 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning
Dec 15, 2025As humans, we are natural any-horizon reasoners, i.e., we can decide whether to iteratively skim long videos or watch short ones in full when necessary for a given task. With this in mind, one would expect video reasoning models to reason flexibly across different durations. However, SOTA models are still trained to predict answers in a single turn while processing a large number of frames, akin to watching an entire long video, requiring significant resources. This raises the question: Is it possible to develop performant any-horizon video reasoning systems? Inspired by human behavior, we first propose SAGE, an agent system that performs multi-turn reasoning on long videos while handling simpler problems in a single turn. Secondly, we introduce an easy synthetic data generation pipeline using Gemini-2.5-Flash to train the orchestrator, SAGE-MM, which lies at the core of SAGE. We further propose an effective RL post-training recipe essential for instilling any-horizon reasoning ability in SAGE-MM. Thirdly, we curate SAGE-Bench with an average duration of greater than 700 seconds for evaluating video reasoning ability in real-world entertainment use cases. Lastly, we empirically validate the effectiveness of our system, data, and RL recipe, observing notable improvements of up to 6.1% on open-ended video reasoning tasks, as well as an impressive 8.2% improvement on videos longer than 10 minutes.
HinTel-AlignBench: A Framework and Benchmark for Hindi-Telugu with English-Aligned Samples
Nov 19, 2025With nearly 1.5 billion people and more than 120 major languages, India represents one of the most diverse regions in the world. As multilingual Vision-Language Models (VLMs) gain prominence, robust evaluation methodologies are essential to drive progress toward equitable AI for low-resource languages. Current multilingual VLM evaluations suffer from four major limitations: reliance on unverified auto-translations, narrow task/domain coverage, limited sample sizes, and lack of cultural and natively sourced Question-Answering (QA). To address these gaps, we present a scalable framework to evaluate VLMs in Indian languages and compare it with performance in English. Using the framework, we generate HinTel-AlignBench, a benchmark that draws from diverse sources in Hindi and Telugu with English-aligned samples. Our contributions are threefold: (1) a semi-automated dataset creation framework combining back-translation, filtering, and human verification; (2) the most comprehensive vision-language benchmark for Hindi and and Telugu, including adapted English datasets (VQAv2, RealWorldQA, CLEVR-Math) and native novel Indic datasets (JEE for STEM, VAANI for cultural grounding) with approximately 4,000 QA pairs per language; and (3) a detailed performance analysis of various State-of-the-Art (SOTA) open-weight and closed-source VLMs. We find a regression in performance for tasks in English versus in Indian languages for 4 out of 5 tasks across all the models, with an average regression of 8.3 points in Hindi and 5.5 points for Telugu. We categorize common failure modes to highlight concrete areas of improvement in multilingual multimodal understanding.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
ModEFormer: Modality-Preserving Embedding for Audio-Video Synchronization using Transformers
Mar 21, 2023Lack of audio-video synchronization is a common problem during television broadcasts and video conferencing, leading to an unsatisfactory viewing experience. A widely accepted paradigm is to create an error detection mechanism that identifies the cases when audio is leading or lagging. We propose ModEFormer, which independently extracts audio and video embeddings using modality-specific transformers. Different from the other transformer-based approaches, ModEFormer preserves the modality of the input streams which allows us to use a larger batch size with more negative audio samples for contrastive learning. Further, we propose a trade-off between the number of negative samples and number of unique samples in a batch to significantly exceed the performance of previous methods. Experimental results show that ModEFormer achieves state-of-the-art performance, 94.5% for LRS2 and 90.9% for LRS3. Finally, we demonstrate how ModEFormer can be used for offset detection for test clips.
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020

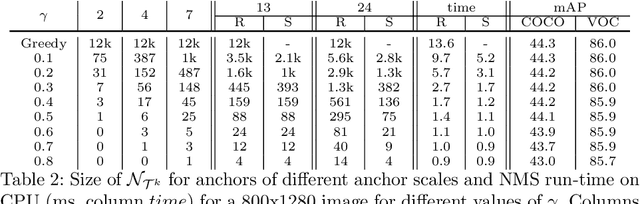

The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.
RSO: A Gradient Free Sampling Based Approach For Training Deep Neural Networks
May 12, 2020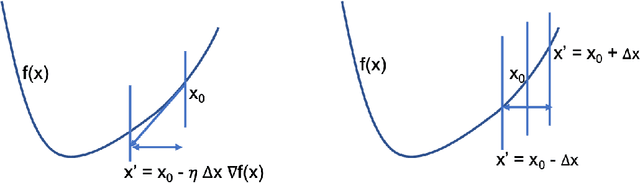


