 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning
Dec 15, 2025As humans, we are natural any-horizon reasoners, i.e., we can decide whether to iteratively skim long videos or watch short ones in full when necessary for a given task. With this in mind, one would expect video reasoning models to reason flexibly across different durations. However, SOTA models are still trained to predict answers in a single turn while processing a large number of frames, akin to watching an entire long video, requiring significant resources. This raises the question: Is it possible to develop performant any-horizon video reasoning systems? Inspired by human behavior, we first propose SAGE, an agent system that performs multi-turn reasoning on long videos while handling simpler problems in a single turn. Secondly, we introduce an easy synthetic data generation pipeline using Gemini-2.5-Flash to train the orchestrator, SAGE-MM, which lies at the core of SAGE. We further propose an effective RL post-training recipe essential for instilling any-horizon reasoning ability in SAGE-MM. Thirdly, we curate SAGE-Bench with an average duration of greater than 700 seconds for evaluating video reasoning ability in real-world entertainment use cases. Lastly, we empirically validate the effectiveness of our system, data, and RL recipe, observing notable improvements of up to 6.1% on open-ended video reasoning tasks, as well as an impressive 8.2% improvement on videos longer than 10 minutes.
MutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
Feb 21, 2025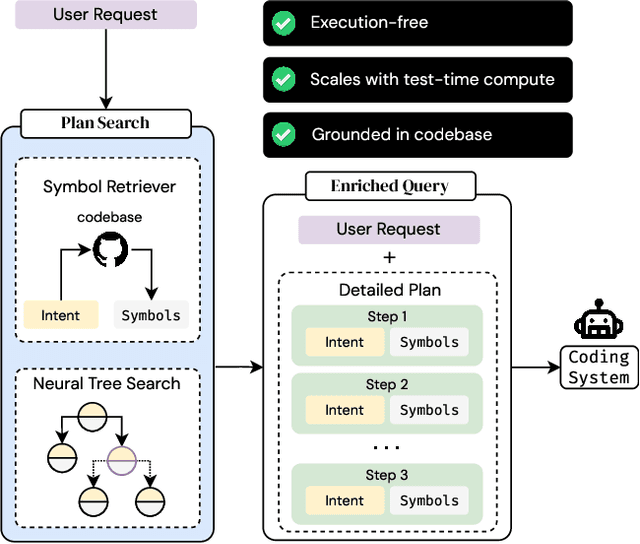



When a human requests an LLM to complete a coding task using functionality from a large code repository, how do we provide context from the repo to the LLM? One approach is to add the entire repo to the LLM's context window. However, most tasks involve only fraction of symbols from a repo, longer contexts are detrimental to the LLM's reasoning abilities, and context windows are not unlimited. Alternatively, we could emulate the human ability to navigate a large repo, pick out the right functionality, and form a plan to solve the task. We propose MutaGReP (Mutation-guided Grounded Repository Plan Search), an approach to search for plans that decompose a user request into natural language steps grounded in the codebase. MutaGReP performs neural tree search in plan space, exploring by mutating plans and using a symbol retriever for grounding. On the challenging LongCodeArena benchmark, our plans use less than 5% of the 128K context window for GPT-4o but rival the coding performance of GPT-4o with a context window filled with the repo. Plans produced by MutaGReP allow Qwen 2.5 Coder 32B and 72B to match the performance of GPT-4o with full repo context and enable progress on the hardest LongCodeArena tasks. Project page: zaidkhan.me/MutaGReP
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Feb 20, 2025Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., "nutrition fact labels"), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
CodeNav: Beyond tool-use to using real-world codebases with LLM agents
Jun 18, 2024



