 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore at Stake: How Payoff and Language Shape LLM Agent Strategies in Cooperation Dilemmas
Jan 27, 2026As LLMs increasingly act as autonomous agents in interactive and multi-agent settings, understanding their strategic behavior is critical for safety, coordination, and AI-driven social and economic systems. We investigate how payoff magnitude and linguistic context shape LLM strategies in repeated social dilemmas, using a payoff-scaled Prisoner's Dilemma to isolate sensitivity to incentive strength. Across models and languages, we observe consistent behavioral patterns, including incentive-sensitive conditional strategies and cross-linguistic divergence. To interpret these dynamics, we train supervised classifiers on canonical repeated-game strategies and apply them to LLM decisions, revealing systematic, model- and language-dependent behavioral intentions, with linguistic framing sometimes matching or exceeding architectural effects. Our results provide a unified framework for auditing LLMs as strategic agents and highlight cooperation biases with direct implications for AI governance and multi-agent system design.
Understanding LLM Agent Behaviours via Game Theory: Strategy Recognition, Biases and Multi-Agent Dynamics
Dec 11, 2025As Large Language Models (LLMs) increasingly operate as autonomous decision-makers in interactive and multi-agent systems and human societies, understanding their strategic behaviour has profound implications for safety, coordination, and the design of AI-driven social and economic infrastructures. Assessing such behaviour requires methods that capture not only what LLMs output, but the underlying intentions that guide their decisions. In this work, we extend the FAIRGAME framework to systematically evaluate LLM behaviour in repeated social dilemmas through two complementary advances: a payoff-scaled Prisoners Dilemma isolating sensitivity to incentive magnitude, and an integrated multi-agent Public Goods Game with dynamic payoffs and multi-agent histories. These environments reveal consistent behavioural signatures across models and languages, including incentive-sensitive cooperation, cross-linguistic divergence and end-game alignment toward defection. To interpret these patterns, we train traditional supervised classification models on canonical repeated-game strategies and apply them to FAIRGAME trajectories, showing that LLMs exhibit systematic, model- and language-dependent behavioural intentions, with linguistic framing at times exerting effects as strong as architectural differences. Together, these findings provide a unified methodological foundation for auditing LLMs as strategic agents and reveal systematic cooperation biases with direct implications for AI governance, collective decision-making, and the design of safe multi-agent systems.
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
Understanding Learning with Sliced-Wasserstein Requires Rethinking Informative Slices
Nov 16, 2024The practical applications of Wasserstein distances (WDs) are constrained by their sample and computational complexities. Sliced-Wasserstein distances (SWDs) provide a workaround by projecting distributions onto one-dimensional subspaces, leveraging the more efficient, closed-form WDs for one-dimensional distributions. However, in high dimensions, most random projections become uninformative due to the concentration of measure phenomenon. Although several SWD variants have been proposed to focus on \textit{informative} slices, they often introduce additional complexity, numerical instability, and compromise desirable theoretical (metric) properties of SWD. Amidst the growing literature that focuses on directly modifying the slicing distribution, which often face challenges, we revisit the classical Sliced-Wasserstein and propose instead to rescale the 1D Wasserstein to make all slices equally informative. Importantly, we show that with an appropriate data assumption and notion of \textit{slice informativeness}, rescaling for all individual slices simplifies to \textbf{a single global scaling factor} on the SWD. This, in turn, translates to the standard learning rate search for gradient-based learning in common machine learning workflows. We perform extensive experiments across various machine learning tasks showing that the classical SWD, when properly configured, can often match or surpass the performance of more complex variants. We then answer the following question: "Is Sliced-Wasserstein all you need for common learning tasks?"
Stereographic Spherical Sliced Wasserstein Distances
Feb 04, 2024



Comparing spherical probability distributions is of great interest in various fields, including geology, medical domains, computer vision, and deep representation learning. The utility of optimal transport-based distances, such as the Wasserstein distance, for comparing probability measures has spurred active research in developing computationally efficient variations of these distances for spherical probability measures. This paper introduces a high-speed and highly parallelizable distance for comparing spherical measures using the stereographic projection and the generalized Radon transform, which we refer to as the Stereographic Spherical Sliced Wasserstein (S3W) distance. We carefully address the distance distortion caused by the stereographic projection and provide an extensive theoretical analysis of our proposed metric and its rotationally invariant variation. Finally, we evaluate the performance of the proposed metrics and compare them with recent baselines in terms of both speed and accuracy through a wide range of numerical studies, including gradient flows and self-supervised learning.
