 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeh-Edit: Effective and Flexible Diffusion-Based Editing via Doob's h-Transform
Mar 04, 2025We introduce a theoretical framework for diffusion-based image editing by formulating it as a reverse-time bridge modeling problem. This approach modifies the backward process of a pretrained diffusion model to construct a bridge that converges to an implicit distribution associated with the editing target at time 0. Building on this framework, we propose h-Edit, a novel editing method that utilizes Doob's h-transform and Langevin Monte Carlo to decompose the update of an intermediate edited sample into two components: a "reconstruction" term and an "editing" term. This decomposition provides flexibility, allowing the reconstruction term to be computed via existing inversion techniques and enabling the combination of multiple editing terms to handle complex editing tasks. To our knowledge, h-Edit is the first training-free method capable of performing simultaneous text-guided and reward-model-based editing. Extensive experiments, both quantitative and qualitative, show that h-Edit outperforms state-of-the-art baselines in terms of editing effectiveness and faithfulness. Our source code is available at https://github.com/nktoan/h-edit.
Finding the Trigger: Causal Abductive Reasoning on Video Events
Jan 16, 2025This paper introduces a new problem, Causal Abductive Reasoning on Video Events (CARVE), which involves identifying causal relationships between events in a video and generating hypotheses about causal chains that account for the occurrence of a target event. To facilitate research in this direction, we create two new benchmark datasets with both synthetic and realistic videos, accompanied by trigger-target labels generated through a novel counterfactual synthesis approach. To explore the challenge of solving CARVE, we present a Causal Event Relation Network (CERN) that examines the relationships between video events in temporal and semantic spaces to efficiently determine the root-cause trigger events. Through extensive experiments, we demonstrate the critical roles of event relational representation learning and interaction modeling in solving video causal reasoning challenges. The introduction of the CARVE task, along with the accompanying datasets and the CERN framework, will advance future research on video causal reasoning and significantly facilitate various applications, including video surveillance, root-cause analysis and movie content management.
Predicting the Reliability of an Image Classifier under Image Distortion
Dec 22, 2024In image classification tasks, deep learning models are vulnerable to image distortions i.e. their accuracy significantly drops if the input images are distorted. An image-classifier is considered "reliable" if its accuracy on distorted images is above a user-specified threshold. For a quality control purpose, it is important to predict if the image-classifier is unreliable/reliable under a distortion level. In other words, we want to predict whether a distortion level makes the image-classifier "non-reliable" or "reliable". Our solution is to construct a training set consisting of distortion levels along with their "non-reliable" or "reliable" labels, and train a machine learning predictive model (called distortion-classifier) to classify unseen distortion levels. However, learning an effective distortion-classifier is a challenging problem as the training set is highly imbalanced. To address this problem, we propose two Gaussian process based methods to rebalance the training set. We conduct extensive experiments to show that our method significantly outperforms several baselines on six popular image datasets.
Learning Structural Causal Models from Ordering: Identifiable Flow Models
Dec 13, 2024
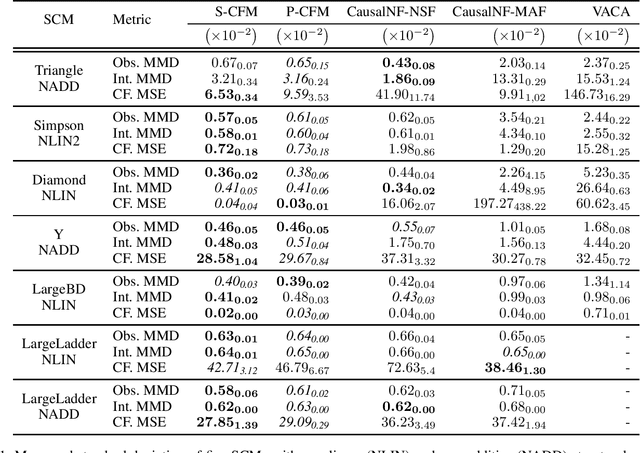


In this study, we address causal inference when only observational data and a valid causal ordering from the causal graph are available. We introduce a set of flow models that can recover component-wise, invertible transformation of exogenous variables. Our flow-based methods offer flexible model design while maintaining causal consistency regardless of the number of discretization steps. We propose design improvements that enable simultaneous learning of all causal mechanisms and reduce abduction and prediction complexity to linear O(n) relative to the number of layers, independent of the number of causal variables. Empirically, we demonstrate that our method outperforms previous state-of-the-art approaches and delivers consistent performance across a wide range of structural causal models in answering observational, interventional, and counterfactual questions. Additionally, our method achieves a significant reduction in computational time compared to existing diffusion-based techniques, making it practical for large structural causal models.
Generating Realistic Tabular Data with Large Language Models
Oct 29, 2024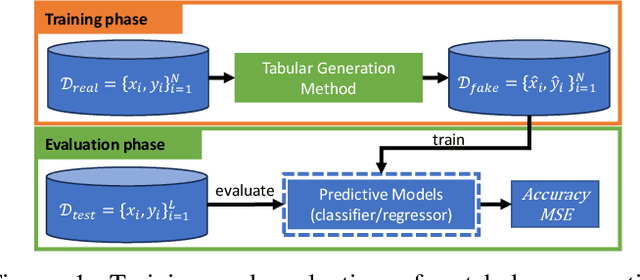

