 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDA: a Cost Efficient Content-based Multilingual Web Document Aligner
Paper and Code
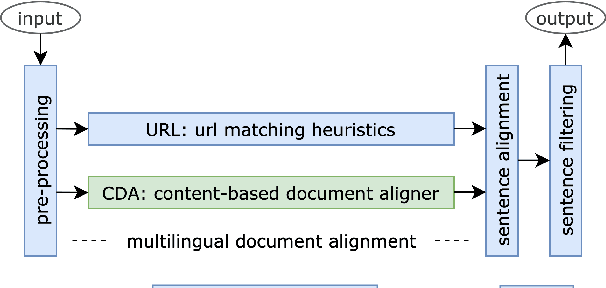
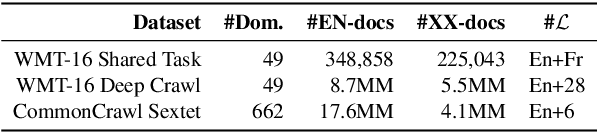
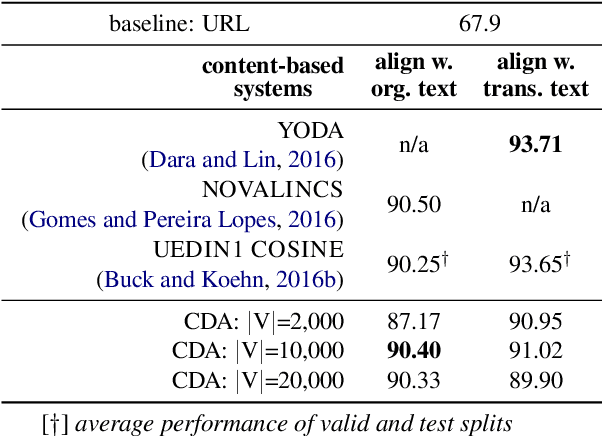
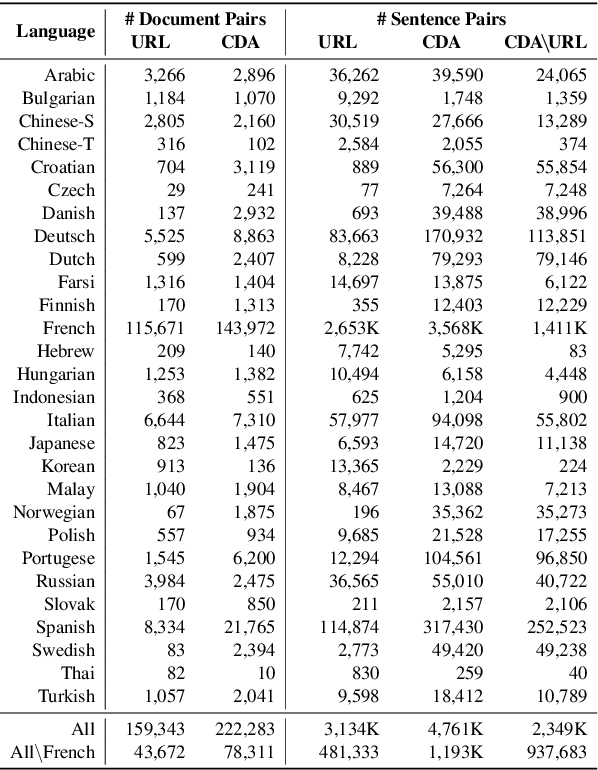
We introduce a Content-based Document Alignment approach (CDA), an efficient method to align multilingual web documents based on content in creating parallel training data for machine translation (MT) systems operating at the industrial level. CDA works in two steps: (i) projecting documents of a web domain to a shared multilingual space; then (ii) aligning them based on the similarity of their representations in such space. We leverage lexical translation models to build vector representations using TF-IDF. CDA achieves performance comparable with state-of-the-art systems in the WMT-16 Bilingual Document Alignment Shared Task benchmark while operating in multilingual space. Besides, we created two web-scale datasets to examine the robustness of CDA in an industrial setting involving up to 28 languages and millions of documents. The experiments show that CDA is robust, cost-effective, and is significantly superior in (i) processing large and noisy web data and (ii) scaling to new and low-resourced languages.