 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human Motion with Temporally Conditional Mamba
Oct 14, 2025Learning human motion based on a time-dependent input signal presents a challenging yet impactful task with various applications. The goal of this task is to generate or estimate human movement that consistently reflects the temporal patterns of conditioning inputs. Existing methods typically rely on cross-attention mechanisms to fuse the condition with motion. However, this approach primarily captures global interactions and struggles to maintain step-by-step temporal alignment. To address this limitation, we introduce Temporally Conditional Mamba, a new mamba-based model for human motion generation. Our approach integrates conditional information into the recurrent dynamics of the Mamba block, enabling better temporally aligned motion. To validate the effectiveness of our method, we evaluate it on a variety of human motion tasks. Extensive experiments demonstrate that our model significantly improves temporal alignment, motion realism, and condition consistency over state-of-the-art approaches. Our project page is available at https://zquang2202.github.io/TCM.
OZSpeech: One-step Zero-shot Speech Synthesis with Learned-Prior-Conditioned Flow Matching
May 19, 2025Text-to-speech (TTS) systems have seen significant advancements in recent years, driven by improvements in deep learning and neural network architectures. Viewing the output speech as a data distribution, previous approaches often employ traditional speech representations, such as waveforms or spectrograms, within the Flow Matching framework. However, these methods have limitations, including overlooking various speech attributes and incurring high computational costs due to additional constraints introduced during training. To address these challenges, we introduce OZSpeech, the first TTS method to explore optimal transport conditional flow matching with one-step sampling and a learned prior as the condition, effectively disregarding preceding states and reducing the number of sampling steps. Our approach operates on disentangled, factorized components of speech in token format, enabling accurate modeling of each speech attribute, which enhances the TTS system's ability to precisely clone the prompt speech. Experimental results show that our method achieves promising performance over existing methods in content accuracy, naturalness, prosody generation, and speaker style preservation. Audio samples are available at our demo page https://ozspeech.github.io/OZSpeech_Web/.
Robotic-CLIP: Fine-tuning CLIP on Action Data for Robotic Applications
Sep 26, 2024



Vision language models have played a key role in extracting meaningful features for various robotic applications. Among these, Contrastive Language-Image Pretraining (CLIP) is widely used in robotic tasks that require both vision and natural language understanding. However, CLIP was trained solely on static images paired with text prompts and has not yet been fully adapted for robotic tasks involving dynamic actions. In this paper, we introduce Robotic-CLIP to enhance robotic perception capabilities. We first gather and label large-scale action data, and then build our Robotic-CLIP by fine-tuning CLIP on 309,433 videos (~7.4 million frames) of action data using contrastive learning. By leveraging action data, Robotic-CLIP inherits CLIP's strong image performance while gaining the ability to understand actions in robotic contexts. Intensive experiments show that our Robotic-CLIP outperforms other CLIP-based models across various language-driven robotic tasks. Additionally, we demonstrate the practical effectiveness of Robotic-CLIP in real-world grasping applications.
Language-driven Grasp Detection with Mask-guided Attention
Jul 29, 2024



Grasp detection is an essential task in robotics with various industrial applications. However, traditional methods often struggle with occlusions and do not utilize language for grasping. Incorporating natural language into grasp detection remains a challenging task and largely unexplored. To address this gap, we propose a new method for language-driven grasp detection with mask-guided attention by utilizing the transformer attention mechanism with semantic segmentation features. Our approach integrates visual data, segmentation mask features, and natural language instructions, significantly improving grasp detection accuracy. Our work introduces a new framework for language-driven grasp detection, paving the way for language-driven robotic applications. Intensive experiments show that our method outperforms other recent baselines by a clear margin, with a 10.0% success score improvement. We further validate our method in real-world robotic experiments, confirming the effectiveness of our approach.
Lightweight Language-driven Grasp Detection using Conditional Consistency Model
Jul 25, 2024



