 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitating What Works: Simulation-Filtered Modular Policy Learning from Human Videos
Feb 13, 2026The ability to learn manipulation skills by watching videos of humans has the potential to unlock a new source of highly scalable data for robot learning. Here, we tackle prehensile manipulation, in which tasks involve grasping an object before performing various post-grasp motions. Human videos offer strong signals for learning the post-grasp motions, but they are less useful for learning the prerequisite grasping behaviors, especially for robots without human-like hands. A promising way forward is to use a modular policy design, leveraging a dedicated grasp generator to produce stable grasps. However, arbitrary stable grasps are often not task-compatible, hindering the robot's ability to perform the desired downstream motion. To address this challenge, we present Perceive-Simulate-Imitate (PSI), a framework for training a modular manipulation policy using human video motion data processed by paired grasp-trajectory filtering in simulation. This simulation step extends the trajectory data with grasp suitability labels, which allows for supervised learning of task-oriented grasping capabilities. We show through real-world experiments that our framework can be used to learn precise manipulation skills efficiently without any robot data, resulting in significantly more robust performance than using a grasp generator naively.
Convergent Functions, Divergent Forms
May 27, 2025We introduce LOKI, a compute-efficient framework for co-designing morphologies and control policies that generalize across unseen tasks. Inspired by biological adaptation -- where animals quickly adjust to morphological changes -- our method overcomes the inefficiencies of traditional evolutionary and quality-diversity algorithms. We propose learning convergent functions: shared control policies trained across clusters of morphologically similar designs in a learned latent space, drastically reducing the training cost per design. Simultaneously, we promote divergent forms by replacing mutation with dynamic local search, enabling broader exploration and preventing premature convergence. The policy reuse allows us to explore 780$\times$ more designs using 78% fewer simulation steps and 40% less compute per design. Local competition paired with a broader search results in a diverse set of high-performing final morphologies. Using the UNIMAL design space and a flat-terrain locomotion task, LOKI discovers a rich variety of designs -- ranging from quadrupeds to crabs, bipedals, and spinners -- far more diverse than those produced by prior work. These morphologies also transfer better to unseen downstream tasks in agility, stability, and manipulation domains (e.g., 2$\times$ higher reward on bump and push box incline tasks). Overall, our approach produces designs that are both diverse and adaptable, with substantially greater sample efficiency than existing co-design methods. (Project website: https://loki-codesign.github.io/)
GraspMolmo: Generalizable Task-Oriented Grasping via Large-Scale Synthetic Data Generation
May 19, 2025We present GrasMolmo, a generalizable open-vocabulary task-oriented grasping (TOG) model. GraspMolmo predicts semantically appropriate, stable grasps conditioned on a natural language instruction and a single RGB-D frame. For instance, given "pour me some tea", GraspMolmo selects a grasp on a teapot handle rather than its body. Unlike prior TOG methods, which are limited by small datasets, simplistic language, and uncluttered scenes, GraspMolmo learns from PRISM, a novel large-scale synthetic dataset of 379k samples featuring cluttered environments and diverse, realistic task descriptions. We fine-tune the Molmo visual-language model on this data, enabling GraspMolmo to generalize to novel open-vocabulary instructions and objects. In challenging real-world evaluations, GraspMolmo achieves state-of-the-art results, with a 70% prediction success on complex tasks, compared to the 35% achieved by the next best alternative. GraspMolmo also successfully demonstrates the ability to predict semantically correct bimanual grasps zero-shot. We release our synthetic dataset, code, model, and benchmarks to accelerate research in task-semantic robotic manipulation, which, along with videos, are available at https://abhaybd.github.io/GraspMolmo/.
The One RING: a Robotic Indoor Navigation Generalist
Dec 18, 2024



Modern robots vary significantly in shape, size, and sensor configurations used to perceive and interact with their environments. However, most navigation policies are embodiment-specific; a policy learned using one robot's configuration does not typically gracefully generalize to another. Even small changes in the body size or camera viewpoint may cause failures. With the recent surge in custom hardware developments, it is necessary to learn a single policy that can be transferred to other embodiments, eliminating the need to (re)train for each specific robot. In this paper, we introduce RING (Robotic Indoor Navigation Generalist), an embodiment-agnostic policy, trained solely in simulation with diverse randomly initialized embodiments at scale. Specifically, we augment the AI2-THOR simulator with the ability to instantiate robot embodiments with controllable configurations, varying across body size, rotation pivot point, and camera configurations. In the visual object-goal navigation task, RING achieves robust performance on real unseen robot platforms (Stretch RE-1, LoCoBot, Unitree's Go1), achieving an average of 72.1% and 78.9% success rate across 5 embodiments in simulation and 4 robot platforms in the real world. (project website: https://one-ring-policy.allen.ai/)
SAT: Spatial Aptitude Training for Multimodal Language Models
Dec 10, 2024



