 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordMatcher: Affordance Learning in 3D Scenes from Visual Signifiers
Mar 30, 2026Affordance learning is a complex challenge in many applications, where existing approaches primarily focus on the geometric structures, visual knowledge, and affordance labels of objects to determine interactable regions. However, extending this learning capability to a scene is significantly more complicated, as incorporating object- and scene-level semantics is not straightforward. In this work, we introduce AffordBridge, a large-scale dataset with 291,637 functional interaction annotations across 685 high-resolution indoor scenes in the form of point clouds. Our affordance annotations are complemented by RGB images that are linked to the same instances within the scenes. Building upon our dataset, we propose AffordMatcher, an affordance learning method that establishes coherent semantic correspondences between image-based and point cloud-based instances for keypoint matching, enabling a more precise identification of affordance regions based on cues, so-called visual signifiers. Experimental results on our dataset demonstrate the effectiveness of our approach compared to other methods.
AeroScene: Progressive Scene Synthesis for Aerial Robotics
Mar 24, 2026Generative models have shown substantial impact across multiple domains, their potential for scene synthesis remains underexplored in robotics. This gap is more evident in drone simulators, where simulation environments still rely heavily on manual efforts, which are time-consuming to create and difficult to scale. In this work, we introduce AeroScene, a hierarchical diffusion model for progressive 3D scene synthesis. Our approach leverages hierarchy-aware tokenization and multi-branch feature extraction to reason across both global layouts and local details, ensuring physical plausibility and semantic consistency. This makes AeroScene particularly suited for generating realistic scenes for aerial robotics tasks such as navigation, landing, and perching. We demonstrate its effectiveness through extensive experiments on our newly collected dataset and a public benchmark, showing that AeroScene significantly outperforms prior methods. Furthermore, we use AeroScene to generate a large-scale dataset of over 1,000 physics-ready, high fidelity 3D scenes that can be directly integrated into NVIDIA Isaac Sim. Finally, we illustrate the utility of these generated environments on downstream drone navigation tasks. Our code and dataset are publicly available at aioz-ai.github.io/AeroScene/
FedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025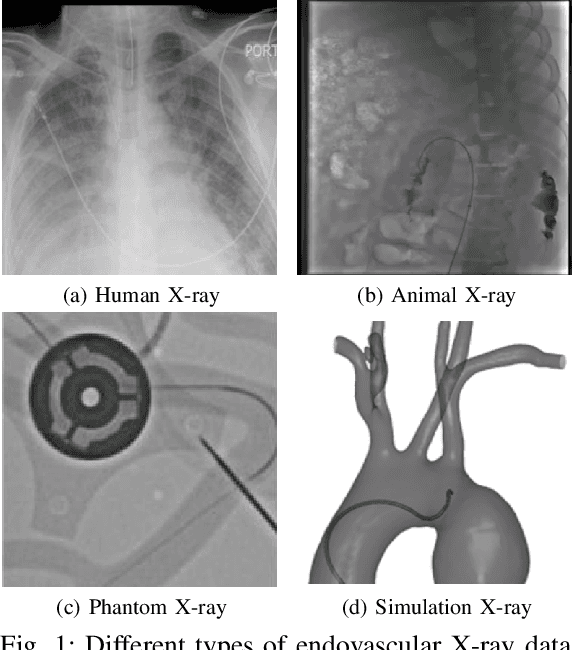
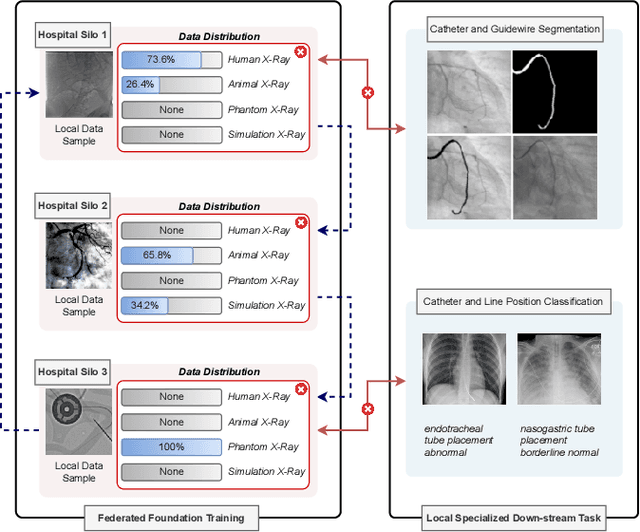

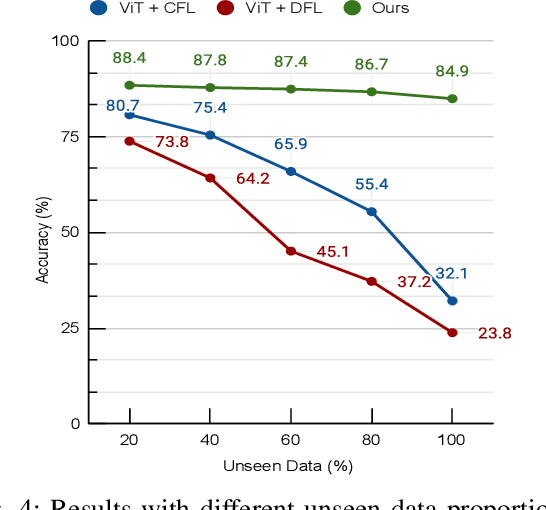
In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.