Language-driven grasp detection is a fundamental yet challenging task in robotics with various industrial applications. In this work, we present a new approach for language-driven grasp detection that leverages the concept of lightweight diffusion models to achieve fast inference time. By integrating diffusion processes with grasping prompts in natural language, our method can effectively encode visual and textual information, enabling more accurate and versatile grasp positioning that aligns well with the text query. To overcome the long inference time problem in diffusion models, we leverage the image and text features as the condition in the consistency model to reduce the number of denoising timesteps during inference. The intensive experimental results show that our method outperforms other recent grasp detection methods and lightweight diffusion models by a clear margin. We further validate our method in real-world robotic experiments to demonstrate its fast inference time capability.
Language-Driven 6-DoF Grasp Detection Using Negative Prompt Guidance
Jul 18, 2024



6-DoF grasp detection has been a fundamental and challenging problem in robotic vision. While previous works have focused on ensuring grasp stability, they often do not consider human intention conveyed through natural language, hindering effective collaboration between robots and users in complex 3D environments. In this paper, we present a new approach for language-driven 6-DoF grasp detection in cluttered point clouds. We first introduce Grasp-Anything-6D, a large-scale dataset for the language-driven 6-DoF grasp detection task with 1M point cloud scenes and more than 200M language-associated 3D grasp poses. We further introduce a novel diffusion model that incorporates a new negative prompt guidance learning strategy. The proposed negative prompt strategy directs the detection process toward the desired object while steering away from unwanted ones given the language input. Our method enables an end-to-end framework where humans can command the robot to grasp desired objects in a cluttered scene using natural language. Intensive experimental results show the effectiveness of our method in both benchmarking experiments and real-world scenarios, surpassing other baselines. In addition, we demonstrate the practicality of our approach in real-world robotic applications. Our project is available at https://airvlab.github.io/grasp-anything.
Language-driven Grasp Detection
Jun 13, 2024Grasp detection is a persistent and intricate challenge with various industrial applications. Recently, many methods and datasets have been proposed to tackle the grasp detection problem. However, most of them do not consider using natural language as a condition to detect the grasp poses. In this paper, we introduce Grasp-Anything++, a new language-driven grasp detection dataset featuring 1M samples, over 3M objects, and upwards of 10M grasping instructions. We utilize foundation models to create a large-scale scene corpus with corresponding images and grasp prompts. We approach the language-driven grasp detection task as a conditional generation problem. Drawing on the success of diffusion models in generative tasks and given that language plays a vital role in this task, we propose a new language-driven grasp detection method based on diffusion models. Our key contribution is the contrastive training objective, which explicitly contributes to the denoising process to detect the grasp pose given the language instructions. We illustrate that our approach is theoretically supportive. The intensive experiments show that our method outperforms state-of-the-art approaches and allows real-world robotic grasping. Finally, we demonstrate our large-scale dataset enables zero-short grasp detection and is a challenging benchmark for future work. Project website: https://airvlab.github.io/grasp-anything/
Language-driven Scene Synthesis using Multi-conditional Diffusion Model
Oct 24, 2023Scene synthesis is a challenging problem with several industrial applications. Recently, substantial efforts have been directed to synthesize the scene using human motions, room layouts, or spatial graphs as the input. However, few studies have addressed this problem from multiple modalities, especially combining text prompts. In this paper, we propose a language-driven scene synthesis task, which is a new task that integrates text prompts, human motion, and existing objects for scene synthesis. Unlike other single-condition synthesis tasks, our problem involves multiple conditions and requires a strategy for processing and encoding them into a unified space. To address the challenge, we present a multi-conditional diffusion model, which differs from the implicit unification approach of other diffusion literature by explicitly predicting the guiding points for the original data distribution. We demonstrate that our approach is theoretically supportive. The intensive experiment results illustrate that our method outperforms state-of-the-art benchmarks and enables natural scene editing applications. The source code and dataset can be accessed at https://lang-scene-synth.github.io/.
Open-Vocabulary Affordance Detection using Knowledge Distillation and Text-Point Correlation
Sep 19, 2023Affordance detection presents intricate challenges and has a wide range of robotic applications. Previous works have faced limitations such as the complexities of 3D object shapes, the wide range of potential affordances on real-world objects, and the lack of open-vocabulary support for affordance understanding. In this paper, we introduce a new open-vocabulary affordance detection method in 3D point clouds, leveraging knowledge distillation and text-point correlation. Our approach employs pre-trained 3D models through knowledge distillation to enhance feature extraction and semantic understanding in 3D point clouds. We further introduce a new text-point correlation method to learn the semantic links between point cloud features and open-vocabulary labels. The intensive experiments show that our approach outperforms previous works and adapts to new affordance labels and unseen objects. Notably, our method achieves the improvement of 7.96% mIOU score compared to the baselines. Furthermore, it offers real-time inference which is well-suitable for robotic manipulation applications.
Language-Conditioned Affordance-Pose Detection in 3D Point Clouds
Sep 19, 2023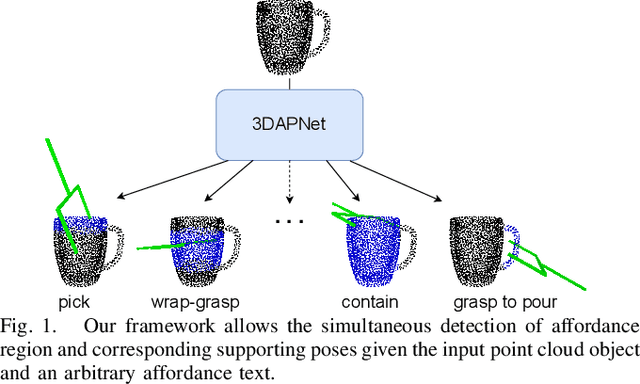

