 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Nonmyopic Bayesian Optimization in Dynamic Cost Settings
Jan 10, 2026Bayesian optimization (BO) is a common framework for optimizing black-box functions, yet most existing methods assume static query costs and rely on myopic acquisition strategies. We introduce LookaHES, a nonmyopic BO framework designed for dynamic, history-dependent cost environments, where evaluation costs vary with prior actions, such as travel distance in spatial tasks or edit distance in sequence design. LookaHES combines a multi-step variant of $H$-Entropy Search with pathwise sampling and neural policy optimization, enabling long-horizon planning beyond twenty steps without the exponential complexity of existing nonmyopic methods. The key innovation is the integration of neural policies, including large language models, to effectively navigate structured, combinatorial action spaces such as protein sequences. These policies amortize lookahead planning and can be integrated with domain-specific constraints during rollout. Empirically, LookaHES outperforms strong myopic and nonmyopic baselines across nine synthetic benchmarks from two to eight dimensions and two real-world tasks: geospatial optimization using NASA night-light imagery and protein sequence design with constrained token-level edits. In short, LookaHES provides a general, scalable, and cost-aware solution for robust long-horizon optimization in complex decision spaces, which makes it a useful tool for researchers in machine learning, statistics, and applied domains. Our implementation is available at https://github.com/sangttruong/nonmyopia.
Crossing Linguistic Horizons: Finetuning and Comprehensive Evaluation of Vietnamese Large Language Models
Mar 05, 2024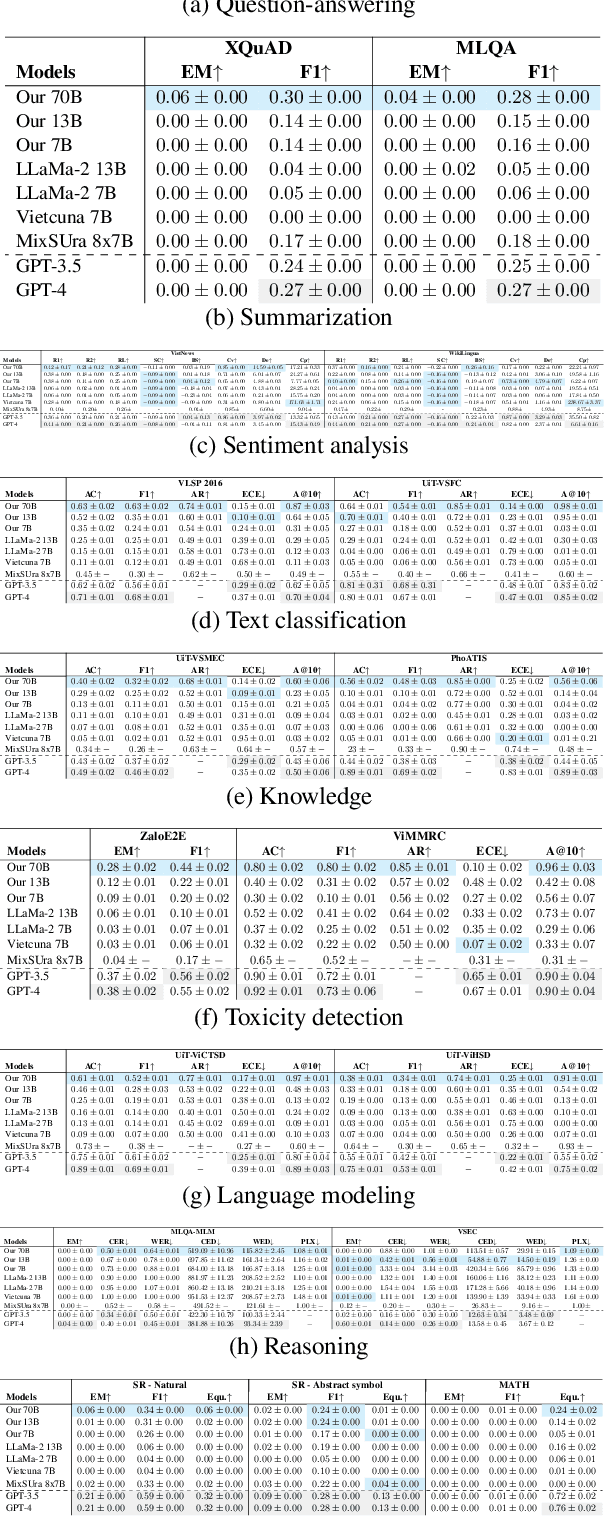
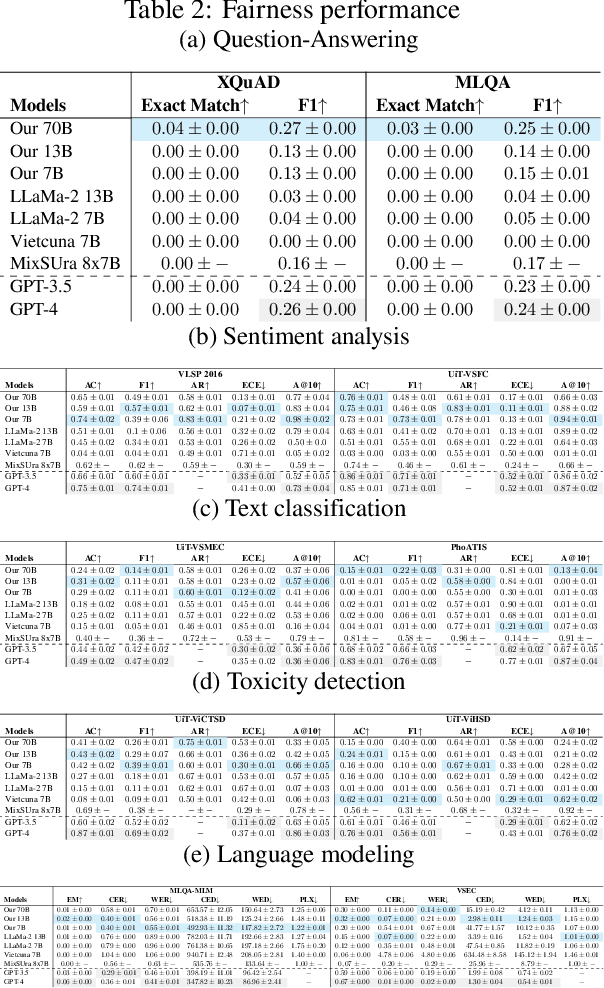
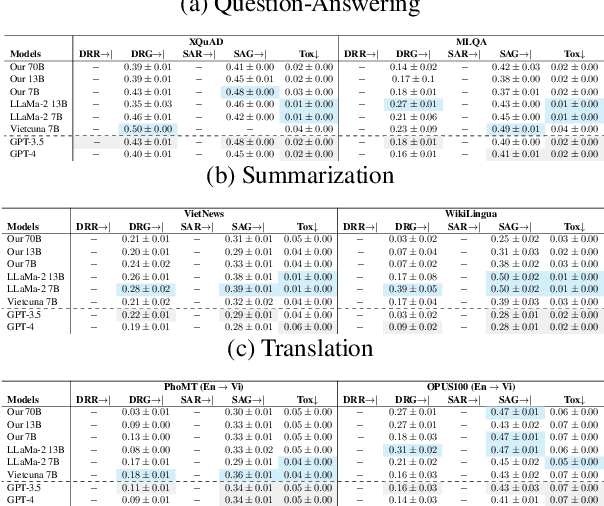
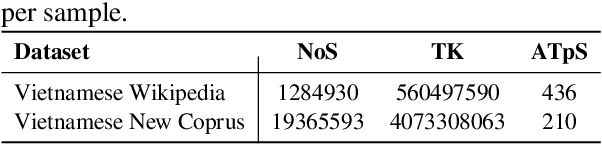
Recent advancements in large language models (LLMs) have underscored their importance in the evolution of artificial intelligence. However, despite extensive pretraining on multilingual datasets, available open-sourced LLMs exhibit limited effectiveness in processing Vietnamese. The challenge is exacerbated by the absence of systematic benchmark datasets