Flagellar Swimming at Low Reynolds Numbers: Zoospore-Inspired Robotic Swimmers with Dual Flagella for High-Speed Locomotion
Dec 07, 2024Traditional locomotion strategies become ineffective at low Reynolds numbers, where viscous forces predominate over inertial forces. To adapt, microorganisms have evolved specialized structures like cilia and flagella for efficient maneuvering in viscous environments. Among these organisms, Phytophthora zoospores demonstrate unique locomotion mechanisms that allow them to rapidly spread and attack new hosts while expending minimal energy. In this study, we present the design, fabrication, and testing of a zoospore-inspired robot, which leverages dual flexible flagella and oscillatory propulsion mechanisms to emulate the natural swimming behavior of zoospores. Our experiments and theoretical model reveal that both flagellar length and oscillation frequency strongly influence the robot's propulsion speed, with longer flagella and higher frequencies yielding enhanced performance. Additionally, the anterior flagellum, which generates a pulling force on the body, plays a dominant role in enhancing propulsion efficiency compared to the posterior flagellum's pushing force. This is a significant experimental finding, as it would be challenging to observe directly in biological zoospores, which spontaneously release the posterior flagellum when the anterior flagellum detaches. This work contributes to the development of advanced microscale robotic systems with potential applications in medical, environmental, and industrial fields. It also provides a valuable platform for studying biological zoospores and their unique locomotion strategies.
Scalable Group Choreography via Variational Phase Manifold Learning
Jul 26, 2024



Generating group dance motion from the music is a challenging task with several industrial applications. Although several methods have been proposed to tackle this problem, most of them prioritize optimizing the fidelity in dancing movement, constrained by predetermined dancer counts in datasets. This limitation impedes adaptability to real-world applications. Our study addresses the scalability problem in group choreography while preserving naturalness and synchronization. In particular, we propose a phase-based variational generative model for group dance generation on learning a generative manifold. Our method achieves high-fidelity group dance motion and enables the generation with an unlimited number of dancers while consuming only a minimal and constant amount of memory. The intensive experiments on two public datasets show that our proposed method outperforms recent state-of-the-art approaches by a large margin and is scalable to a great number of dancers beyond the training data.
