 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Jun 14, 2022

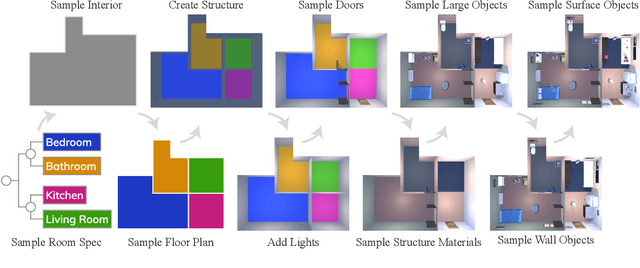
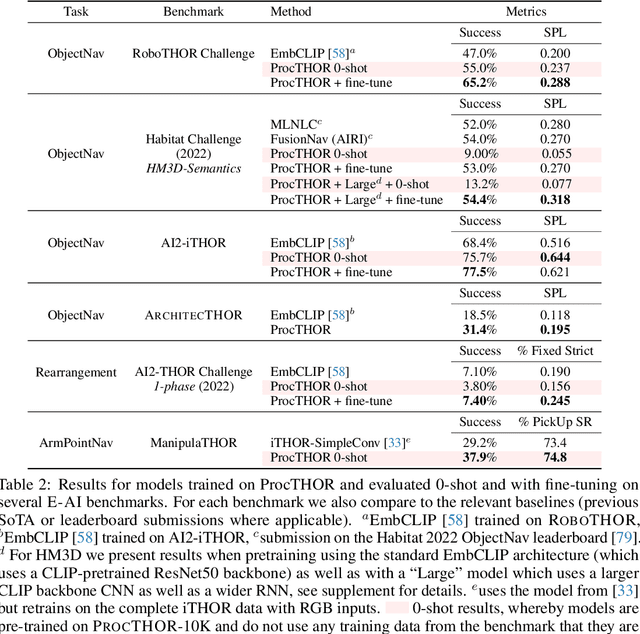
Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.
Webly Supervised Concept Expansion for General Purpose Vision Models
Feb 04, 2022


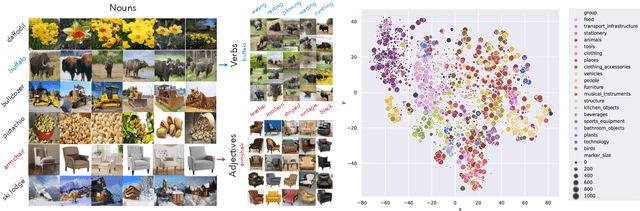
General purpose vision (GPV) systems are models that are designed to solve a wide array of visual tasks without requiring architectural changes. Today, GPVs primarily learn both skills and concepts from large fully supervised datasets. Scaling GPVs to tens of thousands of concepts by acquiring data to learn each concept for every skill quickly becomes prohibitive. This work presents an effective and inexpensive alternative: learn skills from fully supervised datasets, learn concepts from web image search results, and leverage a key characteristic of GPVs -- the ability to transfer visual knowledge across skills. We use a dataset of 1M+ images spanning 10k+ visual concepts to demonstrate webly-supervised concept expansion for two existing GPVs (GPV-1 and VL-T5) on 3 benchmarks - 5 COCO based datasets (80 primary concepts), a newly curated series of 5 datasets based on the OpenImages and VisualGenome repositories (~500 concepts) and the Web-derived dataset (10k+ concepts). We also propose a new architecture, GPV-2 that supports a variety of tasks -- from vision tasks like classification and localization to vision+language tasks like QA and captioning to more niche ones like human-object interaction recognition. GPV-2 benefits hugely from web data, outperforms GPV-1 and VL-T5 across these benchmarks, and does well in a 0-shot setting at action and attribute recognition.
Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text
Dec 01, 2021Communicating with humans is challenging for AIs because it requires a shared understanding of the world, complex semantics (e.g., metaphors or analogies), and at times multi-modal gestures (e.g., pointing with a finger, or an arrow in a diagram). We investigate these challenges in the context of Iconary, a collaborative game of drawing and guessing based on Pictionary, that poses a novel challenge for the research community. In Iconary, a Guesser tries to identify a phrase that a Drawer is drawing by composing icons, and the Drawer iteratively revises the drawing to help the Guesser in response. This back-and-forth often uses canonical scenes, visual metaphor, or icon compositions to express challenging words, making it an ideal test for mixing language and visual/symbolic communication in AI. We propose models to play Iconary and train them on over 55,000 games between human players. Our models are skillful players and are able to employ world knowledge in language models to play with words unseen during training. Elite human players outperform our models, particularly at the drawing task, leaving an important gap for future research to address. We release our dataset, code, and evaluation setup as a challenge to the community at http://www.github.com/allenai/iconary.
CORA: Benchmarks, Baselines, and Metrics as a Platform for Continual Reinforcement Learning Agents
Oct 19, 2021Progress in continual reinforcement learning has been limited due to several barriers to entry: missing code, high compute requirements, and a lack of suitable benchmarks. In this work, we present CORA, a platform for Continual Reinforcement Learning Agents that provides benchmarks, baselines, and metrics in a single code package. The benchmarks we provide are designed to evaluate different aspects of the continual RL challenge, such as catastrophic forgetting, plasticity, ability to generalize, and sample-efficient learning. Three of the benchmarks utilize video game environments (Atari, Procgen, NetHack). The fourth benchmark, CHORES, consists of four different task sequences in a visually realistic home simulator, drawn from a diverse set of task and scene parameters. To compare continual RL methods on these benchmarks, we prepare three metrics in CORA: continual evaluation, forgetting, and zero-shot forward transfer. Finally, CORA includes a set of performant, open-source baselines of existing algorithms for researchers to use and expand on. We release CORA and hope that the continual RL community can benefit from our contributions, to accelerate the development of new continual RL algorithms.
ManipulaTHOR: A Framework for Visual Object Manipulation
Apr 22, 2021
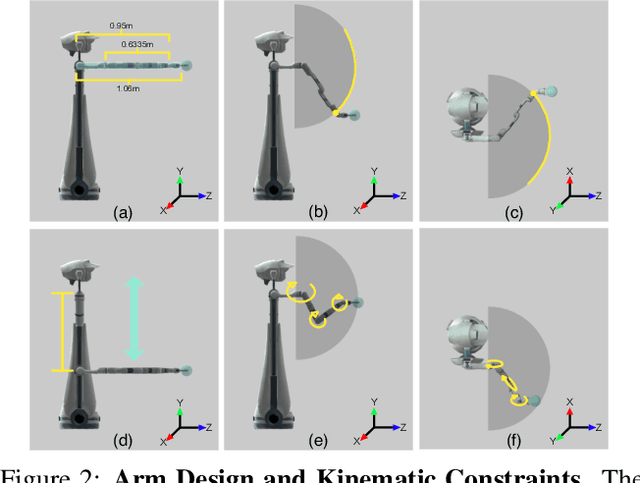
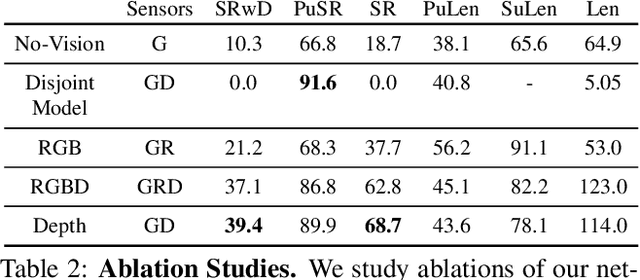

The domain of Embodied AI has recently witnessed substantial progress, particularly in navigating agents within their environments. These early successes have laid the building blocks for the community to tackle tasks that require agents to actively interact with objects in their environment. Object manipulation is an established research domain within the robotics community and poses several challenges including manipulator motion, grasping and long-horizon planning, particularly when dealing with oft-overlooked practical setups involving visually rich and complex scenes, manipulation using mobile agents (as opposed to tabletop manipulation), and generalization to unseen environments and objects. We propose a framework for object manipulation built upon the physics-enabled, visually rich AI2-THOR framework and present a new challenge to the Embodied AI community known as ArmPointNav. This task extends the popular point navigation task to object manipulation and offers new challenges including 3D obstacle avoidance, manipulating objects in the presence of occlusion, and multi-object manipulation that necessitates long term planning. Popular learning paradigms that are successful on PointNav challenges show promise, but leave a large room for improvement.
