 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
Apr 23, 2024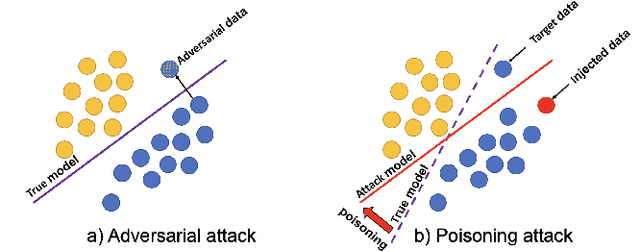
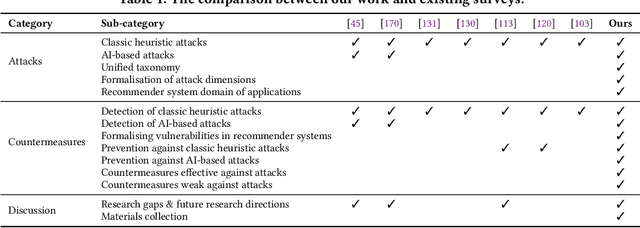
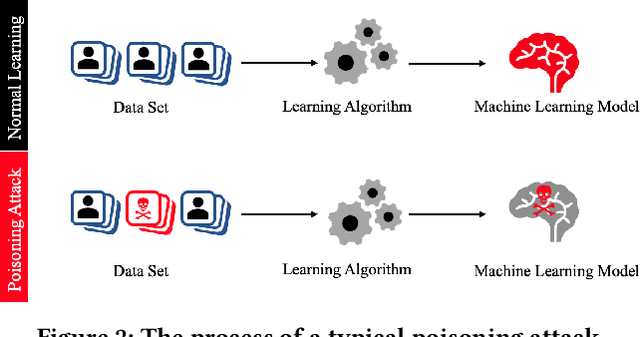
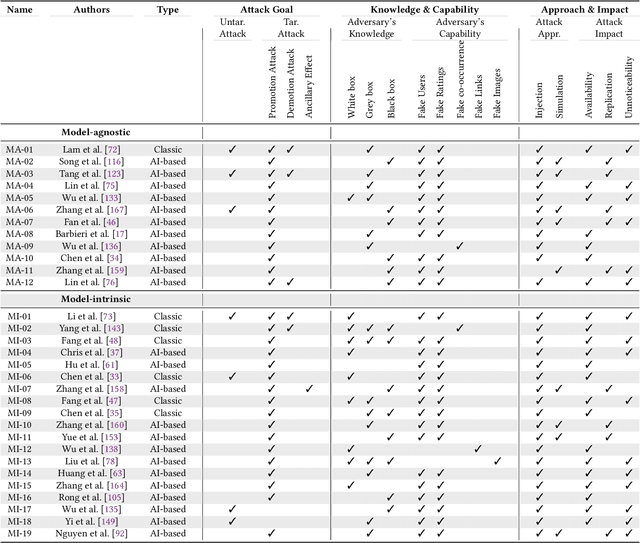
Recommender systems have become an integral part of online services to help users locate specific information in a sea of data. However, existing studies show that some recommender systems are vulnerable to poisoning attacks, particularly those that involve learning schemes. A poisoning attack is where an adversary injects carefully crafted data into the process of training a model, with the goal of manipulating the system's final recommendations. Based on recent advancements in artificial intelligence, such attacks have gained importance recently. While numerous countermeasures to poisoning attacks have been developed, they have not yet been systematically linked to the properties of the attacks. Consequently, assessing the respective risks and potential success of mitigation strategies is difficult, if not impossible. This survey aims to fill this gap by primarily focusing on poisoning attacks and their countermeasures. This is in contrast to prior surveys that mainly focus on attacks and their detection methods. Through an exhaustive literature review, we provide a novel taxonomy for poisoning attacks, formalise its dimensions, and accordingly organise 30+ attacks described in the literature. Further, we review 40+ countermeasures to detect and/or prevent poisoning attacks, evaluating their effectiveness against specific types of attacks. This comprehensive survey should serve as a point of reference for protecting recommender systems against poisoning attacks. The article concludes with a discussion on open issues in the field and impactful directions for future research. A rich repository of resources associated with poisoning attacks is available at https://github.com/tamlhp/awesome-recsys-poisoning.
A Survey of Privacy-Preserving Model Explanations: Privacy Risks, Attacks, and Countermeasures
Mar 31, 2024



As the adoption of explainable AI (XAI) continues to expand, the urgency to address its privacy implications intensifies. Despite a growing corpus of research in AI privacy and explainability, there is little attention on privacy-preserving model explanations. This article presents the first thorough survey about privacy attacks on model explanations and their countermeasures. Our contribution to this field comprises a thorough analysis of research papers with a connected taxonomy that facilitates the categorisation of privacy attacks and countermeasures based on the targeted explanations. This work also includes an initial investigation into the causes of privacy leaks. Finally, we discuss unresolved issues and prospective research directions uncovered in our analysis. This survey aims to be a valuable resource for the research community and offers clear insights for those new to this domain. To support ongoing research, we have established an online resource repository, which will be continuously updated with new and relevant findings. Interested readers are encouraged to access our repository at https://github.com/tamlhp/awesome-privex.
xNeuSM: Explainable Neural Subgraph Matching with Graph Learnable Multi-hop Attention Networks
Dec 04, 2023Subgraph matching is a challenging problem with a wide range of applications in database systems, biochemistry, and cognitive science. It involves determining whether a given query graph is present within a larger target graph. Traditional graph-matching algorithms provide precise results but face challenges in large graph instances due to the NP-complete problem, limiting their practical applicability. In contrast, recent neural network-based approximations offer more scalable solutions, but often lack interpretable node correspondences. To address these limitations, this article presents xNeuSM: Explainable Neural Subgraph Matching which introduces Graph Learnable Multi-hop Attention Networks (GLeMA) that adaptively learns the parameters governing the attention factor decay for each node across hops rather than relying on fixed hyperparameters. We provide a theoretical analysis establishing error bounds for GLeMA's approximation of multi-hop attention as a function of the number of hops. Additionally, we prove that learning distinct attention decay factors for each node leads to a correct approximation of multi-hop attention. Empirical evaluation on real-world datasets shows that xNeuSM achieves substantial improvements in prediction accuracy of up to 34% compared to approximate baselines and, notably, at least a seven-fold faster query time than exact algorithms. The source code of our implementation is available at https://github.com/martinakaduc/xNeuSM.