Controllable Group Choreography using Contrastive Diffusion
Nov 03, 2023
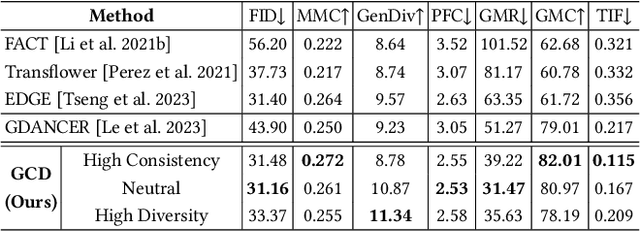
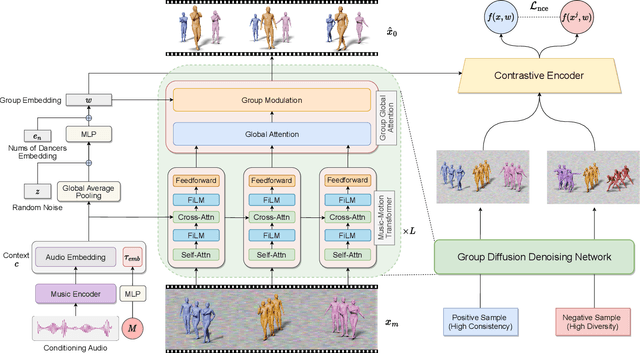
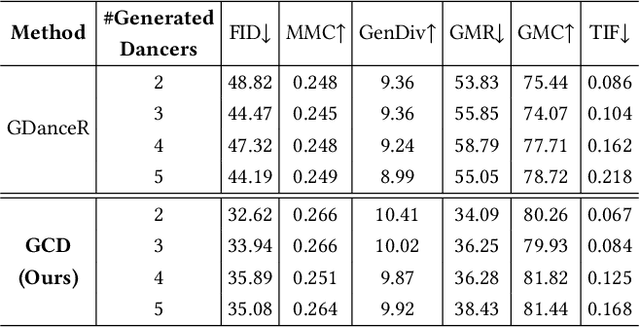
Music-driven group choreography poses a considerable challenge but holds significant potential for a wide range of industrial applications. The ability to generate synchronized and visually appealing group dance motions that are aligned with music opens up opportunities in many fields such as entertainment, advertising, and virtual performances. However, most of the recent works are not able to generate high-fidelity long-term motions, or fail to enable controllable experience. In this work, we aim to address the demand for high-quality and customizable group dance generation by effectively governing the consistency and diversity of group choreographies. In particular, we utilize a diffusion-based generative approach to enable the synthesis of flexible number of dancers and long-term group dances, while ensuring coherence to the input music. Ultimately, we introduce a Group Contrastive Diffusion (GCD) strategy to enhance the connection between dancers and their group, presenting the ability to control the consistency or diversity level of the synthesized group animation via the classifier-guidance sampling technique. Through intensive experiments and evaluation, we demonstrate the effectiveness of our approach in producing visually captivating and consistent group dance motions. The experimental results show the capability of our method to achieve the desired levels of consistency and diversity, while maintaining the overall quality of the generated group choreography. The source code can be found at https://aioz-ai.github.io/GCD
Music-Driven Group Choreography
Mar 27, 2023



Music-driven choreography is a challenging problem with a wide variety of industrial applications. Recently, many methods have been proposed to synthesize dance motions from music for a single dancer. However, generating dance motion for a group remains an open problem. In this paper, we present $\rm AIOZ-GDANCE$, a new large-scale dataset for music-driven group dance generation. Unlike existing datasets that only support single dance, our new dataset contains group dance videos, hence