A Cordial Sync: Going Beyond Marginal Policies for Multi-Agent Embodied Tasks
Jul 09, 2020
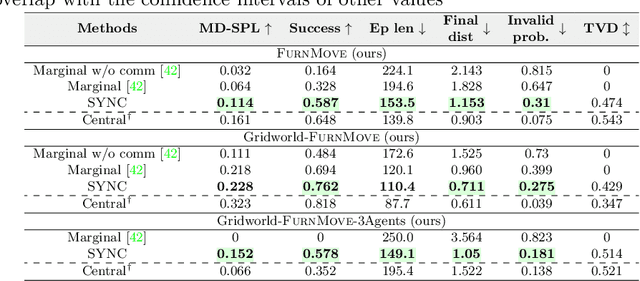
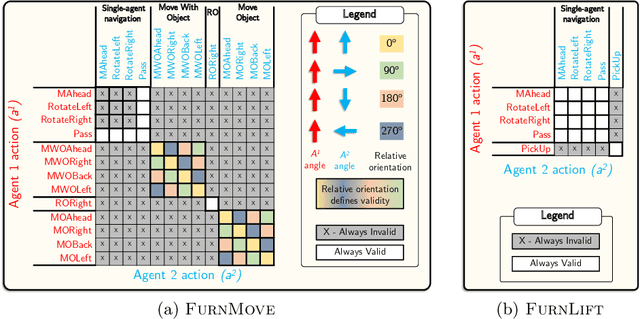

Autonomous agents must learn to collaborate. It is not scalable to develop a new centralized agent every time a task's difficulty outpaces a single agent's abilities. While multi-agent collaboration research has flourished in gridworld-like environments, relatively little work has considered visually rich domains. Addressing this, we introduce the novel task FurnMove in which agents work together to move a piece of furniture through a living room to a goal. Unlike existing tasks, FurnMove requires agents to coordinate at every timestep. We identify two challenges when training agents to complete FurnMove: existing decentralized action sampling procedures do not permit expressive joint action policies and, in tasks requiring close coordination, the number of failed actions dominates successful actions. To confront these challenges we introduce SYNC-policies (synchronize your actions coherently) and CORDIAL (coordination loss). Using SYNC-policies and CORDIAL, our agents achieve a 58% completion rate on FurnMove, an impressive absolute gain of 25 percentage points over competitive decentralized baselines. Our dataset, code, and pretrained models are available at https://unnat.github.io/cordial-sync .
