 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Autoregressive Flows for Markov Boundary Learning
Mar 21, 2026Recovering Markov boundary -- the minimal set of variables that maximizes predictive performance for a response variable -- is crucial in many applications. While recent advances improve upon traditional constraint-based techniques by scoring local causal structures, they still rely on nonparametric estimators and heuristic searches, lacking theoretical guarantees for reliability. This paper investigates a framework for efficient Markov boundary discovery by integrating conditional entropy from information theory as a scoring criterion. We design a novel masked autoregressive network to capture complex dependencies. A parallelizable greedy search strategy in polynomial time is proposed, supported by analytical evidence. We also discuss how initializing a graph with learned Markov boundaries accelerates the convergence of causal discovery. Comprehensive evaluations on real-world and synthetic datasets demonstrate the scalability and superior performance of our method in both Markov boundary discovery and causal discovery tasks.
Identifying Causal Direction via Variational Bayesian Compression
May 12, 2025Telling apart the cause and effect between two random variables with purely observational data is a challenging problem that finds applications in various scientific disciplines. A key principle utilized in this task is the algorithmic Markov condition, which postulates that the joint distribution, when factorized according to the causal direction, yields a more succinct codelength compared to the anti-causal direction. Previous approaches approximate these codelengths by relying on simple functions or Gaussian processes (GPs) with easily evaluable complexity, compromising between model fitness and computational complexity. To overcome these limitations, we propose leveraging the variational Bayesian learning of neural networks as an interpretation of the codelengths. Consequently, we can enhance the model fitness while promoting the succinctness of the codelengths, while avoiding the significant computational complexity of the GP-based approaches. Extensive experiments on both synthetic and real-world benchmarks in cause-effect identification demonstrate the effectiveness of our proposed method, surpassing the overall performance of related complexity-based and structural causal model regression-based approaches.
Amortized Conditional Independence Testing
Feb 28, 2025Testing for the conditional independence structure in data is a fundamental and critical task in statistics and machine learning, which finds natural applications in causal discovery - a highly relevant problem to many scientific disciplines. Existing methods seek to design explicit test statistics that quantify the degree of conditional dependence, which is highly challenging yet cannot capture nor utilize prior knowledge in a data-driven manner. In this study, an entirely new approach is introduced, where we instead propose to amortize conditional independence testing and devise ACID - a novel transformer-based neural network architecture that learns to test for conditional independence. ACID can be trained on synthetic data in a supervised learning fashion, and the learned model can then be applied to any dataset of similar natures or adapted to new domains by fine-tuning with a negligible computational cost. Our extensive empirical evaluations on both synthetic and real data reveal that ACID consistently achieves state-of-the-art performance against existing baselines under multiple metrics, and is able to generalize robustly to unseen sample sizes, dimensionalities, as well as non-linearities with a remarkably low inference time.
Causal Discovery via Bayesian Optimization
Jan 25, 2025



Existing score-based methods for directed acyclic graph (DAG) learning from observational data struggle to recover the causal graph accurately and sample-efficiently. To overcome this, in this study, we propose DrBO (DAG recovery via Bayesian Optimization)-a novel DAG learning framework leveraging Bayesian optimization (BO) to find high-scoring DAGs. We show that, by sophisticatedly choosing the promising DAGs to explore, we can find higher-scoring ones much more efficiently. To address the scalability issues of conventional BO in DAG learning, we replace Gaussian Processes commonly employed in BO with dropout neural networks, trained in a continual manner, which allows for (i) flexibly modeling the DAG scores without overfitting, (ii) incorporation of uncertainty into the estimated scores, and (iii) scaling with the number of evaluations. As a result, DrBO is computationally efficient and can find the accurate DAG in fewer trials and less time than existing state-of-the-art methods. This is demonstrated through an extensive set of empirical evaluations on many challenging settings with both synthetic and real data. Our implementation is available at https://github.com/baosws/DrBO.