Partial Transport for Point-Cloud Registration
Sep 27, 2023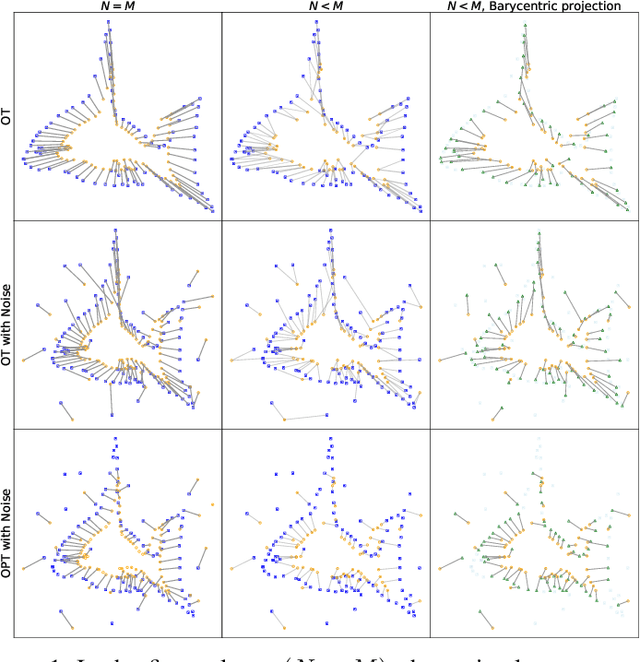
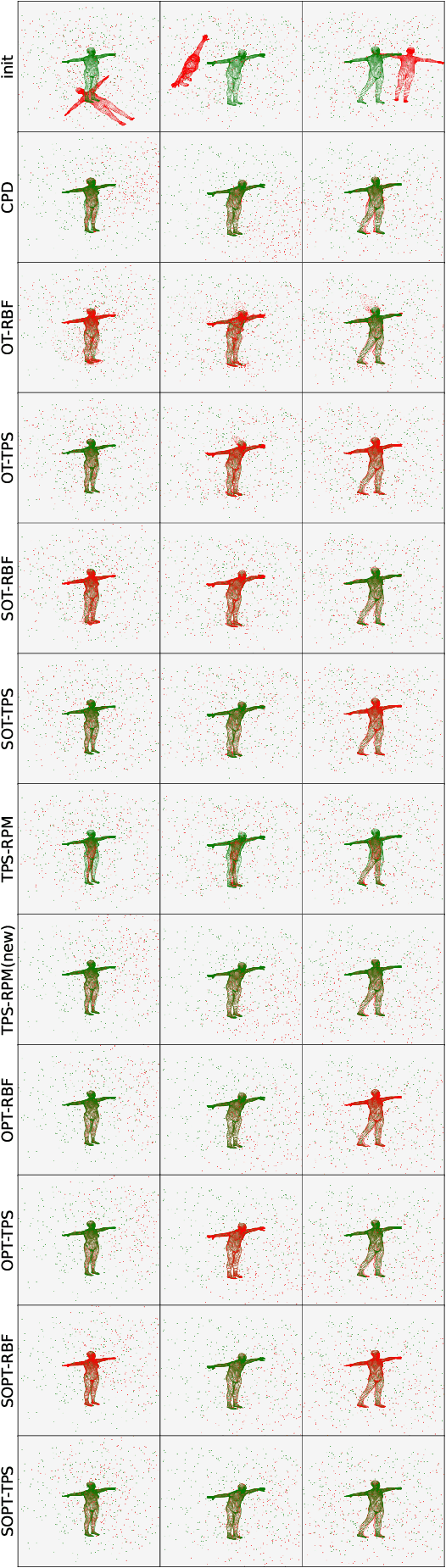
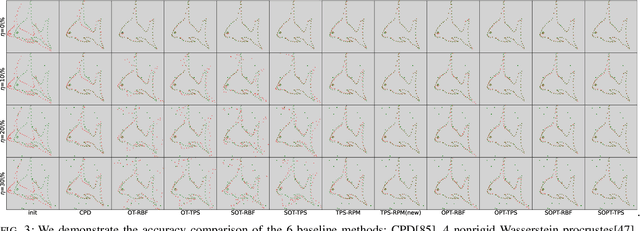
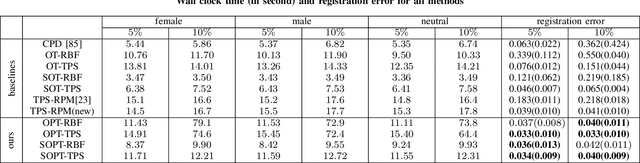
Point cloud registration plays a crucial role in various fields, including robotics, computer graphics, and medical imaging. This process involves determining spatial relationships between different sets of points, typically within a 3D space. In real-world scenarios, complexities arise from non-rigid movements and partial visibility, such as occlusions or sensor noise, making non-rigid registration a challenging problem. Classic non-rigid registration methods are often computationally demanding, suffer from unstable performance, and, importantly, have limited theoretical guarantees. The optimal transport problem and its unbalanced variations (e.g., the optimal partial transport problem) have emerged as powerful tools for point-cloud registration, establishing a strong benchmark in this field. These methods view point clouds as empirical measures and provide a mathematically rigorous way to quantify the `correspondence' between (the transformed) source and target points. In this paper, we approach the point-cloud registration problem through the lens of optimal transport theory and first propose a comprehensive set of non-rigid registration methods based on the optimal partial transportation problem. Subsequently, leveraging the emerging work on efficient solutions to the one-dimensional optimal partial transport problem, we extend our proposed algorithms