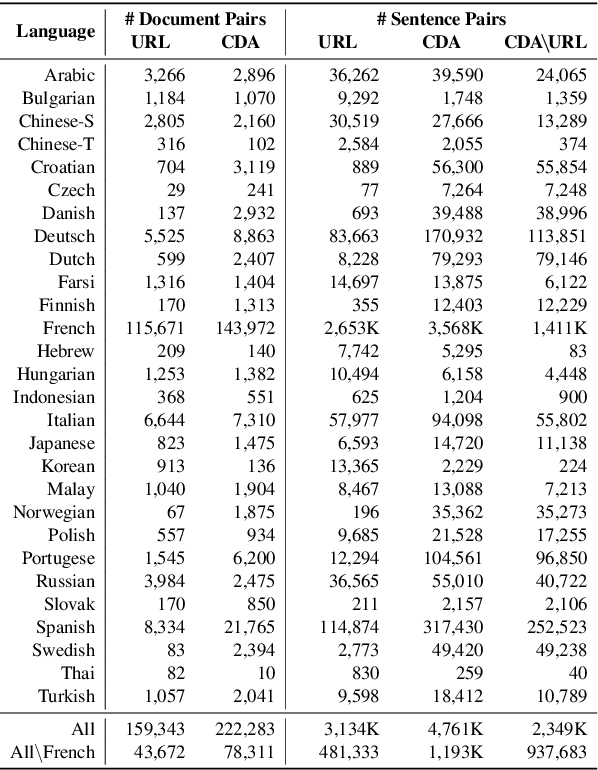
We introduce a Content-based Document Alignment approach (CDA), an efficient method to align multilingual web documents based on content in creating parallel training data for machine translation (MT) systems operating at the industrial level. CDA works in two steps: (i) projecting documents of a web domain to a shared multilingual space; then (ii) aligning them based on the similarity of their representations in such space. We leverage lexical translation models to build vector representations using TF-IDF. CDA achieves performance comparable with state-of-the-art systems in the WMT-16 Bilingual Document Alignment Shared Task benchmark while operating in multilingual space. Besides, we created two web-scale datasets to examine the robustness of CDA in an industrial setting involving up to 28 languages and millions of documents. The experiments show that CDA is robust, cost-effective, and is significantly superior in (i) processing large and noisy web data and (ii) scaling to new and low-resourced languages.
Machine Translation Customization via Automatic Training Data Selection from the Web
Feb 20, 2021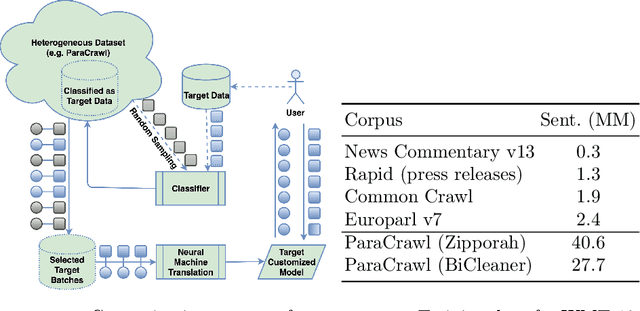
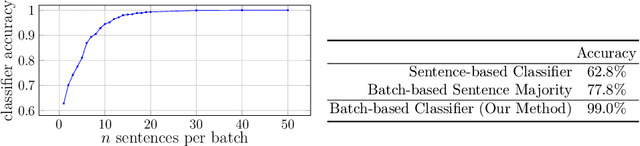
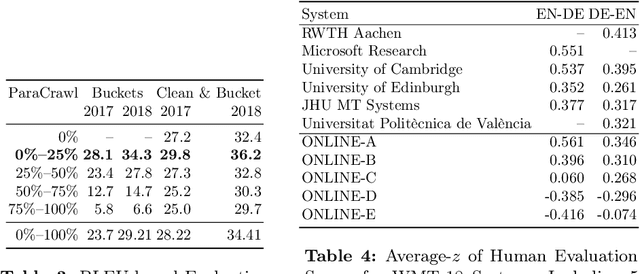
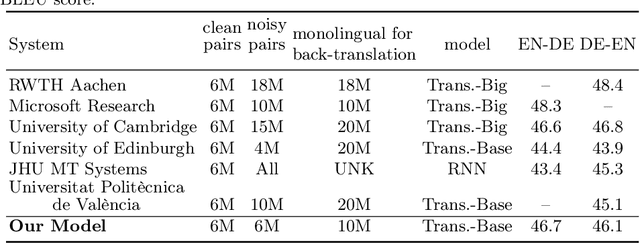
Machine translation (MT) systems, especially when designed for an industrial setting, are trained with general parallel data derived from the Web. Thus, their style is typically driven by word/structure distribution coming from the average of many domains. In contrast, MT customers want translations to be specialized to their domain, for which they are typically able to provide text samples. We describe an approach for customizing MT systems on specific domains by selecting data similar to the target customer data to train neural translation models. We build document classifiers using monolingual target data, e.g., provided by the customers to select parallel training data from Web crawled data. Finally, we train MT models on our automatically selected data, obtaining a system specialized to the target domain. We tested our approach on the benchmark from WMT-18 Translation Task for News domains enabling comparisons with state-of-the-art MT systems. The results show that our models outperform the top systems while using less data and smaller models.