 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text
Dec 01, 2021Communicating with humans is challenging for AIs because it requires a shared understanding of the world, complex semantics (e.g., metaphors or analogies), and at times multi-modal gestures (e.g., pointing with a finger, or an arrow in a diagram). We investigate these challenges in the context of Iconary, a collaborative game of drawing and guessing based on Pictionary, that poses a novel challenge for the research community. In Iconary, a Guesser tries to identify a phrase that a Drawer is drawing by composing icons, and the Drawer iteratively revises the drawing to help the Guesser in response. This back-and-forth often uses canonical scenes, visual metaphor, or icon compositions to express challenging words, making it an ideal test for mixing language and visual/symbolic communication in AI. We propose models to play Iconary and train them on over 55,000 games between human players. Our models are skillful players and are able to employ world knowledge in language models to play with words unseen during training. Elite human players outperform our models, particularly at the drawing task, leaving an important gap for future research to address. We release our dataset, code, and evaluation setup as a challenge to the community at http://www.github.com/allenai/iconary.
Think you have Solved Direct-Answer Question Answering? Try ARC-DA, the Direct-Answer AI2 Reasoning Challenge
Feb 05, 2021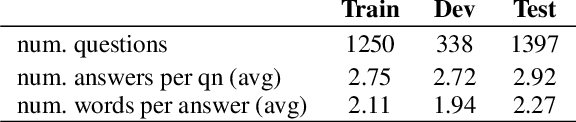
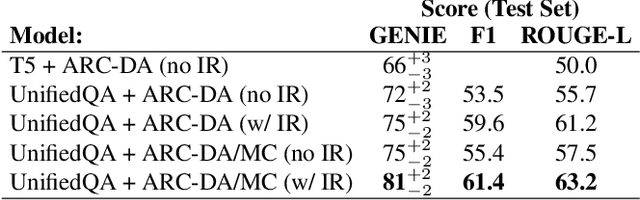
We present the ARC-DA dataset, a direct-answer ("open response", "freeform") version of the ARC (AI2 Reasoning Challenge) multiple-choice dataset. While ARC has been influential in the community, its multiple-choice format is unrepresentative of real-world questions, and multiple choice formats can be particularly susceptible to artifacts. The ARC-DA dataset addresses these concerns by converting questions to direct-answer format using a combination of crowdsourcing and expert review. The resulting dataset contains 2985 questions with a total of 8436 valid answers (questions typically have more than one valid answer). ARC-DA is one of the first DA datasets of natural questions that often require reasoning, and where appropriate question decompositions are not evident from the questions themselves. We describe the conversion approach taken, appropriate evaluation metrics, and several strong models. Although high, the best scores (81% GENIE, 61.4% F1, 63.2% ROUGE-L) still leave considerable room for improvement. In addition, the dataset provides a natural setting for new research on explanation, as many questions require reasoning to construct answers. We hope the dataset spurs further advances in complex question-answering by the community. ARC-DA is available at https://allenai.org/data/arc-da
Extracting evidence of supplement-drug interactions from literature
Sep 17, 2019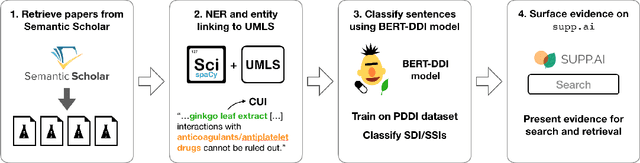
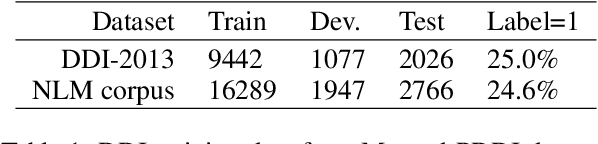
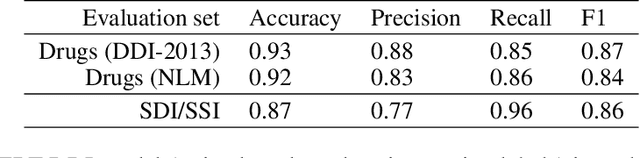
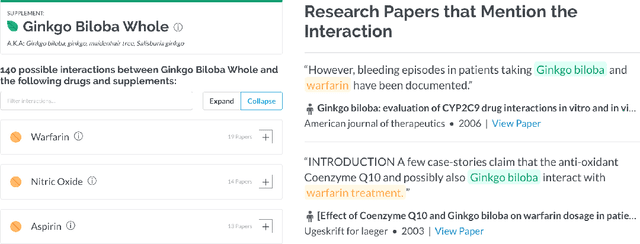
Dietary supplements are used by a large portion of the population, but information on their safety is hard to find. We demonstrate an automated method for extracting evidence of supplement-drug interactions (SDIs) and supplement-supplement interactions (SSIs) from scientific text. To address the lack of labeled data in this domain, we use labels of the closely related task of identifying drug-drug interactions (DDIs) for supervision, and assess the feasibility of transferring the model to identify supplement interactions. We fine-tune the contextualized word representations of BERT-large using labeled data from the PDDI corpus. We then process 22M abstracts from PubMed using this model, and extract evidence for 55946 unique interactions between 1923 supplements and 2727 drugs (precision: 0.77, recall: 0.96), demonstrating that learning the task of DDI classification transfers successfully to the related problem of identifying SDIs and SSIs. As far as we know, this is the first published work on detecting evidence of SDIs/SSIs from literature. We implement a freely-available public interface supp.ai to browse and search evidence sentences extracted by our model.