We present CodeNav, an LLM agent that navigates and leverages previously unseen code repositories to solve user queries. In contrast to tool-use LLM agents that require ``registration'' of all relevant tools via manual descriptions within the LLM context, CodeNav automatically indexes and searches over code blocks in the target codebase, finds relevant code snippets, imports them, and uses them to iteratively generate a solution with execution feedback. To highlight the core-capabilities of CodeNav, we first showcase three case studies where we use CodeNav for solving complex user queries using three diverse codebases. Next, on three benchmarks, we quantitatively compare the effectiveness of code-use (which only has access to the target codebase) to tool-use (which has privileged access to all tool names and descriptions). Finally, we study the effect of varying kinds of tool and library descriptions on code-use performance, as well as investigate the advantage of the agent seeing source code as opposed to natural descriptions of code. All code will be made open source under a permissive license.
Task Me Anything
Jun 17, 2024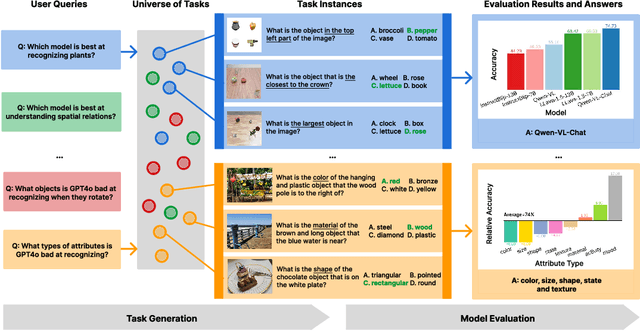

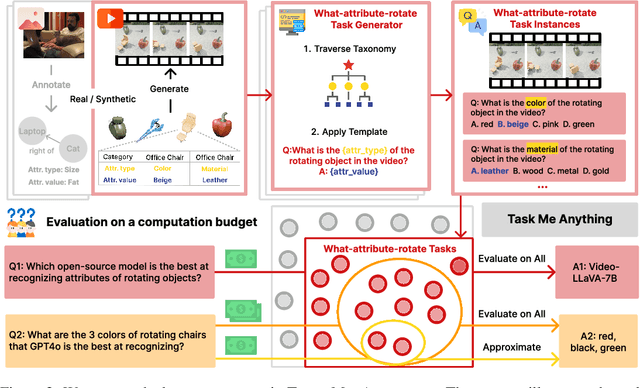

Benchmarks for large multimodal language models (MLMs) now serve to simultaneously assess the general capabilities of models instead of evaluating for a specific capability. As a result, when a developer wants to identify which models to use for their application, they are overwhelmed by the number of benchmarks and remain uncertain about which benchmark's results are most reflective of their specific use case. This paper introduces Task-Me-Anything, a benchmark generation engine which produces a benchmark tailored to a user's needs. Task-Me-Anything maintains an extendable taxonomy of visual assets and can programmatically generate a vast number of task instances. Additionally, it algorithmically addresses user queries regarding MLM performance efficiently within a computational budget. It contains 113K images, 10K videos, 2K 3D object assets, over 365 object categories, 655 attributes, and 335 relationships. It can generate 750M image/video question-answering pairs, which focus on evaluating MLM perceptual capabilities. Task-Me-Anything reveals critical insights: open-source MLMs excel in object and attribute recognition but lack spatial and temporal understanding; each model exhibits unique strengths and weaknesses; larger models generally perform better, though exceptions exist; and GPT4o demonstrates challenges in recognizing rotating/moving objects and distinguishing colors.
m&m's: A Benchmark to Evaluate Tool-Use for multi-step multi-modal Tasks
Mar 21, 2024Real-world multi-modal problems are rarely solved by a single machine learning model, and often require multi-step computational plans that involve stitching several models. Tool-augmented LLMs hold tremendous promise for automating the generation of such computational plans. However, the lack of standardized benchmarks for evaluating LLMs as planners for multi-step multi-modal tasks has prevented a systematic study of planner design decisions. Should LLMs generate a full plan in a single shot or step-by-step? Should they invoke tools directly with Python code or through structured data formats like JSON? Does feedback improve planning? To answer these questions and more, we introduce m&m's: a benchmark containing 4K+ multi-step multi-modal tasks involving 33 tools that include multi-modal models, (free) public APIs, and image processing modules. For each of these task queries, we provide automatically generated plans using this realistic toolset. We further provide a high-quality subset of 1,565 task plans that are human-verified and correctly executable. With m&m's, we evaluate 6 popular LLMs with 2 planning strategies (multi-step vs. step-by-step planning), 2 plan formats (JSON vs. code), and 3 types of feedback (parsing/verification/execution). Finally, we summarize takeaways from our extensive experiments. Our dataset and code are available on HuggingFace (https://huggingface.co/datasets/zixianma/mnms) and Github (https://github.com/RAIVNLab/mnms).
Selective "Selective Prediction": Reducing Unnecessary Abstention in Vision-Language Reasoning
Feb 23, 2024
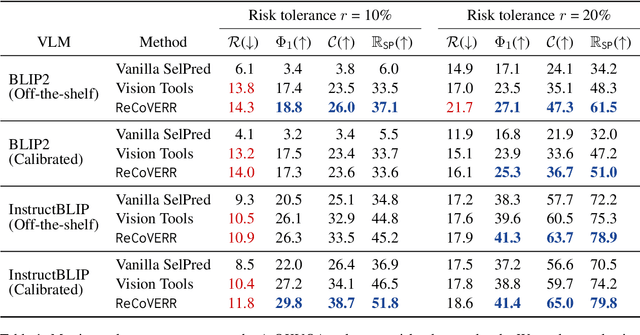

