 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFineVLA: Multimodal Reasoning-Aware Generalist Robotic Policies via Teacher-Guided Fine-Tuning
Apr 20, 2026Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into desired robotic actions. Despite their advancements, VLAs often overlook explicit reasoning and learn the functional input-action mappings, omitting crucial logical steps, which are especially pronounced in interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose ReFineVLA, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we fine-tune pre-trained VLAs with the reasoning-enriched datasets with ReFineVLA, while maintaining the underlying generalization abilities and boosting reasoning capabilities. We also conduct attention map visualization to analyze the alignment among visual observation, linguistic prompts, and to-be-executed actions of ReFineVLA, reflecting the model is ability to focus on relevant tasks and actions. Through this additional step, we explore that ReFineVLA-trained models exhibit a meaningful agreement between vision-language and action domains, highlighting the enhanced multimodal understanding and generalization. Evaluated across a suite of simulated manipulation benchmarks on SimplerEnv with both WidowX and Google Robot tasks, ReFineVLA achieves state-of-the-art performance, in success rate over the second-best method on the both the WidowX benchmark and Google Robot Tasks.
Counting to Four is still a Chore for VLMs
Apr 11, 2026Vision--language models (VLMs) have achieved impressive performance on complex multimodal reasoning tasks, yet they still fail on simple grounding skills such as object counting. Existing evaluations mostly assess only final outputs, offering limited insight into where these failures arise inside the model. In this work, we present an empirical study of VLM counting behavior through both behavioral and mechanistic analysis. We introduce COUNTINGTRICKS, a controlled evaluation suite of simple shape-based counting cases designed to expose vulnerabilities under different patchification layouts and adversarial prompting conditions. Using attention analysis and component-wise probing, we show that count-relevant visual evidence is strongest in the modality projection stage but degrades substantially in later language layers, where models become more susceptible to text priors. Motivated by this finding, we further evaluate Modality Attention Share (MAS), a lightweight intervention that encourages a minimum budget of visual attention during answer generation. Our results suggest that counting failures in VLMs stem not only from visual perception limits, but also from the underuse of visual evidence during language-stage reasoning. Code and dataset will be released at https://github.com/leduy99/-CVPRW26-Modality-Attention-Share.
World2Act: Latent Action Post-Training via Skill-Compositional World Models
Mar 11, 2026World Models (WMs) have emerged as a promising approach for post-training Vision-Language-Action (VLA) policies to improve robustness and generalization under environmental changes. However, most WM-based post-training methods rely on pixel-space supervision, making policies sensitive to pixel-level artifacts and hallucination from imperfect WM rollouts. We introduce World2Act, a post-training framework that aligns VLA actions directly with WM video-dynamics latents using a contrastive matching objective, reducing dependence on pixels. Post-training performance is tied to rollout quality, yet current WMs struggle with arbitrary-length video generation as they are mostly trained on fixed-length clips while robotic execution durations vary widely. To address this, we propose an automatic LLM-based skill-decomposition pipeline that segments high-level instructions into low-level prompts. Our pipeline produces RoboCasa-Skill and LIBERO-Skill, supporting skill-compositional WMs that remain temporally consistent across diverse task horizons. Empirically, applying World2Act to VLAs like GR00T-N1.6 and Cosmos Policy achieves state-of-the-art results on RoboCasa and LIBERO, and improves real-world performance by 6.7%, enhancing embodied agent generalization.