Spatial perception is a fundamental component of intelligence. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only test for static spatial reasoning, such as categorizing the relative positions of objects. Meanwhile, real-world deployment requires dynamic capabilities like perspective-taking and egocentric action recognition. As a roadmap to improving spatial intelligence, we introduce SAT, Spatial Aptitude Training, which goes beyond static relative object position questions to the more dynamic tasks. SAT contains 218K question-answer pairs for 22K synthetic scenes across a training and testing set. Generated using a photo-realistic physics engine, our dataset can be arbitrarily scaled and easily extended to new actions, scenes, and 3D assets. We find that even MLMs that perform relatively well on static questions struggle to accurately answer dynamic spatial questions. Further, we show that SAT instruction-tuning data improves not only dynamic spatial reasoning on SAT, but also zero-shot performance on existing real-image spatial benchmarks: $23\%$ on CVBench, $8\%$ on the harder BLINK benchmark, and $18\%$ on VSR. When instruction-tuned on SAT, our 13B model matches larger proprietary MLMs like GPT4-V and Gemini-3-1.0 in spatial reasoning. Our data/code is available at http://arijitray1993.github.io/SAT/ .
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning
Sep 25, 2024



In recent years, the Robotics field has initiated several efforts toward building generalist robot policies through large-scale multi-task Behavior Cloning. However, direct deployments of these policies have led to unsatisfactory performance, where the policy struggles with unseen states and tasks. How can we break through the performance plateau of these models and elevate their capabilities to new heights? In this paper, we propose FLaRe, a large-scale Reinforcement Learning fine-tuning framework that integrates robust pre-trained representations, large-scale training, and gradient stabilization techniques. Our method aligns pre-trained policies towards task completion, achieving state-of-the-art (SoTA) performance both on previously demonstrated and on entirely novel tasks and embodiments. Specifically, on a set of long-horizon mobile manipulation tasks, FLaRe achieves an average success rate of 79.5% in unseen environments, with absolute improvements of +23.6% in simulation and +30.7% on real robots over prior SoTA methods. By utilizing only sparse rewards, our approach can enable generalizing to new capabilities beyond the pretraining data with minimal human effort. Moreover, we demonstrate rapid adaptation to new embodiments and behaviors with less than a day of fine-tuning. Videos can be found on the project website at https://robot-flare.github.io/
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
Jun 28, 2024



We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real-world without adaptation despite being trained purely in simulation. PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning. It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput. PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks. It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the CHORES-S benchmark, a 28.5% absolute improvement. PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.
Seeing the Unseen: Visual Common Sense for Semantic Placement
Jan 15, 2024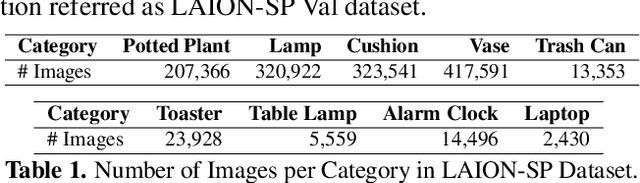
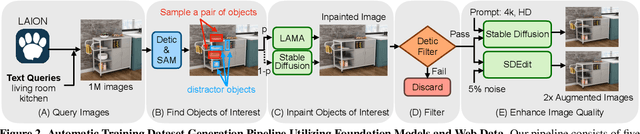
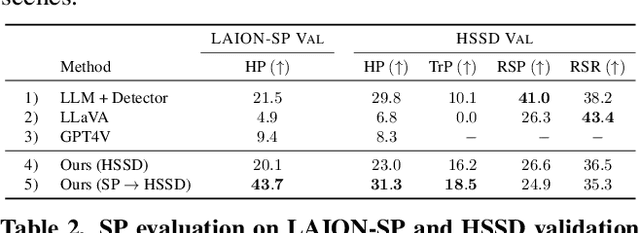

Computer vision tasks typically involve describing what is present in an image (e.g. classification, detection, segmentation, and captioning). We study a visual common sense task that requires understanding what is not present. Specifically, given an image (e.g. of a living room) and name of an object ("cushion"), a vision system is asked to predict semantically-meaningful regions (masks or bounding boxes) in the image where that object could be placed or is likely be placed by humans (e.g. on the sofa). We call this task: Semantic Placement (SP) and believe that such common-sense visual understanding is critical for assitive robots (tidying a house), and AR devices (automatically rendering an object in the user's space). Studying the invisible is hard. Datasets for image description are typically constructed by curating relevant images and asking humans to annotate the contents of the image; neither of those two steps are straightforward for objects not present in the image. We overcome this challenge by operating in the opposite direction: we start with an image of an object in context from web, and then remove that object from the image via inpainting. This automated pipeline converts unstructured web data into a dataset comprising pairs of images with/without the object. Using this, we collect a novel dataset, with ${\sim}1.3$M images across $9$ object categories, and train a SP prediction model called CLIP-UNet. CLIP-UNet outperforms existing VLMs and baselines that combine semantic priors with object detectors on real-world and simulated images. In our user studies, we find that the SP masks predicted by CLIP-UNet are favored $43.7\%$ and $31.3\%$ times when comparing against the $4$ SP baselines on real and simulated images. In addition, we demonstrate leveraging SP mask predictions from CLIP-UNet enables downstream applications like building tidying robots in indoor environments.
Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Dec 05, 2023



Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extensive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES will be open-sourced.