RoboTHOR: An Open Simulation-to-Real Embodied AI Platform
Apr 14, 2020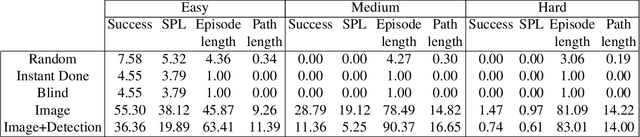

Visual recognition ecosystems (e.g. ImageNet, Pascal, COCO) have undeniably played a prevailing role in the evolution of modern computer vision. We argue that interactive and embodied visual AI has reached a stage of development similar to visual recognition prior to the advent of these ecosystems. Recently, various synthetic environments have been introduced to facilitate research in embodied AI. Notwithstanding this progress, the crucial question of how well models trained in simulation generalize to reality has remained largely unanswered. The creation of a comparable ecosystem for simulation-to-real embodied AI presents many challenges: (1) the inherently interactive nature of the problem, (2) the need for tight alignments between real and simulated worlds, (3) the difficulty of replicating physical conditions for repeatable experiments, (4) and the associated cost. In this paper, we introduce RoboTHOR to democratize research in interactive and embodied visual AI. RoboTHOR offers a framework of simulated environments paired with physical counterparts to systematically explore and overcome the challenges of simulation-to-real transfer, and a platform where researchers across the globe can remotely test their embodied models in the physical world. As a first benchmark, our experiments show there exists a significant gap between the performance of models trained in simulation when they are tested in both simulations and their carefully constructed physical analogs. We hope that RoboTHOR will spur the next stage of evolution in embodied computer vision. RoboTHOR can be accessed at the following link: https://ai2thor.allenai.org/robothor
Artificial Agents Learn Flexible Visual Representations by Playing a Hiding Game
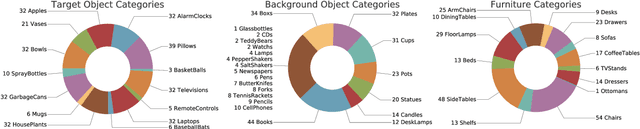
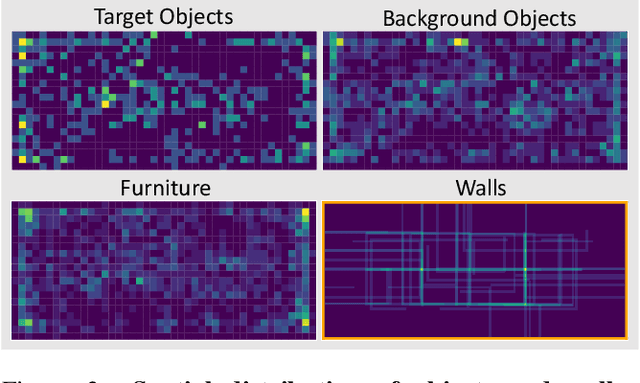
Dec 18, 2019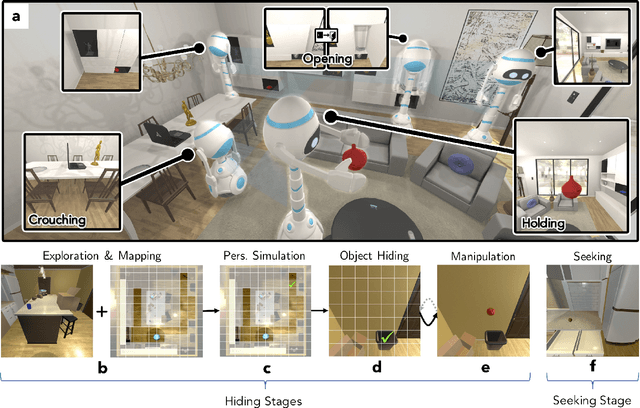
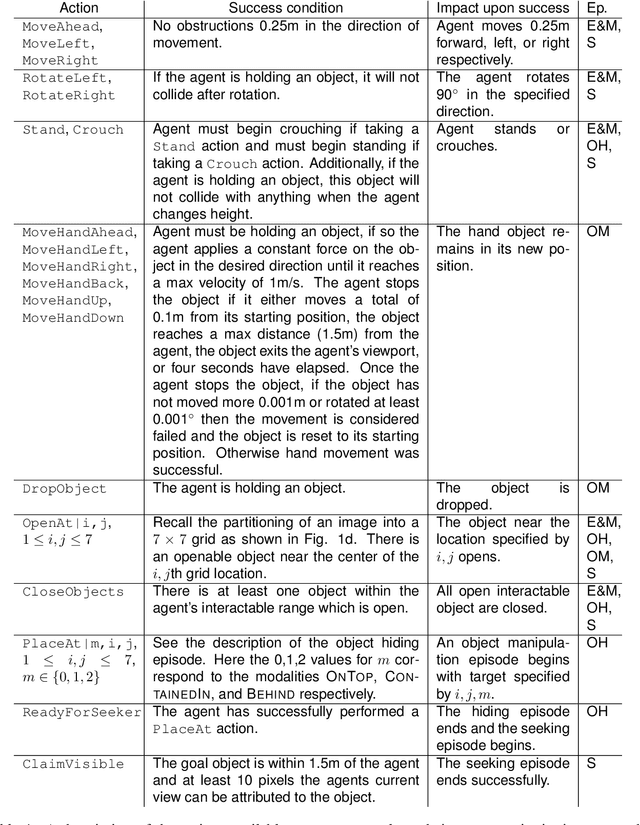