From 'F' to 'A' on the N.Y. Regents Science Exams: An Overview of the Aristo Project
Sep 11, 2019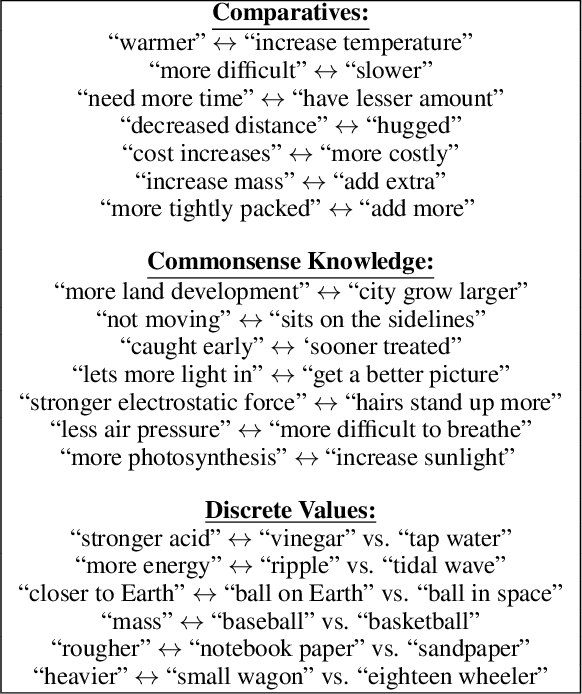
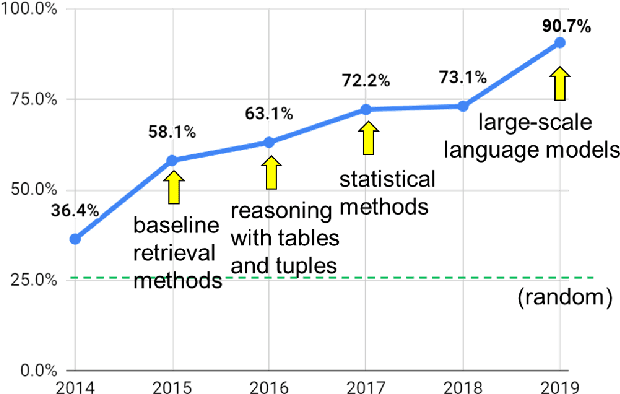

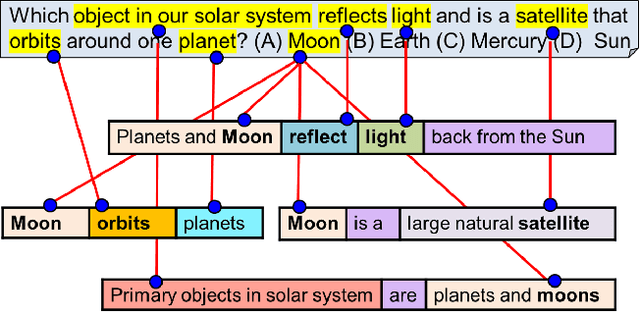
AI has achieved remarkable mastery over games such as Chess, Go, and Poker, and even Jeopardy, but the rich variety of standardized exams has remained a landmark challenge. Even in 2016, the best AI system achieved merely 59.3% on an 8th Grade science exam challenge. This paper reports unprecedented success on the Grade 8 New York Regents Science Exam, where for the first time a system scores more than 90% on the exam's non-diagram, multiple choice (NDMC) questions. In addition, our Aristo system, building upon the success of recent language models, exceeded 83% on the corresponding Grade 12 Science Exam NDMC questions. The results, on unseen test questions, are robust across different test years and different variations of this kind of test. They demonstrate that modern NLP methods can result in mastery on this task. While not a full solution to general question-answering (the questions are multiple choice, and the domain is restricted to 8th Grade science), it represents a significant milestone for the field.