supporting the study of group choreography. We propose a semi-autonomous labeling method with humans in the loop to obtain the 3D ground truth for our dataset. The proposed dataset consists of 16.7 hours of paired music and 3D motion from in-the-wild videos, covering 7 dance styles and 16 music genres. We show that naively applying single dance generation technique to creating group dance motion may lead to unsatisfactory results, such as inconsistent movements and collisions between dancers. Based on our new dataset, we propose a new method that takes an input music sequence and a set of 3D positions of dancers to efficiently produce multiple group-coherent choreographies. We propose new evaluation metrics for measuring group dance quality and perform intensive experiments to demonstrate the effectiveness of our method. Our project facilitates future research on group dance generation and is available at: https://aioz-ai.github.io/AIOZ-GDANCE/
Style Transfer for 2D Talking Head Animation
Mar 22, 2023



Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
Addressing Non-IID Problem in Federated Autonomous Driving with Contrastive Divergence Loss
Mar 11, 2023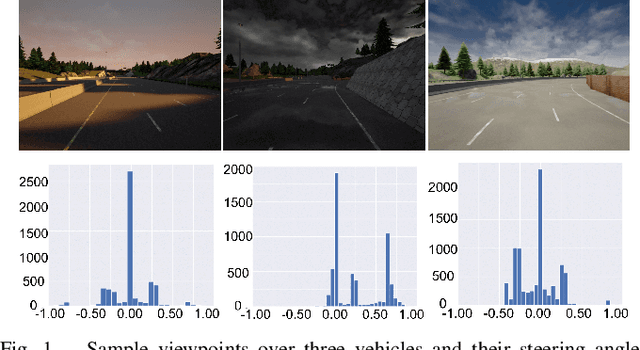
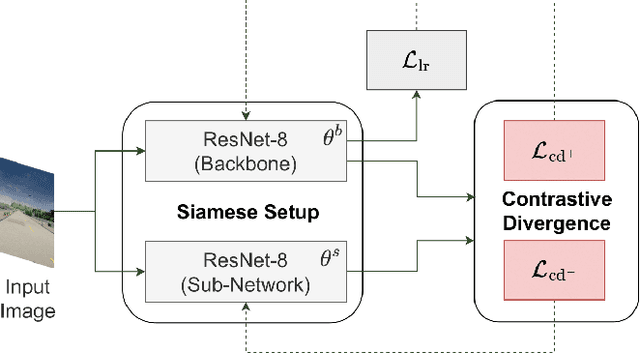
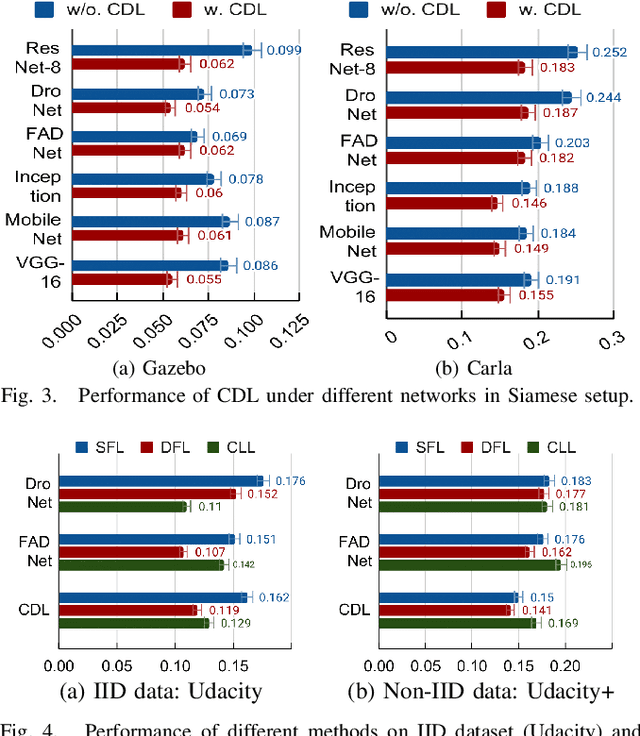
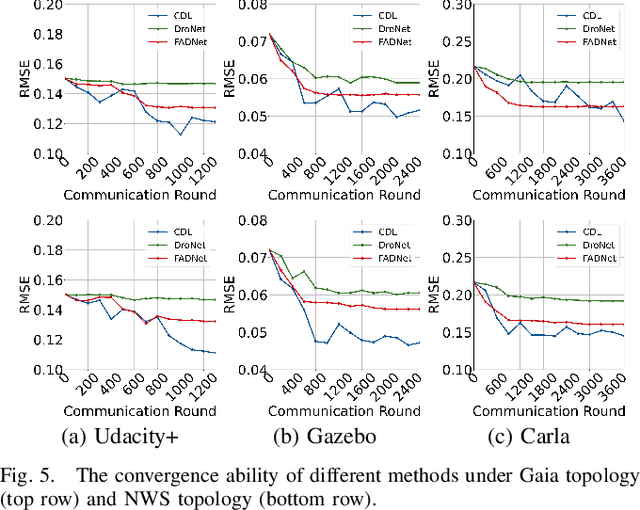
Federated learning has been widely applied in autonomous driving since it enables training a learning model among vehicles without sharing users' data. However, data from autonomous vehicles usually suffer from the non-independent-and-identically-distributed (non-IID) problem, which may cause negative effects on the convergence of the learning process. In this paper, we propose a new contrastive divergence loss to address the non-IID problem in autonomous driving by reducing the impact of divergence factors from transmitted models during the local learning process of each silo. We also analyze the effects of contrastive divergence in various autonomous driving scenarios, under multiple network infrastructures, and with different centralized/distributed learning schemes. Our intensive experiments on three datasets demonstrate that our proposed contrastive divergence loss further improves the performance over current state-of-the-art approaches.
