 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale Can't Overcome Pragmatics: The Impact of Reporting Bias on Vision-Language Reasoning
Feb 26, 2026The lack of reasoning capabilities in Vision-Language Models (VLMs) has remained at the forefront of research discourse. We posit that this behavior stems from a reporting bias in their training data. That is, how people communicate about visual content by default omits tacit information needed to supervise some types of reasoning; e.g., "at the game today!" is a more likely caption than "a photo of 37 people standing behind a field". We investigate the data underlying the popular VLMs OpenCLIP, LLaVA-1.5 and Molmo through the lens of theories from pragmatics, and find that reporting bias results in insufficient representation of four reasoning skills (spatial, temporal, negation, and counting), despite the corpora being of web-scale, and/or synthetically generated. With a set of curated benchmarks, we demonstrate that: (i) VLMs perform poorly on the aforementioned types of reasoning suppressed in the training data by reporting bias; (ii) contrary to popular belief, scaling data size, model size, and to multiple languages does not result in emergence of these skills by default; but, promisingly, (iii) incorporating annotations specifically collected to obtain tacit information is effective. Our findings highlight the need for more intentional training data curation methods, rather than counting on scale for emergence of reasoning capabilities.
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation
Dec 18, 2025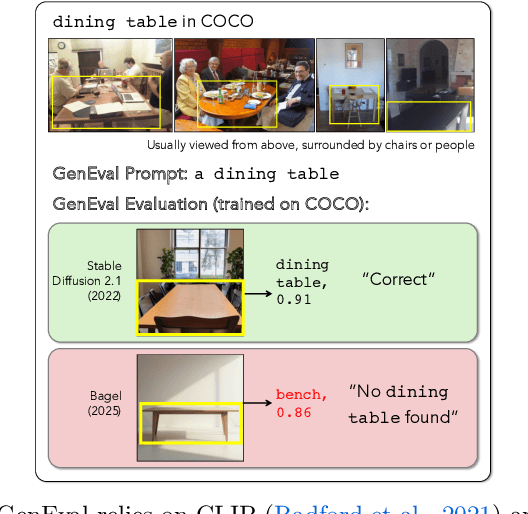
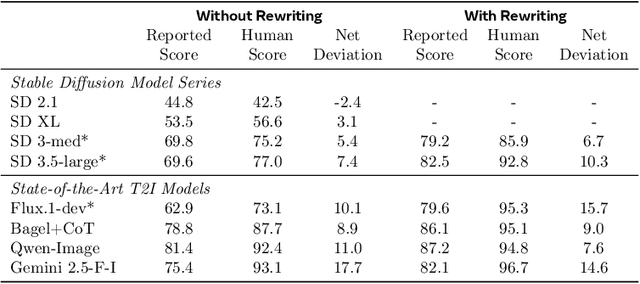
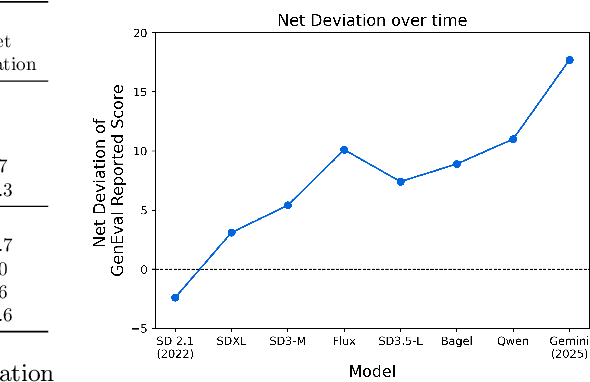
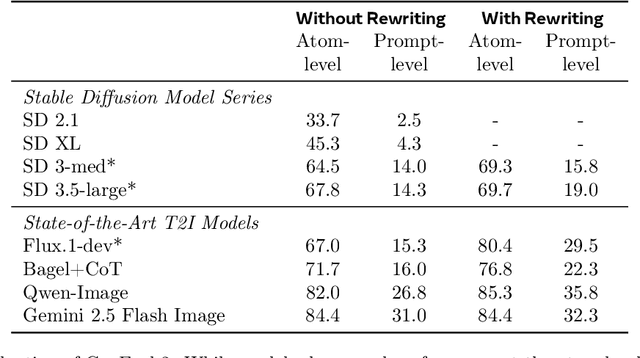
Automating Text-to-Image (T2I) model evaluation is challenging; a judge model must be used to score correctness, and test prompts must be selected to be challenging for current T2I models but not the judge. We argue that satisfying these constraints can lead to benchmark drift over time, where the static benchmark judges fail to keep up with newer model capabilities. We show that benchmark drift is a significant problem for GenEval, one of the most popular T2I benchmarks. Although GenEval was well-aligned with human judgment at the time of its release, it has drifted far from human judgment over time -- resulting in an absolute error of as much as 17.7% for current models. This level of drift strongly suggests that GenEval has been saturated for some time, as we verify via a large-scale human study. To help fill this benchmarking gap, we introduce a new benchmark, GenEval 2, with improved coverage of primitive visual concepts and higher