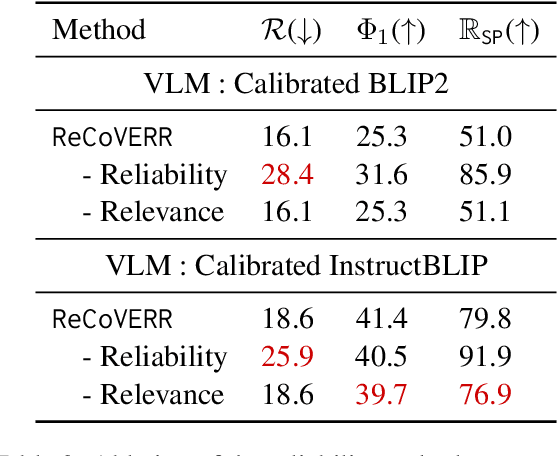
Prior work on selective prediction minimizes incorrect predictions from vision-language models (VLMs) by allowing them to abstain from answering when uncertain. However, when deploying a vision-language system with low tolerance for inaccurate predictions, selective prediction may be over-cautious and abstain too frequently, even on many correct predictions. We introduce ReCoVERR, an inference-time algorithm to reduce the over-abstention of a selective vision-language system without decreasing prediction accuracy. When the VLM makes a low-confidence prediction, instead of abstaining ReCoVERR tries to find relevant clues in the image that provide additional evidence for the prediction. ReCoVERR uses an LLM to pose related questions to the VLM, collects high-confidence evidences, and if enough evidence confirms the prediction the system makes a prediction instead of abstaining. ReCoVERR enables two VLMs, BLIP2 and InstructBLIP, to answer up to 20% more questions on the A-OKVQA task than vanilla selective prediction without decreasing system accuracy, thus improving overall system reliability.
Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Dec 05, 2023



Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extensive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES will be open-sourced.
OBJECT 3DIT: Language-guided 3D-aware Image Editing
Jul 20, 2023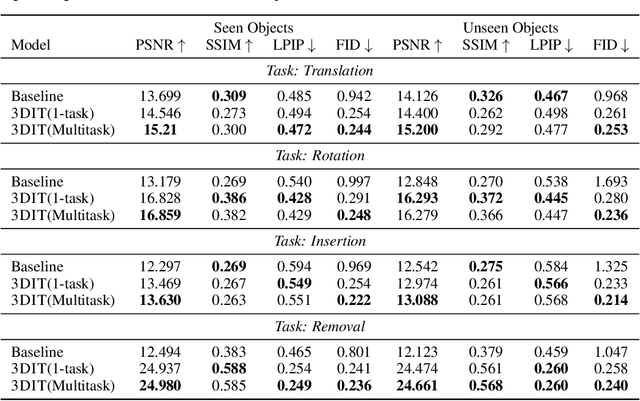


Existing image editing tools, while powerful, typically disregard the underlying 3D geometry from which the image is projected. As a result, edits made using these tools may become detached from the geometry and lighting conditions that are at the foundation of the image formation process. In this work, we formulate the newt ask of language-guided 3D-aware editing, where objects in an image should be edited according to a language instruction in context of the underlying 3D scene. To promote progress towards this goal, we release OBJECT: a dataset consisting of 400K editing examples created from procedurally generated 3D scenes. Each example consists of an input image, editing instruction in language, and the edited image. We also introduce 3DIT : single and multi-task models for four editing tasks. Our models show impressive abilities to understand the 3D composition of entire scenes, factoring in surrounding objects, surfaces, lighting conditions, shadows, and physically-plausible object configurations. Surprisingly, training on only synthetic scenes from OBJECT, editing capabilities of 3DIT generalize to real-world images.