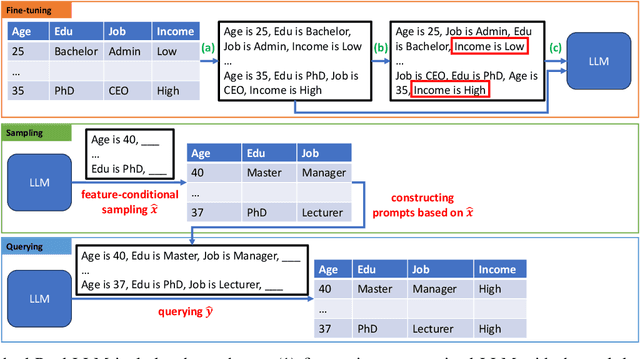
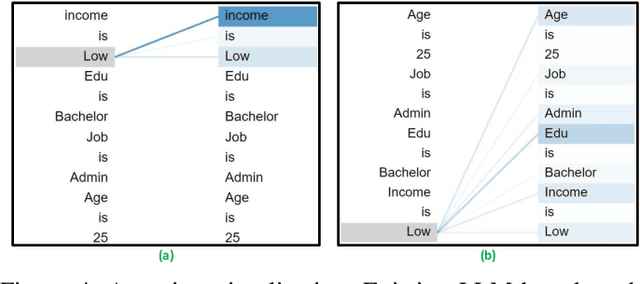
While most generative models show achievements in image data generation, few are developed for tabular data generation. Recently, due to success of large language models (LLM) in diverse tasks, they have also been used for tabular data generation. However, these methods do not capture the correct correlation between the features and the target variable, hindering their applications in downstream predictive tasks. To address this problem, we propose a LLM-based method with three important improvements to correctly capture the ground-truth feature-class correlation in the real data. First, we propose a novel permutation strategy for the input data in the fine-tuning phase. Second, we propose a feature-conditional sampling approach to generate synthetic samples. Finally, we generate the labels by constructing prompts based on the generated samples to query our fine-tuned LLM. Our extensive experiments show that our method significantly outperforms 10 SOTA baselines on 20 datasets in downstream tasks. It also produces highly realistic synthetic samples in terms of quality and diversity. More importantly, classifiers trained with our synthetic data can even compete with classifiers trained with the original data on half of the benchmark datasets, which is a significant achievement in tabular data generation.
Stable Hadamard Memory: Revitalizing Memory-Augmented Agents for Reinforcement Learning
Oct 14, 2024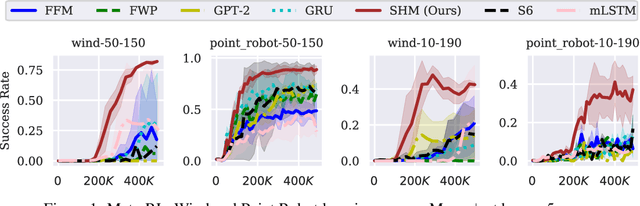
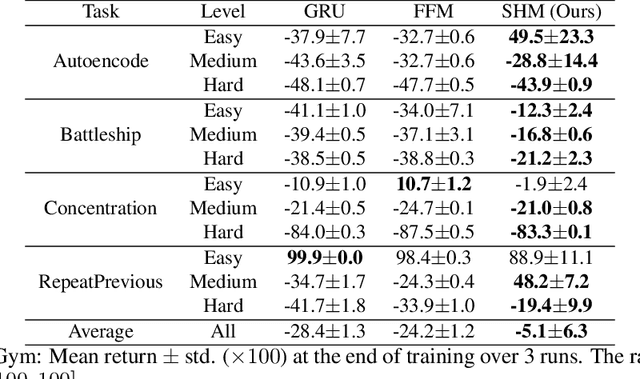
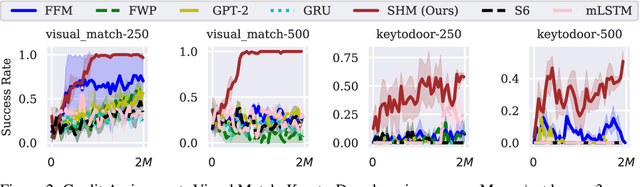

Effective decision-making in partially observable environments demands robust memory management. Despite their success in supervised learning, current deep-learning memory models struggle in reinforcement learning environments that are partially observable and long-term. They fail to efficiently capture relevant past information, adapt flexibly to changing observations, and maintain stable updates over long episodes. We theoretically analyze the limitations of existing memory models within a unified framework and introduce the Stable Hadamard Memory, a novel memory model for reinforcement learning agents. Our model dynamically adjusts memory by erasing no longer needed experiences and reinforcing crucial ones computationally efficiently. To this end, we leverage the Hadamard product for calibrating and updating memory, specifically designed to enhance memory capacity while mitigating numerical and learning challenges. Our approach significantly outperforms state-of-the-art memory-based methods on challenging partially observable benchmarks, such as meta-reinforcement learning, long-horizon credit assignment, and POPGym, demonstrating superior performance in handling long-term and evolving contexts.
Multi-Reference Preference Optimization for Large Language Models
May 26, 2024