ALIAS: DAG Learning with Efficient Unconstrained Policies
Aug 27, 2024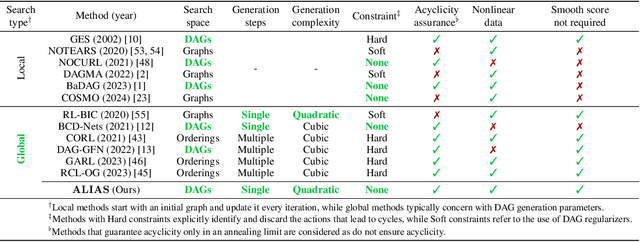
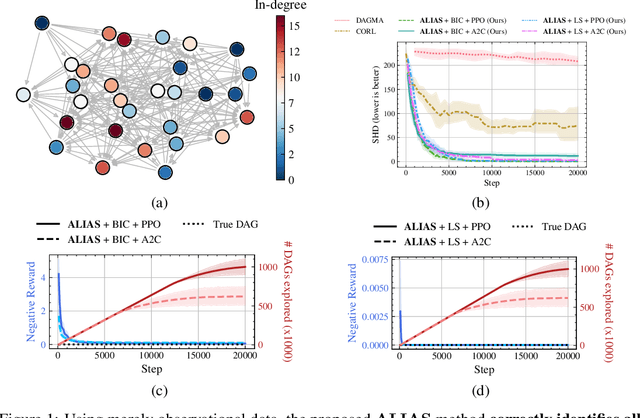
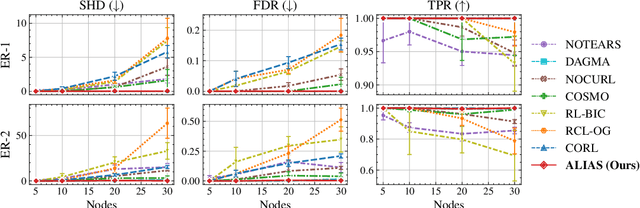
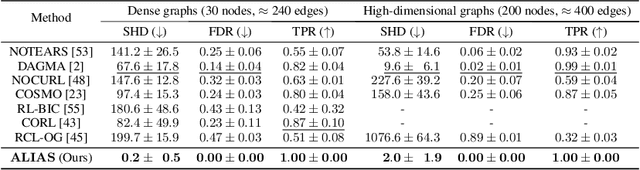
Recently, reinforcement learning (RL) has proved a promising alternative for conventional local heuristics in score-based approaches to learning directed acyclic causal graphs (DAGs) from observational data. However, the intricate acyclicity constraint still challenges the efficient exploration of the vast space of DAGs in existing methods. In this study, we introduce ALIAS (reinforced dAg Learning wIthout Acyclicity conStraints), a novel approach to causal discovery powered by the RL machinery. Our method features an efficient policy for generating DAGs in just a single step with an optimal quadratic complexity, fueled by a novel parametrization of DAGs that directly translates a continuous space to the space of all DAGs, bypassing the need for explicitly enforcing acyclicity constraints. This approach enables us to navigate the search space more effectively by utilizing policy gradient methods and established scoring functions. In addition, we provide compelling empirical evidence for the strong performance of ALIAS in comparison with state-of-the-arts in causal discovery over increasingly difficult experiment conditions on both synthetic and real datasets.
Scalable Variational Causal Discovery Unconstrained by Acyclicity
Jul 06, 2024



Bayesian causal discovery offers the power to quantify epistemic uncertainties among a broad range of structurally diverse causal theories potentially explaining the data, represented in forms of directed acyclic graphs (DAGs). However, existing methods struggle with efficient DAG sampling due to the complex acyclicity constraint. In this study, we propose a scalable Bayesian approach to effectively learn the posterior distribution over causal graphs given observational data thanks to the ability to generate DAGs without explicitly enforcing acyclicity. Specifically, we introduce a novel differentiable DAG sampling method that can generate a valid acyclic causal graph by mapping an unconstrained distribution of implicit topological orders to a distribution over DAGs. Given this efficient DAG sampling scheme, we are able to model the posterior distribution over causal graphs using a simple variational distribution over a continuous domain, which can be learned via the variational inference framework. Extensive empirical experiments on both simulated and real datasets demonstrate the superior performance of the proposed model compared to several state-of-the-art baselines.