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Mar 14, 2018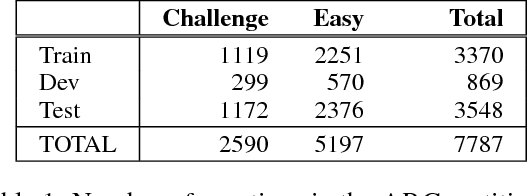
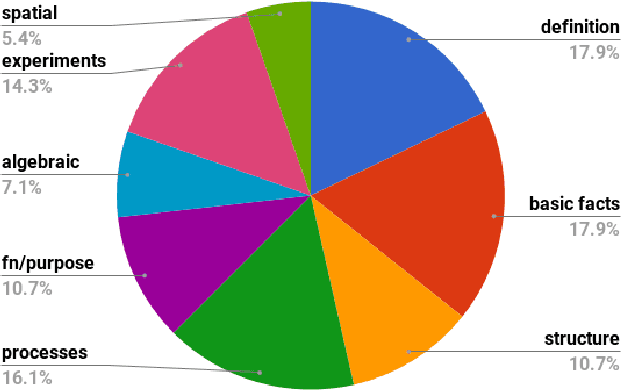
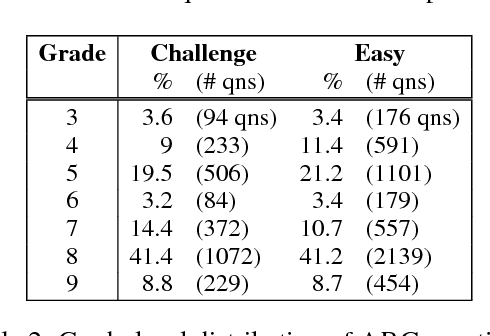
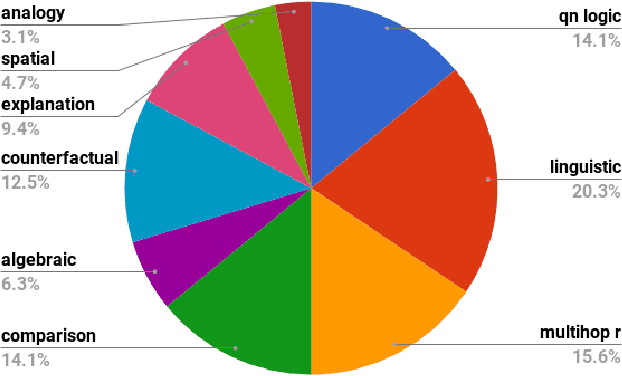
We present a new question set, text corpus, and baselines assembled to encourage AI research in advanced question answering. Together, these constitute the AI2 Reasoning Challenge (ARC), which requires far more powerful knowledge and reasoning than previous challenges such as SQuAD or SNLI. The ARC question set is partitioned into a Challenge Set and an Easy Set, where the Challenge Set contains only questions answered incorrectly by both a retrieval-based algorithm and a word co-occurence algorithm. The dataset contains only natural, grade-school science questions (authored for human tests), and is the largest public-domain set of this kind (7,787 questions). We test several baselines on the Challenge Set, including leading neural models from the SQuAD and SNLI tasks, and find that none are able to significantly outperform a random baseline, reflecting the difficult nature of this task. We are also releasing the ARC Corpus, a corpus of 14M science sentences relevant to the task, and implementations of the three neural baseline models tested. Can your model perform better? We pose ARC as a challenge to the community.
Moving Beyond the Turing Test with the Allen AI Science Challenge
Feb 22, 2017Given recent successes in AI (e.g., AlphaGo's victory against Lee Sedol in the game of GO), it's become increasingly important to assess: how close are AI systems to human-level intelligence? This paper describes the Allen AI Science Challenge---an approach towards that goal which led to a unique Kaggle Competition, its results, the lessons learned, and our next steps.