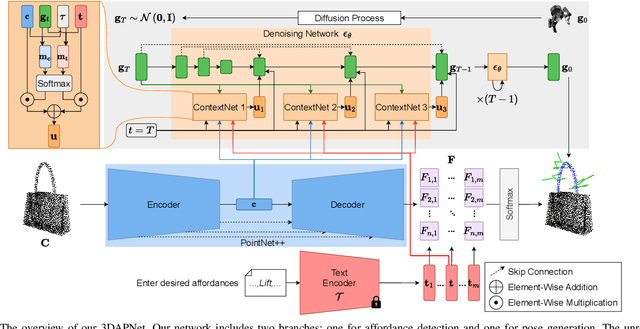
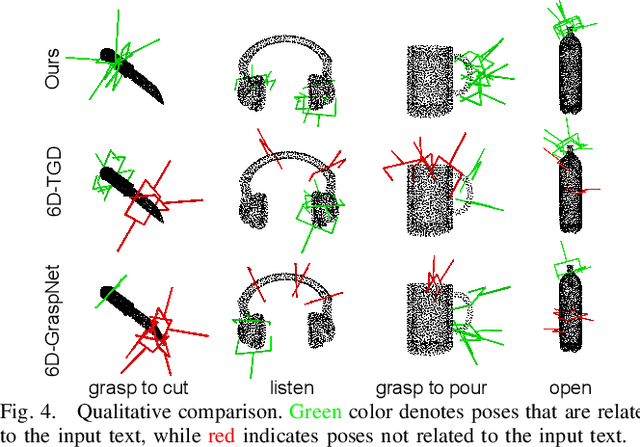
Affordance detection and pose estimation are of great importance in many robotic applications. Their combination helps the robot gain an enhanced manipulation capability, in which the generated pose can facilitate the corresponding affordance task. Previous methods for affodance-pose joint learning are limited to a predefined set of affordances, thus limiting the adaptability of robots in real-world environments. In this paper, we propose a new method for language-conditioned affordance-pose joint learning in 3D point clouds. Given a 3D point cloud object, our method detects the affordance region and generates appropriate 6-DoF poses for any unconstrained affordance label. Our method consists of an open-vocabulary affordance detection branch and a language-guided diffusion model that generates 6-DoF poses based on the affordance text. We also introduce a new high-quality dataset for the task of language-driven affordance-pose joint learning. Intensive experimental results demonstrate that our proposed method works effectively on a wide range of open-vocabulary affordances and outperforms other baselines by a large margin. In addition, we illustrate the usefulness of our method in real-world robotic applications. Our code and dataset are publicly available at https://3DAPNet.github.io