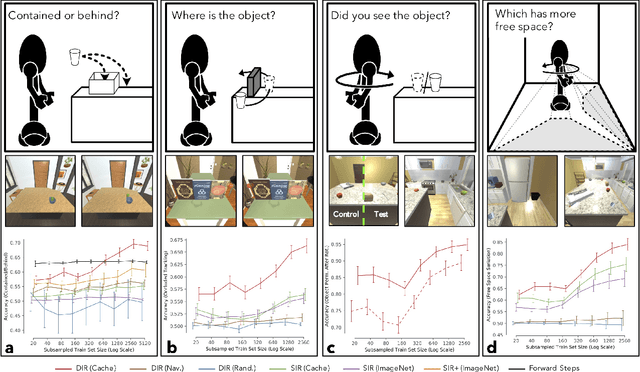
The ubiquity of embodied gameplay, observed in a wide variety of animal species including turtles and ravens, has led researchers to question what advantages play provides to the animals engaged in it. Mounting evidence suggests that play is critical in developing the neural flexibility for creative problem solving, socialization, and can improve the plasticity of the medial prefrontal cortex. Comparatively little is known regarding the impact of gameplay upon embodied artificial agents. While recent work has produced artificial agents proficient in abstract games, the environments these agents act within are far removed the real world and thus these agents provide little insight into the advantages of embodied play. Hiding games have arisen in multiple cultures and species, and provide a rich ground for studying the impact of embodied gameplay on representation learning in the context of perspective taking, secret keeping, and false belief understanding. Here we are the first to show that embodied adversarial reinforcement learning agents playing cache, a variant of hide-and-seek, in a high fidelity, interactive, environment, learn representations of their observations encoding information such as occlusion, object permanence, free space, and containment; on par with representations learnt by the most popular modern paradigm for visual representation learning which requires large datasets independently labeled for each new task. Our representations are enhanced by intent and memory, through interaction and play, moving closer to biologically motivated learning strategies. These results serve as a model for studying how facets of vision and perspective taking develop through play, provide an experimental framework for assessing what is learned by artificial agents, and suggest that representation learning should move from static datasets and towards experiential, interactive, learning.
Two Body Problem: Collaborative Visual Task Completion