degrees of compositionality, which we show is more challenging for current models. We also introduce Soft-TIFA, an evaluation method for GenEval 2 that combines judgments for visual primitives, which we show is more well-aligned with human judgment and argue is less likely to drift from human-alignment over time (as compared to more holistic judges such as VQAScore). Although we hope GenEval 2 will provide a strong benchmark for many years, avoiding benchmark drift is far from guaranteed and our work, more generally, highlights the importance of continual audits and improvement for T2I and related automated model evaluation benchmarks.
Visual Representations inside the Language Model
Oct 06, 2025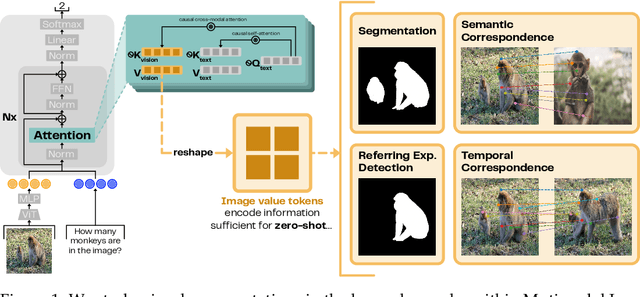

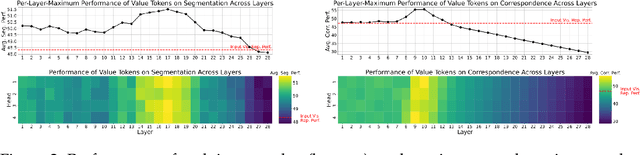
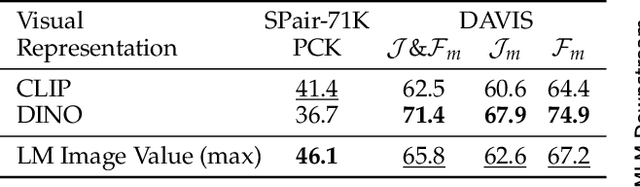
Despite interpretability work analyzing VIT encoders and transformer activations, we don't yet understand why Multimodal Language Models (MLMs) struggle on perception-heavy tasks. We offer an under-studied perspective by examining how popular MLMs (LLaVA-OneVision, Qwen2.5-VL, and Llama-3-LLaVA-NeXT) process their visual key-value tokens. We first study the flow of visual information through the language model, finding that image value tokens encode sufficient information to perform several perception-heavy tasks zero-shot: segmentation, semantic correspondence, temporal correspondence, and referring expression detection. We find that while the language model does augment the visual information received from the projection of input visual encodings-which we reveal correlates with overall MLM perception capability-it contains less visual information on several tasks than the equivalent visual encoder (SigLIP) that has not undergone MLM finetuning. Further, we find that the visual information corresponding to input-agnostic image key tokens in later layers of language models contains artifacts which reduce perception capability of the overall MLM. Next, we discuss controlling visual information in the language model, showing that adding a text prefix to the image input improves perception capabilities of visual representations. Finally, we reveal that if language models were able to better control their visual information, their perception would significantly improve; e.g., in 33.3% of Art Style questions in the BLINK benchmark, perception information present in the language model is not surfaced to the output! Our findings reveal insights into the role of key-value tokens in multimodal systems, paving the way for deeper mechanistic interpretability of MLMs and suggesting new directions for training their visual encoder and language model components.
