 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Rank-One MIMO Q Network Framework for Accelerated Offline Reinforcement Learning
Feb 23, 2026Offline reinforcement learning (RL) has garnered significant interest due to its safe and easily scalable paradigm. However, training under this paradigm presents its own challenge: the extrapolation error stemming from out-of-distribution (OOD) data. Existing methodologies have endeavored to address this issue through means like penalizing OOD Q-values or imposing similarity constraints on the learned policy and the behavior policy. Nonetheless, these approaches are often beset by limitations such as being overly conservative in utilizing OOD data, imprecise OOD data characterization, and significant computational overhead. To address these challenges, this paper introduces an Uncertainty-Aware Rank-One Multi-Input Multi-Output (MIMO) Q Network framework. The framework aims to enhance Offline Reinforcement Learning by fully leveraging the potential of OOD data while still ensuring efficiency in the learning process. Specifically, the framework quantifies data uncertainty and harnesses it in the training losses, aiming to train a policy that maximizes the lower confidence bound of the corresponding Q-function. Furthermore, a Rank-One MIMO architecture is introduced to model the uncertainty-aware Q-function, \TP{offering the same ability for uncertainty quantification as an ensemble of networks but with a cost nearly equivalent to that of a single network}. Consequently, this framework strikes a harmonious balance between precision, speed, and memory efficiency, culminating in improved overall performance. Extensive experimentation on the D4RL benchmark demonstrates that the framework attains state-of-the-art performance while remaining computationally efficient. By incorporating the concept of uncertainty quantification, our framework offers a promising avenue to alleviate extrapolation errors and enhance the efficiency of offline RL.
* 10 pages, 4 Figures, IEEE Access
From Visual Explanations to Counterfactual Explanations with Latent Diffusion
Apr 12, 2025



Visual counterfactual explanations are ideal hypothetical images that change the decision-making of the classifier with high confidence toward the desired class while remaining visually plausible and close to the initial image. In this paper, we propose a new approach to tackle two key challenges in recent prominent works: i) determining which specific counterfactual features are crucial for distinguishing the "concept" of the target class from the original class, and ii) supplying valuable explanations for the non-robust classifier without relying on the support of an adversarially robust model. Our method identifies the essential region for modification through algorithms that provide visual explanations, and then our framework generates realistic counterfactual explanations by combining adversarial attacks based on pruning the adversarial gradient of the target classifier and the latent diffusion model. The proposed method outperforms previous state-of-the-art results on various evaluation criteria on ImageNet and CelebA-HQ datasets. In general, our method can be applied to arbitrary classifiers, highlight the strong association between visual and counterfactual explanations, make semantically meaningful changes from the target classifier, and provide observers with subtle counterfactual images.
* 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
DimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning
Sep 21, 2023



Self-supervised learning (SSL) has gained remarkable success, for which contrastive learning (CL) plays a key role. However, the recent development of new non-CL frameworks has achieved comparable or better performance with high improvement potential, prompting researchers to enhance these frameworks further. Assimilating CL into non-CL frameworks has been thought to be beneficial, but empirical evidence indicates no visible improvements. In view of that, this paper proposes a strategy of performing CL along the dimensional direction instead of along the batch direction as done in conventional contrastive learning, named Dimensional Contrastive Learning (DimCL). DimCL aims to enhance the feature diversity, and it can serve as a regularizer to prior SSL frameworks. DimCL has been found to be effective, and the hardness-aware property is identified as a critical reason for its success. Extensive experimental results reveal that assimilating DimCL into SSL frameworks leads to performance improvement by a non-trivial margin on various datasets and backbone architectures.
Robust MAML: Prioritization task buffer with adaptive learning process for model-agnostic meta-learning
Mar 15, 2021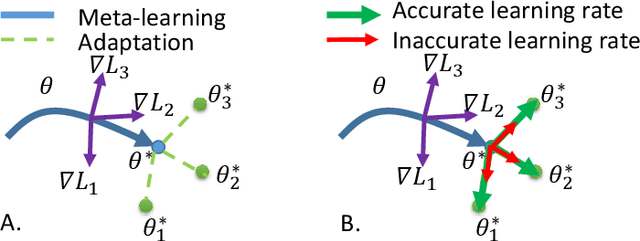
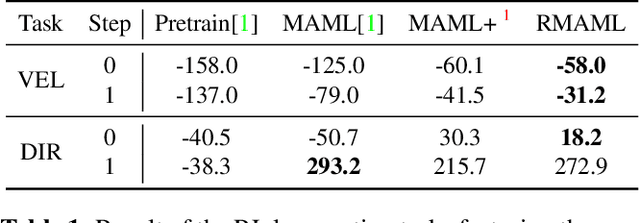
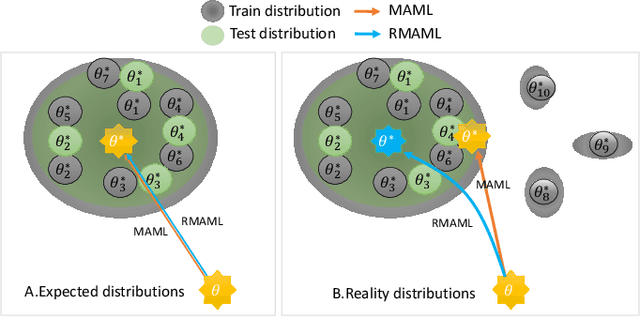
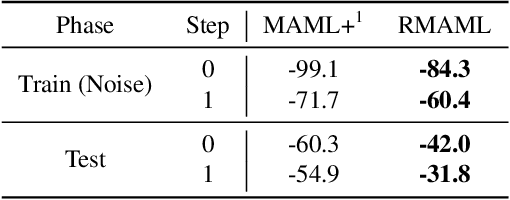
Model agnostic meta-learning (MAML) is a popular state-of-the-art meta-learning algorithm that provides good weight initialization of a model given a variety of learning tasks. The model initialized by provided weight can be fine-tuned to an unseen task despite only using a small amount of samples and within a few adaptation steps. MAML is simple and versatile but requires costly learning rate tuning and careful design of the task distribution which affects its scalability and generalization. This paper proposes a more robust MAML based on an adaptive learning scheme and a prioritization task buffer(PTB) referred to as Robust MAML (RMAML) for improving scalability of training process and alleviating the problem of distribution mismatch. RMAML uses gradient-based hyper-parameter optimization to automatically find the optimal learning rate and uses the PTB to gradually adjust train-ing task distribution toward testing task distribution over the course of training. Experimental results on meta reinforcement learning environments demonstrate a substantial performance gain as well as being less sensitive to hyper-parameter choice and robust to distribution mismatch.