 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoB0T: Large-Scale Simulation Enables Zero-Shot Manipulation
Mar 17, 2026A prevailing view in robot learning is that simulation alone is not enough; effective sim-to-real transfer is widely believed to require at least some real-world data collection or task-specific fine-tuning to bridge the gap between simulated and physical environments. We challenge that assumption. With sufficiently large-scale and diverse simulated synthetic training data, we show that zero-shot transfer to the real world is not only possible, but effective for both static and mobile manipulation. We introduce MolmoBot-Engine, a fully open-source pipeline for procedural data generation across robots, tasks, and diverse simulated environments in MolmoSpaces. With it, we release MolmoBot-Data, a dataset of 1.8 million expert trajectories for articulated object manipulation and pick-and-place tasks. We train three policy classes: MolmoBot, a Molmo2-based multi-frame vision-language model with a flow-matching action head; MolmoBot-Pi0, which replicates the $π_0$ architecture to enable direct comparison; and MolmoBot-SPOC, a lightweight policy suitable for edge deployment and amenable to RL fine-tuning. We evaluate on two robotic platforms: the Franka FR3 for tabletop manipulation tasks and the Rainbow Robotics RB-Y1 mobile manipulator for door opening, drawer manipulation, cabinet interaction, and mobile pick-and-place. Without any real-world fine-tuning, our policies achieve zero-shot transfer to unseen objects and environments. On tabletop pick-and-place, MolmoBot achieves a success rate of 79.2% in real world evaluations across 4 settings, outperforming $π_{0.5}$ at 39.2%. Our results demonstrate that procedural environment generation combined with diverse articulated assets can produce robust manipulation policies that generalize broadly to the real world. Technical Blog: https://allenai.org/blog/molmobot-robot-manipulation
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Feb 11, 2026Deploying robots at scale demands robustness to the long tail of everyday situations. The countless variations in scene layout, object geometry, and task specifications that characterize real environments are vast and underrepresented in existing robot benchmarks. Measuring this level of generalization requires infrastructure at a scale and diversity that physical evaluation alone cannot provide. We introduce MolmoSpaces, a fully open ecosystem to support large-scale benchmarking of robot policies. MolmoSpaces consists of over 230k diverse indoor environments, ranging from handcrafted household scenes to procedurally generated multiroom houses, populated with 130k richly annotated object assets, including 48k manipulable objects with 42M stable grasps. Crucially, these environments are simulator-agnostic, supporting popular options such as MuJoCo, Isaac, and ManiSkill. The ecosystem supports the full spectrum of embodied tasks: static and mobile manipulation, navigation, and multiroom long-horizon tasks requiring coordinated perception, planning, and interaction across entire indoor environments. We also design MolmoSpaces-Bench, a benchmark suite of 8 tasks in which robots interact with our diverse scenes and richly annotated objects. Our experiments show MolmoSpaces-Bench exhibits strong sim-to-real correlation (R = 0.96, \r{ho} = 0.98), confirm newer and stronger zero-shot policies outperform earlier versions in our benchmarks, and identify key sensitivities to prompt phrasing, initial joint positions, and camera occlusion. Through MolmoSpaces and its open-source assets and tooling, we provide a foundation for scalable data generation, policy training, and benchmark creation for robot learning research.
GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
May 19, 2025We present GrasMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame. For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation, which, along with videos, are available at https://abhaybd.github.io/GraspMolmo/.
The One RING: a Robotic Indoor Navigation Generalist
Dec 18, 2024



Modern robots vary significantly in shape, size, and sensor configurations used to perceive and interact with their environments. However, most navigation policies are embodiment-specific; a policy learned using one robot's configuration does not typically gracefully generalize to another. Even small changes in the body size or camera viewpoint may cause failures. With the recent surge in custom hardware developments, it is necessary to learn a single policy that can be transferred to other embodiments, eliminating the need to (re)train for each specific robot. In this paper, we introduce RING (Robotic Indoor Navigation Generalist), an embodiment-agnostic policy, trained solely in simulation with diverse randomly initialized embodiments at scale. Specifically, we augment the AI2-THOR simulator with the ability to instantiate robot embodiments with controllable configurations, varying across body size, rotation pivot point, and camera configurations. In the visual object-goal navigation task, RING achieves robust performance on real unseen robot platforms (Stretch RE-1, LoCoBot, Unitree's Go1), achieving an average of 72.1% and 78.9% success rate across 5 embodiments in simulation and 4 robot platforms in the real world. (project website: https://one-ring-policy.allen.ai/)
PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
Jun 28, 2024



We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real-world without adaptation despite being trained purely in simulation. PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning. It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput. PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks. It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the CHORES-S benchmark, a 28.5% absolute improvement. PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.
Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Dec 05, 2023



Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extensive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES will be open-sourced.
Objaverse: A Universe of Annotated 3D Objects
Dec 15, 2022Massive data corpora like WebText, Wikipedia, Conceptual Captions, WebImageText, and LAION have propelled recent dramatic progress in AI. Large neural models trained on such datasets produce impressive results and top many of today's benchmarks. A notable omission within this family of large-scale datasets is 3D data. Despite considerable interest and potential applications in 3D vision, datasets of high-fidelity 3D models continue to be mid-sized with limited diversity of object categories. Addressing this gap, we present Objaverse 1.0, a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags, and animations. Objaverse improves upon present day 3D repositories in terms of scale, number of categories, and in the visual diversity of instances within a category. We demonstrate the large potential of Objaverse via four diverse applications: training generative 3D models, improving tail category segmentation on the LVIS benchmark, training open-vocabulary object-navigation models for Embodied AI, and creating a new benchmark for robustness analysis of vision models. Objaverse can open new directions for research and enable new applications across the field of AI.
A General Purpose Supervisory Signal for Embodied Agents
Dec 01, 2022



Training effective embodied AI agents often involves manual reward engineering, expert imitation, specialized components such as maps, or leveraging additional sensors for depth and localization. Another approach is to use neural architectures alongside self-supervised objectives which encourage better representation learning. In practice, there are few guarantees that these self-supervised objectives encode task-relevant information. We propose the Scene Graph Contrastive (SGC) loss, which uses scene graphs as general-purpose, training-only, supervisory signals. The SGC loss does away with explicit graph decoding and instead uses contrastive learning to align an agent's representation with a rich graphical encoding of its environment. The SGC loss is generally applicable, simple to implement, and encourages representations that encode objects' semantics, relationships, and history. Using the SGC loss, we attain significant gains on three embodied tasks: Object Navigation, Multi-Object Navigation, and Arm Point Navigation. Finally, we present studies and analyses which demonstrate the ability of our trained representation to encode semantic cues about the environment.
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Jun 14, 2022

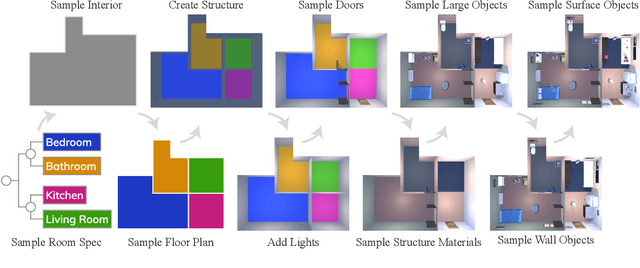
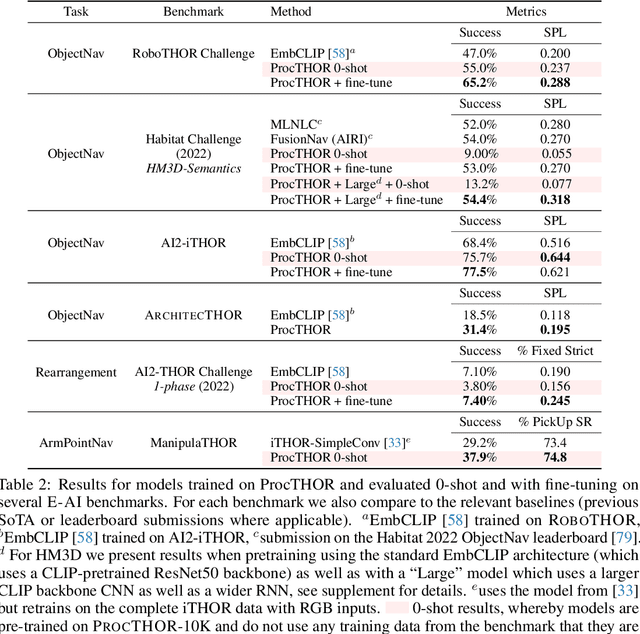
Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.
ASC me to Do Anything: Multi-task Training for Embodied AI
Feb 14, 2022



Embodied AI has seen steady progress across a diverse set of independent tasks. While these varied tasks have different end goals, the basic skills required to complete them successfully overlap significantly. In this paper, our goal is to leverage these shared skills to learn to perform multiple tasks jointly. We propose Atomic Skill Completion (ASC), an approach for multi-task training for Embodied AI, where a set of atomic skills shared across multiple tasks are composed together to perform the tasks. The key to the success of this approach is a pre-training scheme that decouples learning of the skills from the high-level tasks making joint training effective. We use ASC to train agents within the AI2-THOR environment to perform four interactive tasks jointly and find it to be remarkably effective. In a multi-task setting, ASC improves success rates by a factor of 2x on Seen scenes and 4x on Unseen scenes compared to no pre-training. Importantly, ASC enables us to train a multi-task agent that has a 52% higher Success Rate than training 4 independent single task agents. Finally, our hierarchical agents are more interpretable than traditional black-box architectures.