 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Conditioned Affordance-Pose Detection in 3D Point Clouds
Paper and Code
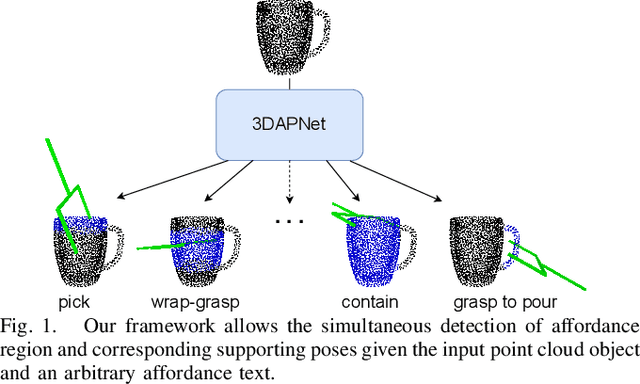

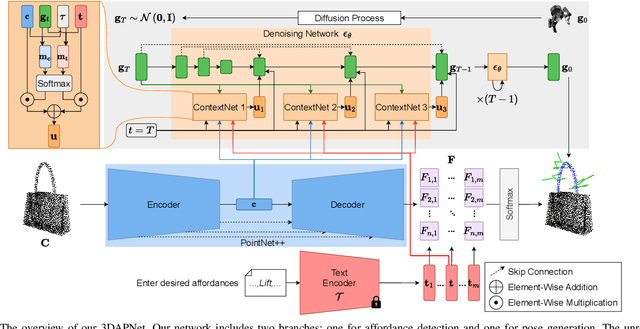
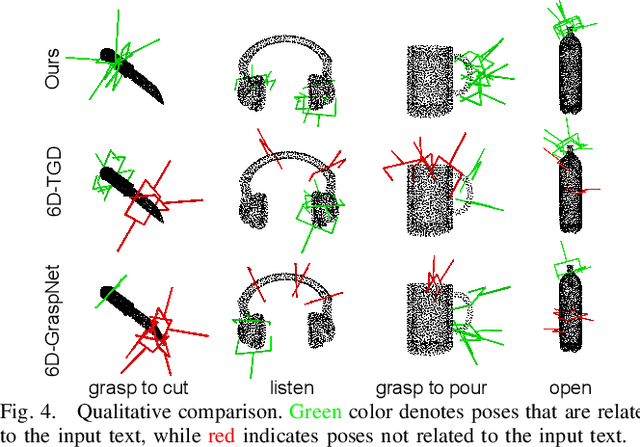
Affordance detection and pose estimation are of great importance in many robotic applications. Their combination helps the robot gain an enhanced manipulation capability, in which the generated pose can facilitate the corresponding affordance task. Previous methods for affodance-pose joint learning are limited to a predefined set of affordances, thus limiting the adaptability of robots in real-world environments. In this paper, we propose a new method for language-conditioned affordance-pose joint learning in 3D point clouds. Given a 3D point cloud object, our method detects the affordance region and generates appropriate 6-DoF poses for any unconstrained affordance label. Our method consists of an open-vocabulary affordance detection branch and a language-guided diffusion model that generates 6-DoF poses based on the affordance text. We also introduce a new high-quality dataset for the task of language-driven affordance-pose joint learning. Intensive experimental results demonstrate that our proposed method works effectively on a wide range of open-vocabulary affordances and outperforms other baselines by a large margin. In addition, we illustrate the usefulness of our method in real-world robotic applications. Our code and dataset are publicly available at https://3DAPNet.github.io