We propose RSO (random search optimization), a gradient free Markov Chain Monte Carlo search based approach for training deep neural networks. To this end, RSO adds a perturbation to a weight in a deep neural network and tests if it reduces the loss on a mini-batch. If this reduces the loss, the weight is updated, otherwise the existing weight is retained. Surprisingly, we find that repeating this process a few times for each weight is sufficient to train a deep neural network. The number of weight updates for RSO is an order of magnitude lesser when compared to backpropagation with SGD. RSO can make aggressive weight updates in each step as there is no concept of learning rate. The weight update step for individual layers is also not coupled with the magnitude of the loss. RSO is evaluated on classification tasks on MNIST and CIFAR-10 datasets with deep neural networks of 6 to 10 layers where it achieves an accuracy of 99.1% and 81.8% respectively. We also find that after updating the weights just 5 times, the algorithm obtains a classification accuracy of 98% on MNIST.
Semantic Segmentation with Scarce Data
Aug 02, 2018

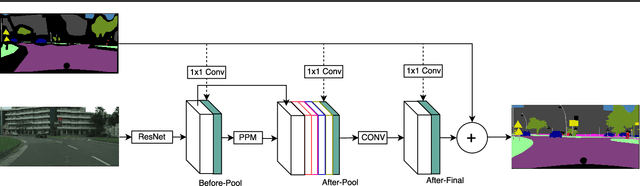

Semantic segmentation is a challenging vision problem that usually necessitates the collection of large amounts of finely annotated data, which is often quite expensive to obtain. Coarsely annotated data provides an interesting alternative as it is usually substantially more cheap. In this work, we present a method to leverage coarsely annotated data along with fine supervision to produce better segmentation results than would be obtained when training using only the fine data. We validate our approach by simulating a scarce data setting with less than 200 low resolution images from the Cityscapes dataset and show that our method substantially outperforms solely training on the fine annotation data by an average of 15.52% mIoU and outperforms the coarse mask by an average of 5.28% mIoU.
Recurrent neural networks based Indic word-wise script identification using character-wise training
Sep 11, 2017

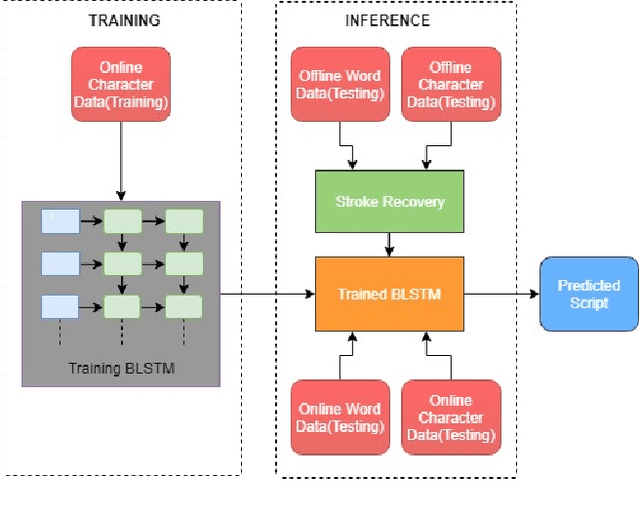

This paper presents a novel methodology of Indic handwritten script recognition using Recurrent Neural Networks and addresses the problem of script recognition in poor data scenarios, such as when only character level online data is available. It is based on the hypothesis that curves of online character data comprise sufficient information for prediction at the word level. Online character data is used to train RNNs using BLSTM architecture which are then used to make predictions of online word level data. These prediction results on the test set are at par with prediction results of models trained with online word data, while the training of the character level model is much less data intensive and takes much less time. Performance for binary-script models and then 5 Indic script models are reported, along with comparison with HMM models.The system is extended for offline data prediction. Raw offline data lacks the temporal information available in online data and required for prediction using models trained with online data. To overcome this, stroke recovery is implemented and the strokes are utilized for predicting using the online character level models. The performance on character and word level offline data is reported.