and metrics tailored for Vietnamese LLM evaluation. To mitigate these issues, we have finetuned LLMs specifically for Vietnamese and developed a comprehensive evaluation framework encompassing 10 common tasks and 31 metrics. Our evaluation results reveal that the fine-tuned LLMs exhibit enhanced comprehension and generative capabilities in Vietnamese. Moreover, our analysis indicates that models with more parameters can introduce more biases and uncalibrated outputs and the key factor influencing LLM performance is the quality of the training or fine-tuning datasets. These insights underscore the significance of meticulous fine-tuning with high-quality datasets in enhancing LLM performance.
xNeuSM: Explainable Neural Subgraph Matching with Graph Learnable Multi-hop Attention Networks
Dec 04, 2023Subgraph matching is a challenging problem with a wide range of applications in database systems, biochemistry, and cognitive science. It involves determining whether a given query graph is present within a larger target graph. Traditional graph-matching algorithms provide precise results but face challenges in large graph instances due to the NP-complete problem, limiting their practical applicability. In contrast, recent neural network-based approximations offer more scalable solutions, but often lack interpretable node correspondences. To address these limitations, this article presents xNeuSM: Explainable Neural Subgraph Matching which introduces Graph Learnable Multi-hop Attention Networks (GLeMA) that adaptively learns the parameters governing the attention factor decay for each node across hops rather than relying on fixed hyperparameters. We provide a theoretical analysis establishing error bounds for GLeMA's approximation of multi-hop attention as a function of the number of hops. Additionally, we prove that learning distinct attention decay factors for each node leads to a correct approximation of multi-hop attention. Empirical evaluation on real-world datasets shows that xNeuSM achieves substantial improvements in prediction accuracy of up to 34% compared to approximate baselines and, notably, at least a seven-fold faster query time than exact algorithms. The source code of our implementation is available at https://github.com/martinakaduc/xNeuSM.