via slicing to gain significant computational efficiency, resulting in fast and robust non-rigid registration algorithms. We demonstrate the effectiveness of our proposed methods and compare them against baselines on various 3D and 2D non-rigid registration problems where the source and target point clouds are corrupted by random noise.
PT$\mathrm{L}^{p}$: Partial Transport $\mathrm{L}^{p}$ Distances
Jul 25, 2023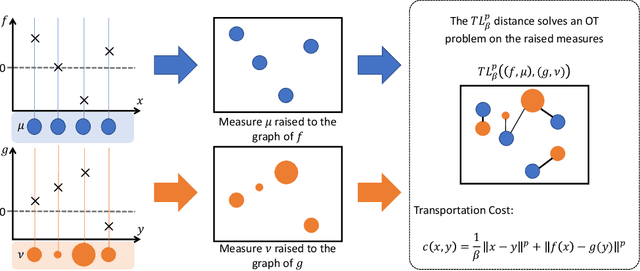
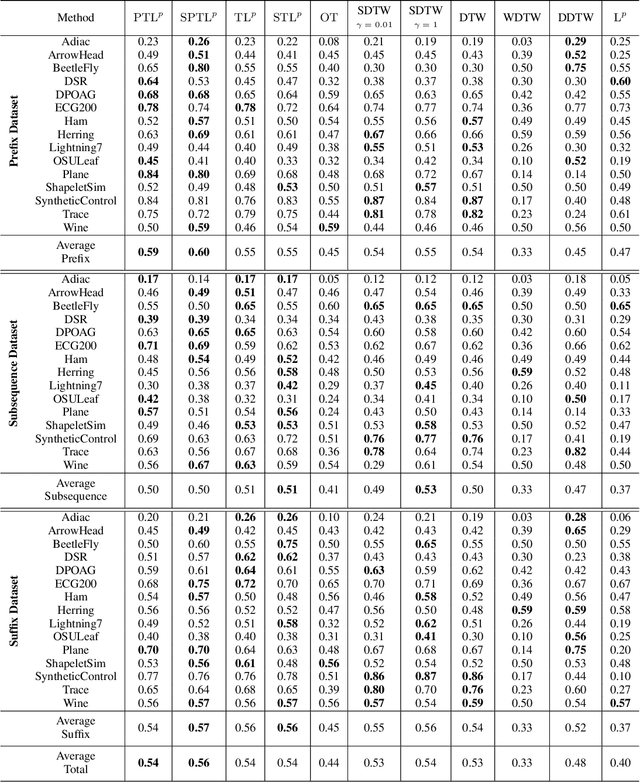


Optimal transport and its related problems, including optimal partial transport, have proven to be valuable tools in machine learning for computing meaningful distances between probability or positive measures. This success has led to a growing interest in defining transport-based distances that allow for comparing signed measures and, more generally, multi-channeled signals. Transport $\mathrm{L}^{p}$ distances are notable extensions of the optimal transport framework to signed and possibly multi-channeled signals. In this paper, we introduce partial transport $\mathrm{L}^{p}$ distances as a new family of metrics for comparing generic signals, benefiting from the robustness of partial transport distances. We provide theoretical background such as the existence of optimal plans and the behavior of the distance in various limits. Furthermore, we introduce the sliced variation of these distances, which allows for rapid comparison of generic signals. Finally, we demonstrate the application of the proposed distances in signal class separability and nearest neighbor classification.
