 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-KB: Data Programming with Knowledge Bases Improves Transformer Fine Tuning for Answer Sentence Selection
Mar 17, 2022
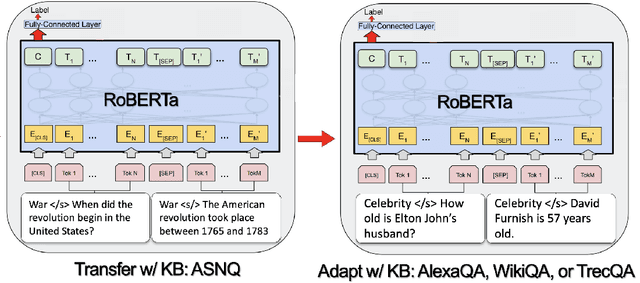
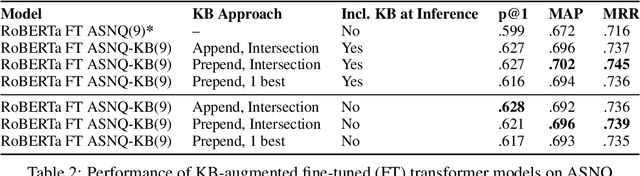
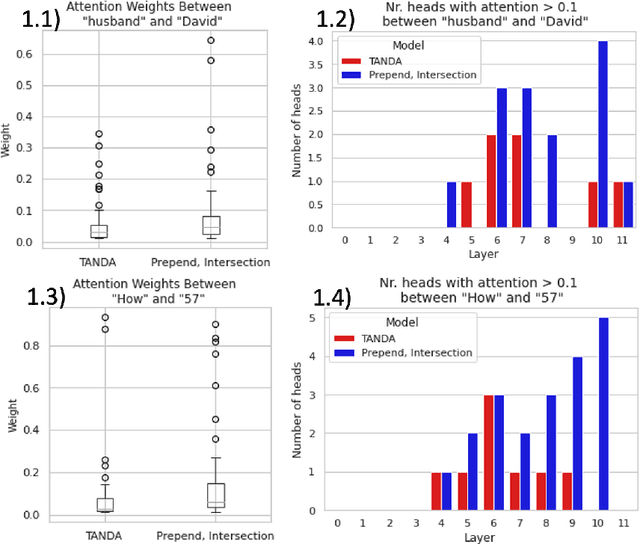
While transformers demonstrate impressive performance on many knowledge intensive (KI) tasks, their ability to serve as implicit knowledge bases (KBs) remains limited, as shown on several slot-filling, question-answering (QA), fact verification, and entity-linking tasks. In this paper, we implement an efficient, data-programming technique that enriches training data with KB-derived context and improves transformer utilization of encoded knowledge when fine-tuning for a particular QA task, namely answer sentence selection (AS2). Our method outperforms state of the art transformer approach on WikiQA and TrecQA, two widely studied AS2 benchmarks, increasing by 2.0% p@1, 1.3% MAP, 1.1% MRR, and 4.4% p@1, 0.9% MAP, 2.4% MRR, respectively. To demonstrate our improvements in an industry setting, we additionally evaluate our approach on a proprietary dataset of Alexa QA pairs, and show increase of 2.3% F1 and 2.0% MAP. We additionally find that these improvements remain even when KB context is omitted at inference time, allowing for the use of our models within existing transformer workflows without additional latency or deployment costs.