Enabling Causal Discovery in Post-Nonlinear Models with Normalizing Flows
Jul 06, 2024Post-nonlinear (PNL) causal models stand out as a versatile and adaptable framework for modeling intricate causal relationships. However, accurately capturing the invertibility constraint required in PNL models remains challenging in existing studies. To address this problem, we introduce CAF-PoNo (Causal discovery via Normalizing Flows for Post-Nonlinear models), harnessing the power of the normalizing flows architecture to enforce the crucial invertibility constraint in PNL models. Through normalizing flows, our method precisely reconstructs the hidden noise, which plays a vital role in cause-effect identification through statistical independence testing. Furthermore, the proposed approach exhibits remarkable extensibility, as it can be seamlessly expanded to facilitate multivariate causal discovery via causal order identification, empowering us to efficiently unravel complex causal relationships. Extensive experimental evaluations on both simulated and real datasets consistently demonstrate that the proposed method outperforms several state-of-the-art approaches in both bivariate and multivariate causal discovery tasks.
Robust Estimation of Causal Heteroscedastic Noise Models
Dec 15, 2023Distinguishing the cause and effect from bivariate observational data is the foundational problem that finds applications in many scientific disciplines. One solution to this problem is assuming that cause and effect are generated from a structural causal model, enabling identification of the causal direction after estimating the model in each direction. The heteroscedastic noise model is a type of structural causal model where the cause can contribute to both the mean and variance of the noise. Current methods for estimating heteroscedastic noise models choose the Gaussian likelihood as the optimization objective which can be suboptimal and unstable when the data has a non-Gaussian distribution. To address this limitation, we propose a novel approach to estimating this model with Student's $t$-distribution, which is known for its robustness in accounting for sampling variability with smaller sample sizes and extreme values without significantly altering the overall distribution shape. This adaptability is beneficial for capturing the parameters of the noise distribution in heteroscedastic noise models. Our empirical evaluations demonstrate that our estimators are more robust and achieve better overall performance across synthetic and real benchmarks.
Domain Generalisation via Risk Distribution Matching
Oct 28, 2023



We propose a novel approach for domain generalisation (DG) leveraging risk distributions to characterise domains, thereby achieving domain invariance. In our findings, risk distributions effectively highlight differences between training domains and reveal their inherent complexities. In testing, we may observe similar, or potentially intensifying in magnitude, divergences between risk distributions. Hence, we propose a compelling proposition: Minimising the divergences between risk distributions across training domains leads to robust invariance for DG. The key rationale behind this concept is that a model, trained on domain-invariant or stable features, may consistently produce similar risk distributions across various domains. Building upon this idea, we propose Risk Distribution Matching (RDM). Using the maximum mean discrepancy (MMD) distance, RDM aims to minimise the variance of risk distributions across training domains. However, when the number of domains increases, the direct optimisation of variance leads to linear growth in MMD computations, resulting in inefficiency. Instead, we propose an approximation that requires only one MMD computation, by aligning just two distributions: that of the worst-case domain and the aggregated distribution from all domains. Notably, this method empirically outperforms optimising distributional variance while being computationally more efficient. Unlike conventional DG matching algorithms, RDM stands out for its enhanced efficacy by concentrating on scalar risk distributions, sidestepping the pitfalls of high-dimensional challenges seen in feature or gradient matching. Our extensive experiments on standard benchmark datasets demonstrate that RDM shows superior generalisation capability over state-of-the-art DG methods.
Differentiable Bayesian Structure Learning with Acyclicity Assurance
Sep 06, 2023Score-based approaches in the structure learning task are thriving because of their scalability. Continuous relaxation has been the key reason for this advancement. Despite achieving promising outcomes, most of these methods are still struggling to ensure that the graphs generated from the latent space are acyclic by minimizing a defined score. There has also been another trend of permutation-based approaches, which concern the search for the topological ordering of the variables in the directed acyclic graph in order to limit the search space of the graph. In this study, we propose an alternative approach for strictly constraining the acyclicty of the graphs with an integration of the knowledge from the topological orderings. Our approach can reduce inference complexity while ensuring the structures of the generated graphs to be acyclic. Our empirical experiments with simulated and real-world data show that our approach can outperform related Bayesian score-based approaches.