A Simplified Framework for Contrastive Learning for Node Representations
May 01, 2023Contrastive learning has recently established itself as a powerful self-supervised learning framework for extracting rich and versatile data representations. Broadly speaking, contrastive learning relies on a data augmentation scheme to generate two versions of the input data and learns low-dimensional representations by maximizing a normalized temperature-scaled cross entropy loss (NT-Xent) to identify augmented samples corresponding to the same original entity. In this paper, we investigate the potential of deploying contrastive learning in combination with Graph Neural Networks for embedding nodes in a graph. Specifically, we show that the quality of the resulting embeddings and training time can be significantly improved by a simple column-wise postprocessing of the embedding matrix, instead of the row-wise postprocessing via multilayer perceptrons (MLPs) that is adopted by the majority of peer methods. This modification yields improvements in downstream classification tasks of up to 1.5% and even beats existing state-of-the-art approaches on 6 out of 8 different benchmarks. We justify our choices of postprocessing by revisiting the "alignment vs. uniformity paradigm", and show that column-wise post-processing improves both "alignment" and "uniformity" of the embeddings.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
Is Multi-Task Learning an Upper Bound for Continual Learning?
Oct 26, 2022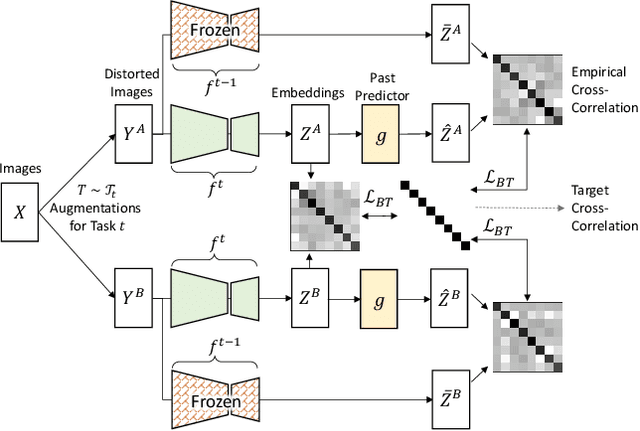

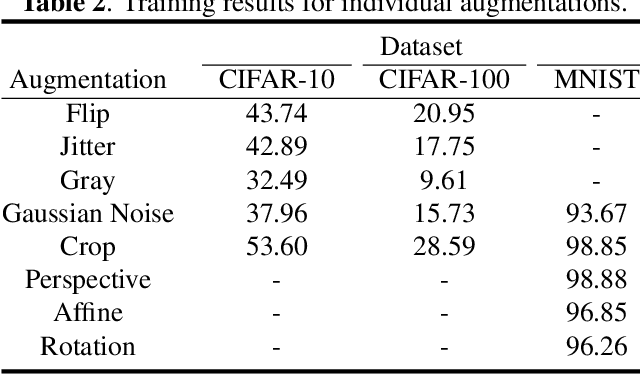
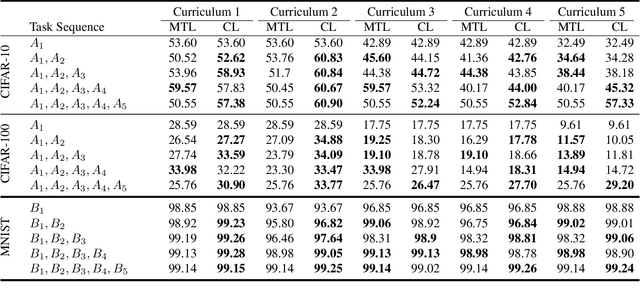
Continual and multi-task learning are common machine learning approaches to learning from multiple tasks. The existing works in the literature often assume multi-task learning as a sensible performance upper bound for various continual learning algorithms. While this assumption is empirically verified for different continual learning benchmarks, it is not rigorously justified. Moreover, it is imaginable that when learning from multiple tasks, a small subset of these tasks could behave as adversarial tasks reducing the overall learning performance in a multi-task setting. In contrast, continual learning approaches can avoid the performance drop caused by such adversarial tasks to preserve their performance on the rest of the tasks, leading to better performance than a multi-task learner. This paper proposes a novel continual self-supervised learning setting, where each task corresponds to learning an invariant representation for a specific class of data augmentations. In this setting, we show that continual learning often beats multi-task learning on various benchmark datasets, including MNIST, CIFAR-10, and CIFAR-100.