 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Partial Gromov-Wasserstein Embedding
Oct 22, 2024



The Gromov Wasserstein (GW) problem, a variant of the classical optimal transport (OT) problem, has attracted growing interest in the machine learning and data science communities due to its ability to quantify similarity between measures in different metric spaces. However, like the classical OT problem, GW imposes an equal mass constraint between measures, which restricts its application in many machine learning tasks. To address this limitation, the partial Gromov-Wasserstein (PGW) problem has been introduced, which relaxes the equal mass constraint, enabling the comparison of general positive Radon measures. Despite this, both GW and PGW face significant computational challenges due to their non-convex nature. To overcome these challenges, we propose the linear partial Gromov-Wasserstein (LPGW) embedding, a linearized embedding technique for the PGW problem. For $K$ different metric measure spaces, the pairwise computation of the PGW distance requires solving the PGW problem $\mathcal{O}(K^2)$ times. In contrast, the proposed linearization technique reduces this to $\mathcal{O}(K)$ times. Similar to the linearization technique for the classical OT problem, we prove that LPGW defines a valid metric for metric measure spaces. Finally, we demonstrate the effectiveness of LPGW in practical applications such as shape retrieval and learning with transport-based embeddings, showing that LPGW preserves the advantages of PGW in partial matching while significantly enhancing computational efficiency.
Efficient Solvers for Partial Gromov-Wasserstein
Feb 06, 2024



The partial Gromov-Wasserstein (PGW) problem facilitates the comparison of measures with unequal masses residing in potentially distinct metric spaces, thereby enabling unbalanced and partial matching across these spaces. In this paper, we demonstrate that the PGW problem can be transformed into a variant of the Gromov-Wasserstein problem, akin to the conversion of the partial optimal transport problem into an optimal transport problem. This transformation leads to two new solvers, mathematically and computationally equivalent, based on the Frank-Wolfe algorithm, that provide efficient solutions to the PGW problem. We further establish that the PGW problem constitutes a metric for metric measure spaces. Finally, we validate the effectiveness of our proposed solvers in terms of computation time and performance on shape-matching and positive-unlabeled learning problems, comparing them against existing baselines.
Stereographic Spherical Sliced Wasserstein Distances
Feb 04, 2024



Comparing spherical probability distributions is of great interest in various fields, including geology, medical domains, computer vision, and deep representation learning. The utility of optimal transport-based distances, such as the Wasserstein distance, for comparing probability measures has spurred active research in developing computationally efficient variations of these distances for spherical probability measures. This paper introduces a high-speed and highly parallelizable distance for comparing spherical measures using the stereographic projection and the generalized Radon transform, which we refer to as the Stereographic Spherical Sliced Wasserstein (S3W) distance. We carefully address the distance distortion caused by the stereographic projection and provide an extensive theoretical analysis of our proposed metric and its rotationally invariant variation. Finally, we evaluate the performance of the proposed metrics and compare them with recent baselines in terms of both speed and accuracy through a wide range of numerical studies, including gradient flows and self-supervised learning.
LCOT: Linear circular optimal transport
Oct 09, 2023



The optimal transport problem for measures supported on non-Euclidean spaces has recently gained ample interest in diverse applications involving representation learning. In this paper, we focus on circular probability measures, i.e., probability measures supported on the unit circle, and introduce a new computationally efficient metric for these measures, denoted as Linear Circular Optimal Transport (LCOT). The proposed metric comes with an explicit linear embedding that allows one to apply Machine Learning (ML) algorithms to the embedded measures and seamlessly modify the underlying metric for the ML algorithm to LCOT. We show that the proposed metric is rooted in the Circular Optimal Transport (COT) and can be considered the linearization of the COT metric with respect to a fixed reference measure. We provide a theoretical analysis of the proposed metric and derive the computational complexities for pairwise comparison of circular probability measures. Lastly, through a set of numerical experiments, we demonstrate the benefits of LCOT in learning representations of circular measures.
Linear Optimal Partial Transport Embedding
Feb 08, 2023Optimal transport (OT) has gained popularity due to its various applications in fields such as machine learning, statistics, and signal processing. However, the balanced mass requirement limits its performance in practical problems. To address these limitations, variants of the OT problem, including unbalanced OT, Optimal partial transport (OPT), and Hellinger Kantorovich (HK), have been proposed. In this paper, we propose the Linear optimal partial transport (LOPT) embedding, which extends the (local) linearization technique on OT and HK to the OPT problem. The proposed embedding allows for faster computation of OPT distance between pairs of positive measures. Besides our theoretical contributions, we demonstrate the LOPT embedding technique in point-cloud interpolation and PCA analysis.
Signed Cumulative Distribution Transform for Parameter Estimation of 1-D Signals
Jul 16, 2022