The Hard Positive Truth about Vision-Language Compositionality
Sep 26, 2024Several benchmarks have concluded that our best vision-language models (e.g., CLIP) are lacking in compositionality. Given an image, these benchmarks probe a model's ability to identify its associated caption amongst a set of compositional distractors. In response, a surge of recent proposals show improvements by finetuning CLIP with distractors as hard negatives. Our investigations reveal that these improvements have, in fact, been significantly overstated -- because existing benchmarks do not probe whether finetuned vision-language models remain invariant to hard positives. By curating an evaluation dataset with 112,382 hard negatives and hard positives, we uncover that including hard positives decreases CLIP's performance by 12.9%, while humans perform effortlessly at 99%. CLIP finetuned with hard negatives results in an even larger decrease, up to 38.7%. With this finding, we then produce a 1,775,259 image-text training set with both hard negative and hard positive captions. By training with both, we see improvements on existing benchmarks while simultaneously improving performance on hard positives, indicating a more robust improvement in compositionality. Our work suggests the need for future research to rigorously test and improve CLIP's understanding of semantic relationships between related "positive" concepts.
Matryoshka Query Transformer for Large Vision-Language Models
May 29, 2024Large Vision-Language Models (LVLMs) typically encode an image into a fixed number of visual tokens (e.g., 576) and process these tokens with a language model. Despite their strong performance, LVLMs face challenges in adapting to varying computational constraints. This raises the question: can we achieve flexibility in the number of visual tokens to suit different tasks and computational resources? We answer this with an emphatic yes. Inspired by Matryoshka Representation Learning, we introduce the Matryoshka Query Transformer (MQT), capable of encoding an image into m visual tokens during inference, where m can be any number up to a predefined maximum. This is achieved by employing a query transformer with M latent query tokens to compress the visual embeddings. During each training step, we randomly select m <= M latent query tokens and train the model using only these first m tokens, discarding the rest. Combining MQT with LLaVA, we train a single model once, and flexibly and drastically reduce the number of inference-time visual tokens while maintaining similar or better performance compared to training independent models for each number of tokens. Our model, MQT-LLAVA, matches LLaVA-1.5 performance across 11 benchmarks using a maximum of 256 tokens instead of LLaVA's fixed 576. Reducing to 16 tokens (8x less TFLOPs) only sacrifices the performance by 2.4 points on MMBench. On certain tasks such as ScienceQA and MMMU, we can even go down to only 2 visual tokens with performance drops of just 3% and 6% each. Our exploration of the trade-off between the accuracy and computational cost brought about by the number of visual tokens facilitates future research to achieve the best of both worlds.
What's "up" with vision-language models? Investigating their struggle with spatial reasoning
Oct 30, 2023Recent vision-language (VL) models are powerful, but can they reliably distinguish "right" from "left"? We curate three new corpora to quantify model comprehension of such basic spatial relations. These tests isolate spatial reasoning more precisely than existing datasets like VQAv2, e.g., our What'sUp benchmark contains sets of photographs varying only the spatial relations of objects, keeping their identity fixed (see Figure 1: models must comprehend not only the usual case of a dog under a table, but also, the same dog on top of the same table). We evaluate 18 VL models, finding that all perform poorly, e.g., BLIP finetuned on VQAv2, which nears human parity on VQAv2, achieves 56% accuracy on our benchmarks vs. humans at 99%. We conclude by studying causes of this surprising behavior, finding: 1) that popular vision-language pretraining corpora like LAION-2B contain little reliable data for learning spatial relationships; and 2) that basic modeling interventions like up-weighting preposition-containing instances or fine-tuning on our corpora are not sufficient to address the challenges our benchmarks pose. We are hopeful that these corpora will facilitate further research, and we release our data and code at https://github.com/amitakamath/whatsup_vlms.