ReFineVLA: Reasoning-Aware Teacher-Guided Transfer Fine-Tuning
May 25, 2025
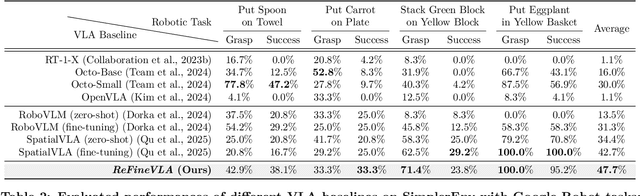

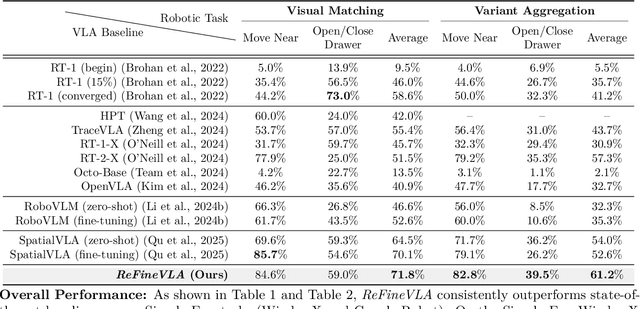
Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into robotic actions. Despite their recent advancements, VLAs often overlook the explicit reasoning and only learn the functional input-action mappings, omitting these crucial logical steps for interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose \textit{ReFineVLA}, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we use \textit{ReFineVLA} to fine-tune pre-trained VLAs with the reasoning-enriched datasets, while maintaining their inherent generalization abilities and boosting reasoning capabilities. In addition, we conduct an attention map visualization to analyze the alignment among visual attention, linguistic prompts, and to-be-executed actions of \textit{ReFineVLA}, showcasing its ability to focus on relevant tasks and actions. Through the latter step, we explore that \textit{ReFineVLA}-trained models exhibit a meaningful attention shift towards relevant objects, highlighting the enhanced multimodal understanding and improved generalization. Evaluated across manipulation tasks, \textit{ReFineVLA} outperforms the state-of-the-art baselines. Specifically, it achieves an average increase of $5.0\%$ success rate on SimplerEnv WidowX Robot tasks, improves by an average of $8.6\%$ in variant aggregation settings, and by $1.7\%$ in visual matching settings for SimplerEnv Google Robot tasks. The source code will be publicly available.
Vision Transformer Neural Architecture Search for Out-of-Distribution Generalization: Benchmark and Insights
Jan 07, 2025


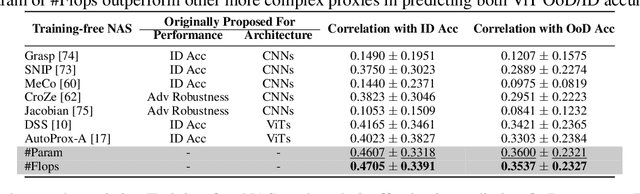
While ViTs have achieved across machine learning tasks, deploying them in real-world scenarios faces a critical challenge: generalizing under OoD shifts. A crucial research gap exists in understanding how to design ViT architectures, both manually and automatically, for better OoD generalization. To this end, we introduce OoD-ViT-NAS, the first systematic benchmark for ViTs NAS focused on OoD generalization. This benchmark includes 3000 ViT architectures of varying computational budgets evaluated on 8 common OoD datasets. Using this benchmark, we analyze factors contributing to OoD generalization. Our findings reveal key insights. First, ViT architecture designs significantly affect OoD generalization. Second, ID accuracy is often a poor indicator of OoD accuracy, highlighting the risk of optimizing ViT architectures solely for ID performance. Third, we perform the first study of NAS for ViTs OoD robustness, analyzing 9 Training-free NAS methods. We find that existing Training-free NAS methods are largely ineffective in predicting OoD accuracy despite excelling at ID accuracy. Simple proxies like Param or Flop surprisingly outperform complex Training-free NAS methods in predicting OoD accuracy. Finally, we study how ViT architectural attributes impact OoD generalization and discover that increasing embedding dimensions generally enhances performance. Our benchmark shows that ViT architectures exhibit a wide range of OoD accuracy, with up to 11.85% improvement for some OoD shifts. This underscores the importance of studying ViT architecture design for OoD. We believe OoD-ViT-NAS can catalyze further research into how ViT designs influence OoD generalization.
* Accepted in NeurIPS 2024
Language-driven Grasp Detection with Mask-guided Attention
Jul 29, 2024



Grasp detection is an essential task in robotics with various industrial applications. However, traditional methods often struggle with occlusions and do not utilize language for grasping. Incorporating natural language into grasp detection remains a challenging task and largely unexplored. To address this gap, we propose a new method for language-driven grasp detection with mask-guided attention by utilizing the transformer attention mechanism with semantic segmentation features. Our approach integrates visual data, segmentation mask features, and natural language instructions, significantly improving grasp detection accuracy. Our work introduces a new framework for language-driven grasp detection, paving the way for language-driven robotic applications. Intensive experiments show that our method outperforms other recent baselines by a clear margin, with a 10.0% success score improvement. We further validate our method in real-world robotic experiments, confirming the effectiveness of our approach.