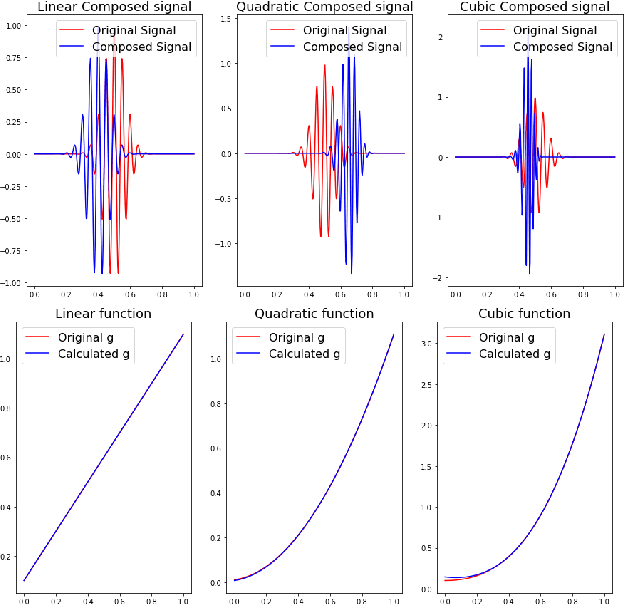
We describe a method for signal parameter estimation using the signed cumulative distribution transform (SCDT), a recently introduced signal representation tool based on optimal transport theory. The method builds upon signal estimation using the cumulative distribution transform (CDT) originally introduced for positive distributions. Specifically, we show that Wasserstein-type distance minimization can be performed simply using linear least squares techniques in SCDT space for arbitrary signal classes, thus providing a global minimizer for the estimation problem even when the underlying signal is a nonlinear function of the unknown parameters. Comparisons to current signal estimation methods using $L_p$ minimization shows the advantage of the method.
The Signed Cumulative Distribution Transform for 1-D Signal Analysis and Classification
Jun 03, 2021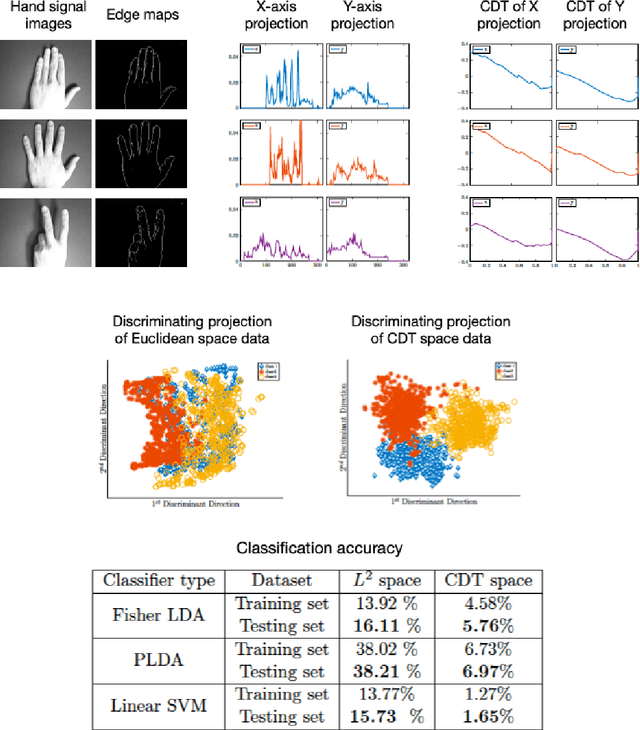
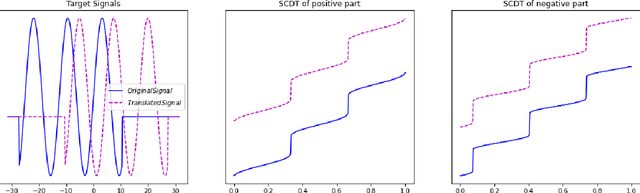

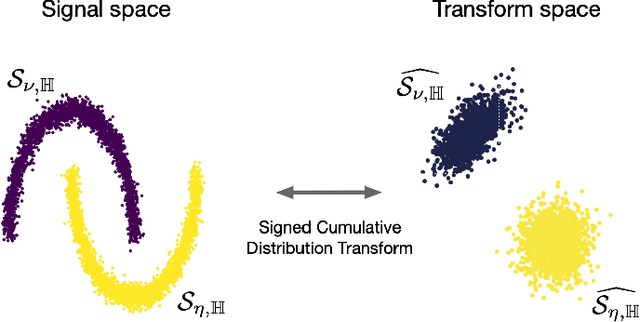
This paper presents a new mathematical signal transform that is especially suitable for decoding information related to non-rigid signal displacements. We provide a measure theoretic framework to extend the existing Cumulative Distribution Transform [ACHA 45 (2018), no. 3, 616-641] to arbitrary (signed) signals on $\overline{\mathbb{R}}$. We present both forward (analysis) and inverse (synthesis) formulas for the transform, and describe several of its properties including translation, scaling, convexity, linear separability and others. Finally, we describe a metric in transform space, and demonstrate the application of the transform in classifying (detecting) signals under random displacements.