Apr 11, 2019
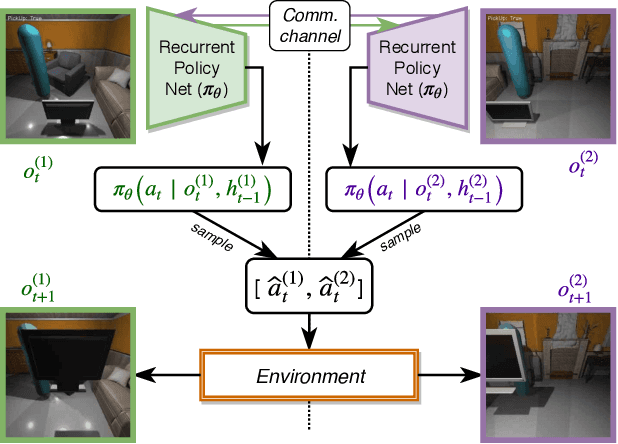
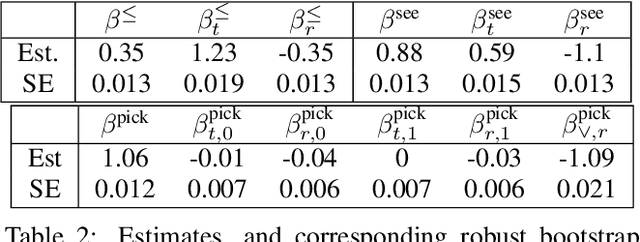
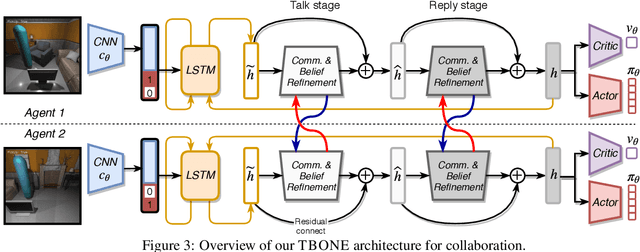
Collaboration is a necessary skill to perform tasks that are beyond one agent's capabilities. Addressed extensively in both conventional and modern AI, multi-agent collaboration has often been studied in the context of simple grid worlds. We argue that there are inherently visual aspects to collaboration which should be studied in visually rich environments. A key element in collaboration is communication that can be either explicit, through messages, or implicit, through perception of the other agents and the visual world. Learning to collaborate in a visual environment entails learning (1) to perform the task, (2) when and what to communicate, and (3) how to act based on these communications and the perception of the visual world. In this paper we study the problem of learning to collaborate directly from pixels in AI2-THOR and demonstrate the benefits of explicit and implicit modes of communication to perform visual tasks. Refer to our project page for more details: https://prior.allenai.org/projects/two-body-problem
AI2-THOR: An Interactive 3D Environment for Visual AI
Dec 14, 2017

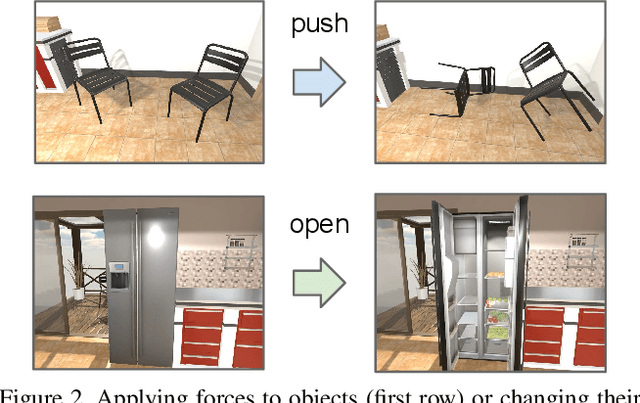
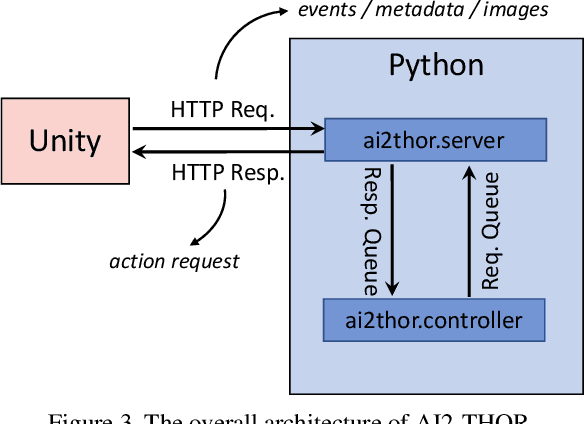
We introduce The House Of inteRactions (THOR), a framework for visual AI research, available at http://ai2thor.allenai.org. AI2-THOR consists of near photo-realistic 3D indoor scenes, where AI agents can navigate in the scenes and interact with objects to perform tasks. AI2-THOR enables research in many different domains including but not limited to deep reinforcement learning, imitation learning, learning by interaction, planning, visual question answering, unsupervised representation learning, object detection and segmentation, and learning models of cognition. The goal of AI2-THOR is to facilitate building visually intelligent models and push the research forward in this domain.