How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
Enhancing Length Extrapolation in Sequential Models with Pointer-Augmented Neural Memory
Apr 18, 2024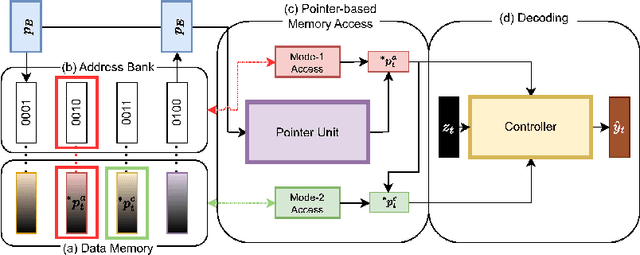

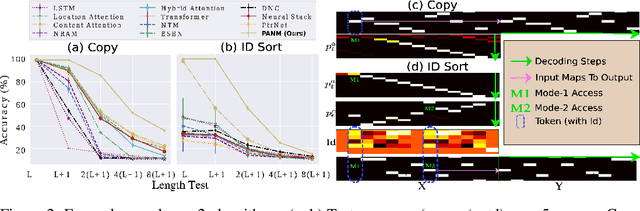

We propose Pointer-Augmented Neural Memory (PANM) to help neural networks understand and apply symbol processing to new, longer sequences of data. PANM integrates an external neural memory that uses novel physical addresses and pointer manipulation techniques to mimic human and computer symbol processing abilities. PANM facilitates pointer assignment, dereference, and arithmetic by explicitly using physical pointers to access memory content. Remarkably, it can learn to perform these operations through end-to-end training on sequence data, powering various sequential models. Our experiments demonstrate PANM's exceptional length extrapolating capabilities and improved performance in tasks that require symbol processing, such as algorithmic reasoning and Dyck language recognition. PANM helps Transformer achieve up to 100% generalization accuracy in compositional learning tasks and significantly better results in mathematical reasoning, question answering and machine translation tasks.
Variational Flow Models: Flowing in Your Style
Feb 05, 2024



We introduce a variational inference interpretation for models of "posterior flows" - generalizations of "probability flows" to a broader class of stochastic processes not necessarily diffusion processes. We coin the resulting models as "Variational Flow Models". Additionally, we propose a systematic training-free method to transform the posterior flow of a "linear" stochastic process characterized by the equation Xt = at * X0 + st * X1 into a straight constant-speed (SC) flow, reminiscent of Rectified Flow. This transformation facilitates fast sampling along the original posterior flow without training a new model of the SC flow. The flexibility of our approach allows us to extend our transformation to inter-convert two posterior flows from distinct "linear" stochastic processes. Moreover, we can easily integrate high-order numerical solvers into the transformed SC flow, further enhancing sampling accuracy and efficiency. Rigorous theoretical analysis and extensive experimental results substantiate the advantages of our framework.
Revisiting the Dataset Bias Problem from a Statistical Perspective
Feb 05, 2024


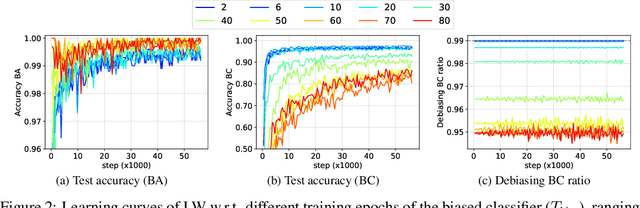
In this paper, we study the "dataset bias" problem from a statistical standpoint, and identify the main cause of the problem as the strong correlation between a class attribute u and a non-class attribute b in the input x, represented by p(u|b) differing significantly from p(u). Since p(u|b) appears as part of the sampling distributions in the standard maximum log-likelihood (MLL) objective, a model trained on a biased dataset via MLL inherently incorporates such correlation into its parameters, leading to poor generalization to unbiased test data. From this observation, we propose to mitigate dataset bias via either weighting the objective of each sample n by \frac{1}{p(u_{n}|b_{n})} or sampling that sample with a weight proportional to \frac{1}{p(u_{n}|b_{n})}. While both methods are statistically equivalent, the former proves more stable and effective in practice. Additionally, we establish a connection between our debiasing approach and causal reasoning, reinforcing our method's theoretical foundation. However, when the bias label is unavailable, computing p(u|b) exactly is difficult. To overcome this challenge, we propose to approximate \frac{1}{p(u|b)} using a biased classifier trained with "bias amplification" losses. Extensive experiments on various biased datasets demonstrate the superiority of our method over existing debiasing techniques in most settings, validating our theoretical analysis.