Fine-Grained Visual Classification using Self Assessment Classifier
May 21, 2022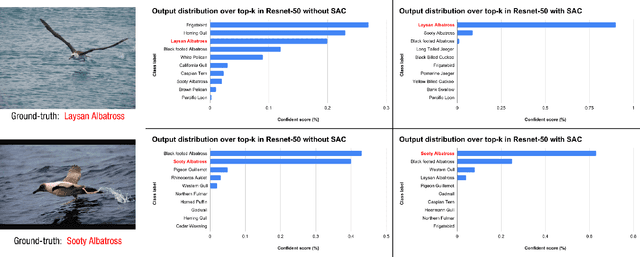
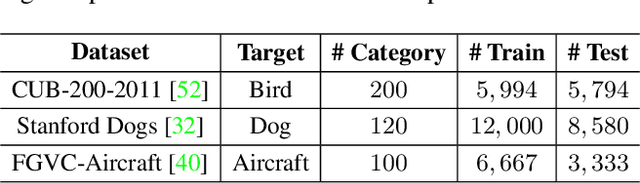
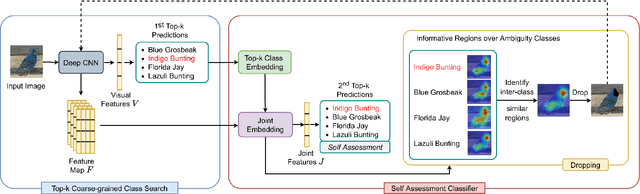
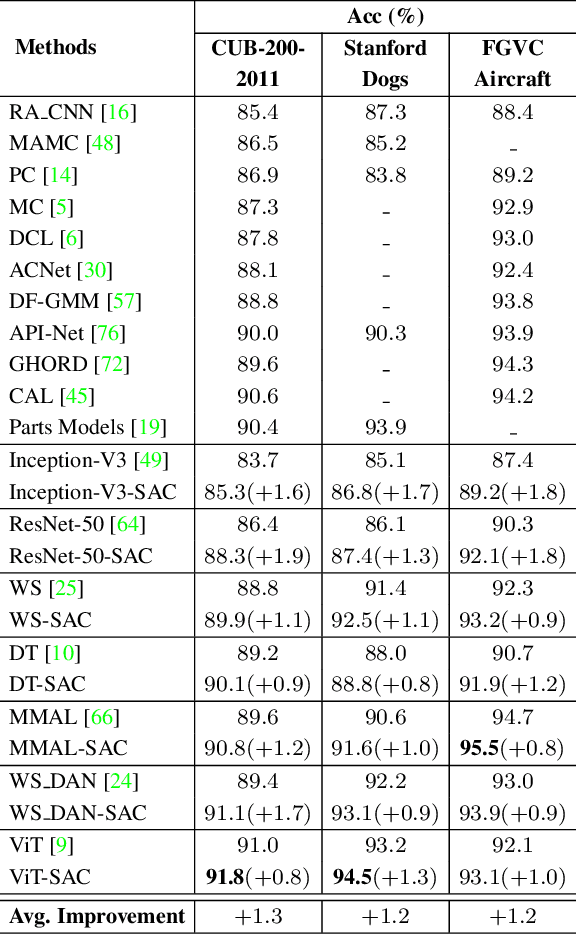
Extracting discriminative features plays a crucial role in the fine-grained visual classification task. Most of the existing methods focus on developing attention or augmentation mechanisms to achieve this goal. However, addressing the ambiguity in the top-k prediction classes is not fully investigated. In this paper, we introduce a Self Assessment Classifier, which simultaneously leverages the representation of the image and top-k prediction classes to reassess the classification results. Our method is inspired by continual learning with coarse-grained and fine-grained classifiers to increase the discrimination of features in the backbone and produce attention maps of informative areas on the image. In practice, our method works as an auxiliary branch and can be easily integrated into different architectures. We show that by effectively addressing the ambiguity in the top-k prediction classes, our method achieves new state-of-the-art results on CUB200-2011, Stanford Dog, and FGVC Aircraft datasets. Furthermore, our method also consistently improves the accuracy of different existing fine-grained classifiers with a unified setup.