Language-Conditioned Affordance-Pose Detection in 3D Point Clouds
Sep 19, 2023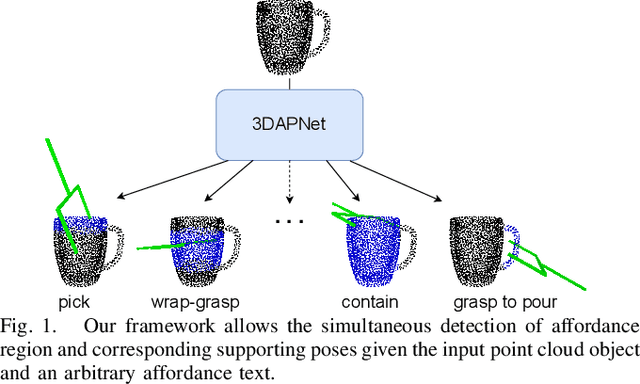

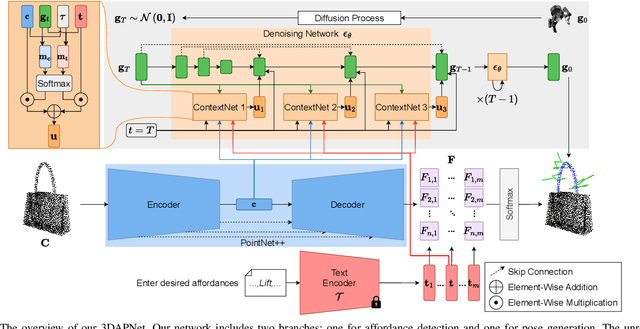
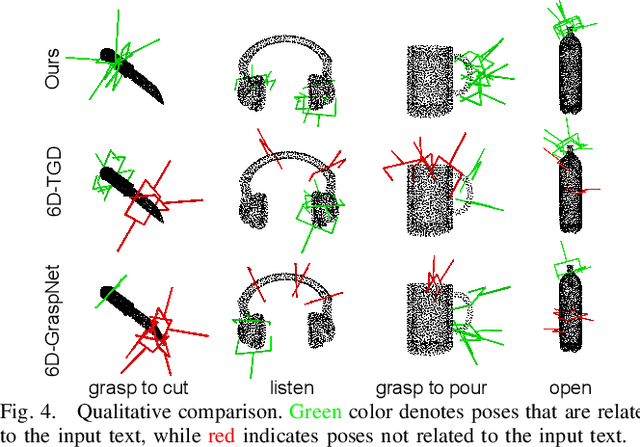
Affordance detection and pose estimation are of great importance in many robotic applications. Their combination helps the robot gain an enhanced manipulation capability, in which the generated pose can facilitate the corresponding affordance task. Previous methods for affodance-pose joint learning are limited to a predefined set of affordances, thus limiting the adaptability of robots in real-world environments. In this paper, we propose a new method for language-conditioned affordance-pose joint learning in 3D point clouds. Given a 3D point cloud object, our method detects the affordance region and generates appropriate 6-DoF poses for any unconstrained affordance label. Our method consists of an open-vocabulary affordance detection branch and a language-guided diffusion model that generates 6-DoF poses based on the affordance text. We also introduce a new high-quality dataset for the task of language-driven affordance-pose joint learning. Intensive experimental results demonstrate that our proposed method works effectively on a wide range of open-vocabulary affordances and outperforms other baselines by a large margin. In addition, we illustrate the usefulness of our method in real-world robotic applications. Our code and dataset are publicly available at https://3DAPNet.github.io
Open-Vocabulary Affordance Detection using Knowledge Distillation and Text-Point Correlation
Sep 19, 2023Affordance detection presents intricate challenges and has a wide range of robotic applications. Previous works have faced limitations such as the complexities of 3D object shapes, the wide range of potential affordances on real-world objects, and the lack of open-vocabulary support for affordance understanding. In this paper, we introduce a new open-vocabulary affordance detection method in 3D point clouds, leveraging knowledge distillation and text-point correlation. Our approach employs pre-trained 3D models through knowledge distillation to enhance feature extraction and semantic understanding in 3D point clouds. We further introduce a new text-point correlation method to learn the semantic links between point cloud features and open-vocabulary labels. The intensive experiments show that our approach outperforms previous works and adapts to new affordance labels and unseen objects. Notably, our method achieves the improvement of 7.96% mIOU score compared to the baselines. Furthermore, it offers real-time inference which is well-suitable for robotic manipulation applications.