Text encoders are performance bottlenecks in contrastive vision-language models
May 24, 2023



Performant vision-language (VL) models like CLIP represent captions using a single vector. How much information about language is lost in this bottleneck? We first curate CompPrompts, a set of increasingly compositional image captions that VL models should be able to capture (e.g., single object, to object+property, to multiple interacting objects). Then, we train text-only recovery probes that aim to reconstruct captions from single-vector text representations produced by several VL models. This approach doesn't require images, allowing us to test on a broader range of scenes compared to prior work. We find that: 1) CLIP's text encoder falls short on object relationships, attribute-object association, counting, and negations; 2) some text encoders work significantly better than others; and 3) text-only recovery performance predicts multi-modal matching performance on ControlledImCaps: a new evaluation benchmark we collect+release consisting of fine-grained compositional images+captions. Specifically -- our results suggest text-only recoverability is a necessary (but not sufficient) condition for modeling compositional factors in contrastive vision+language models. We release data+code.
Exposing and Addressing Cross-Task Inconsistency in Unified Vision-Language Models
Mar 28, 2023As general purpose vision models get increasingly effective at a wide set of tasks, it is imperative that they be consistent across the tasks they support. Inconsistent AI models are considered brittle and untrustworthy by human users and are more challenging to incorporate into larger systems that take dependencies on their outputs. Measuring consistency between very heterogeneous tasks that might include outputs in different modalities is challenging since it is difficult to determine if the predictions are consistent with one another. As a solution, we introduce a benchmark dataset, COCOCON, where we use contrast sets created by modifying test instances for multiple tasks in small but semantically meaningful ways to change the gold label, and outline metrics for measuring if a model is consistent by ranking the original and perturbed instances across tasks. We find that state-of-the-art systems suffer from a surprisingly high degree of inconsistent behavior across tasks, especially for more heterogeneous tasks. Finally, we propose using a rank correlation-based auxiliary objective computed over large automatically created cross-task contrast sets to improve the multi-task consistency of large unified models, while retaining their original accuracy on downstream tasks. Project website available at https://adymaharana.github.io/cococon/
Webly Supervised Concept Expansion for General Purpose Vision Models
Feb 04, 2022


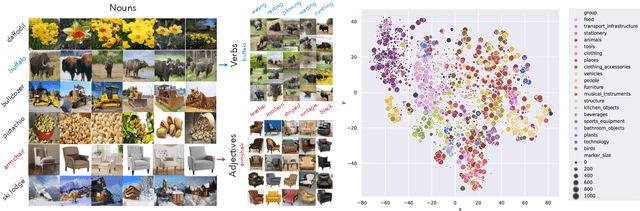
General purpose vision (GPV) systems are models that are designed to solve a wide array of visual tasks without requiring architectural changes. Today, GPVs primarily learn both skills and concepts from large fully supervised datasets. Scaling GPVs to tens of thousands of concepts by acquiring data to learn each concept for every skill quickly becomes prohibitive. This work presents an effective and inexpensive alternative: learn skills from fully supervised datasets, learn concepts from web image search results, and leverage a key characteristic of GPVs -- the ability to transfer visual knowledge across skills. We use a dataset of 1M+ images spanning 10k+ visual concepts to demonstrate webly-supervised concept expansion for two existing GPVs (GPV-1 and VL-T5) on 3 benchmarks - 5 COCO based datasets (80 primary concepts), a newly curated series of 5 datasets based on the OpenImages and VisualGenome repositories (~500 concepts) and the Web-derived dataset (10k+ concepts). We also propose a new architecture, GPV-2 that supports a variety of tasks -- from vision tasks like classification and localization to vision+language tasks like QA and captioning to more niche ones like human-object interaction recognition. GPV-2 benefits hugely from web data, outperforms GPV-1 and VL-T5 across these benchmarks, and does well in a 0-shot setting at action and attribute recognition.