 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Natural Language Proof Checking in Introduction to Proof Classes -- First Experiences with Diproche
Feb 08, 2022



We present and analyze the employment of the Diproche system, a natural language proof checker, within a one-semester mathematics beginners lecture with 228 participants. The system is used to check the students' solution attempts to proving exercises in Boolean set theory and elementary number theory and to give them immediate feedback. The benefits of the employment of the system are assessed via a questionnaire at the end of the semester and via analyzing the solution attempts of a subgroup of the students. Based on our results we develop approaches for future improvements.
* In Proceedings ThEdu'21, arXiv:2202.02144
From 'F' to 'A' on the N.Y. Regents Science Exams: An Overview of the Aristo Project
Sep 11, 2019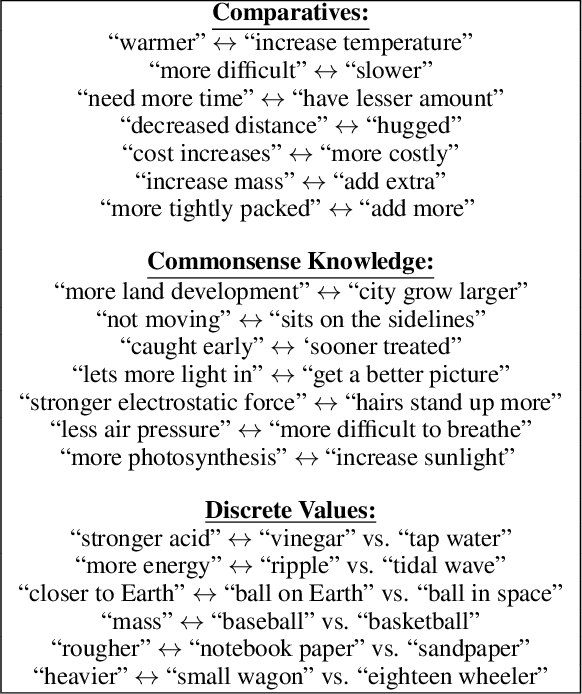
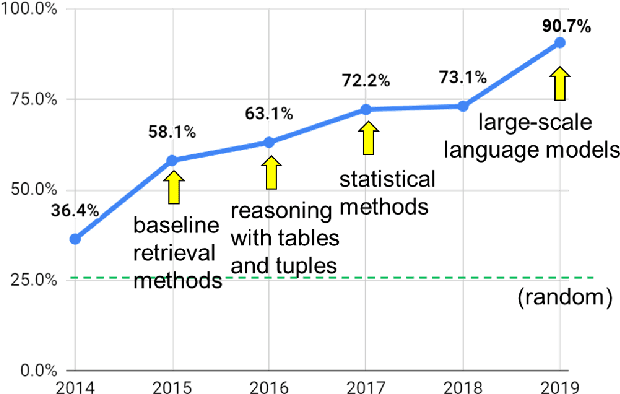

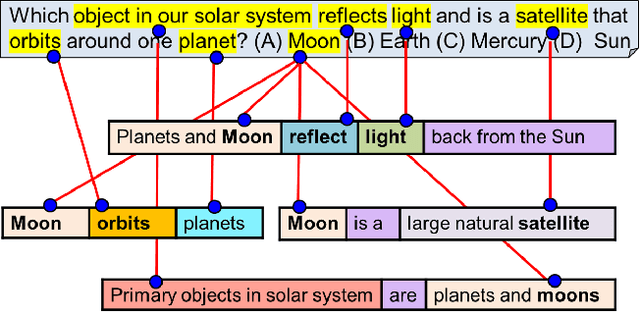
AI has achieved remarkable mastery over games such as Chess, Go, and Poker, and even Jeopardy, but the rich variety of standardized exams has remained a landmark challenge. Even in 2016, the best AI system achieved merely 59.3% on an 8th Grade science exam challenge. This paper reports unprecedented success on the Grade 8 New York Regents Science Exam, where for the first time a system scores more than 90% on the exam's non-diagram, multiple choice (NDMC) questions. In addition, our Aristo system, building upon the success of recent language models, exceeded 83% on the corresponding Grade 12 Science Exam NDMC questions. The results, on unseen test questions, are robust across different test years and different variations of this kind of test. They demonstrate that modern NLP methods can result in mastery on this task. While not a full solution to general question-answering (the questions are multiple choice, and the domain is restricted to 8th Grade science), it represents a significant milestone for the field.
AllenNLP: A Deep Semantic Natural Language Processing Platform
May 31, 2018This paper describes AllenNLP, a platform for research on deep learning methods in natural language understanding. AllenNLP is designed to support researchers who want to build novel language understanding models quickly and easily. It is built on top of PyTorch, allowing for dynamic computation graphs, and provides (1) a flexible data API that handles intelligent batching and padding, (2) high-level abstractions for common operations in working with text, and (3) a modular and extensible experiment framework that makes doing good science easy. It also includes reference implementations of high quality approaches for both core semantic problems (e.g. semantic role labeling (Palmer et al., 2005)) and language understanding applications (e.g. machine comprehension (Rajpurkar et al., 2016)). AllenNLP is an ongoing open-source effort maintained by engineers and researchers at the Allen Institute for Artificial Intelligence.