 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREALTALK: A 21-Day Real-World Dataset for Long-Term Conversation
Feb 18, 2025Long-term, open-domain dialogue capabilities are essential for chatbots aiming to recall past interactions and demonstrate emotional intelligence (EI). Yet, most existing research relies on synthetic, LLM-generated data, leaving open questions about real-world conversational patterns. To address this gap, we introduce REALTALK, a 21-day corpus of authentic messaging app dialogues, providing a direct benchmark against genuine human interactions. We first conduct a dataset analysis, focusing on EI attributes and persona consistency to understand the unique challenges posed by real-world dialogues. By comparing with LLM-generated conversations, we highlight key differences, including diverse emotional expressions and variations in persona stability that synthetic dialogues often fail to capture. Building on these insights, we introduce two benchmark tasks: (1) persona simulation where a model continues a conversation on behalf of a specific user given prior dialogue context; and (2) memory probing where a model answers targeted questions requiring long-term memory of past interactions. Our findings reveal that models struggle to simulate a user solely from dialogue history, while fine-tuning on specific user chats improves persona emulation. Additionally, existing models face significant challenges in recalling and leveraging long-term context within real-world conversations.
Adapt-$\infty$: Scalable Lifelong Multimodal Instruction Tuning via Dynamic Data Selection
Oct 14, 2024



Visual instruction datasets from various distributors are released at different times and often contain a significant number of semantically redundant text-image pairs, depending on their task compositions (i.e., skills) or reference sources. This redundancy greatly limits the efficient deployment of lifelong adaptable multimodal large language models, hindering their ability to refine existing skills and acquire new competencies over time. To address this, we reframe the problem of Lifelong Instruction Tuning (LiIT) via data selection, where the model automatically selects beneficial samples to learn from earlier and new datasets based on the current state of acquired knowledge in the model. Based on empirical analyses that show that selecting the best data subset using a static importance measure is often ineffective for multi-task datasets with evolving distributions, we propose Adapt-$\infty$, a new multi-way and adaptive data selection approach that dynamically balances sample efficiency and effectiveness during LiIT. We construct pseudo-skill clusters by grouping gradient-based sample vectors. Next, we select the best-performing data selector for each skill cluster from a pool of selector experts, including our newly proposed scoring function, Image Grounding score. This data selector samples a subset of the most important samples from each skill cluster for training. To prevent the continuous increase in the size of the dataset pool during LiIT, which would result in excessive computation, we further introduce a cluster-wise permanent data pruning strategy to remove the most semantically redundant samples from each cluster, keeping computational requirements manageable. Training with samples selected by Adapt-$\infty$ alleviates catastrophic forgetting, especially for rare tasks, and promotes forward transfer across the continuum using only a fraction of the original datasets.
Evaluating Very Long-Term Conversational Memory of LLM Agents
Feb 27, 2024Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in long-context large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very long-term dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LoCoMo, a dataset of very long-term conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LoCoMo, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks. Our experimental results indicate that LLMs exhibit challenges in understanding lengthy conversations and comprehending long-range temporal and causal dynamics within dialogues. Employing strategies like long-context LLMs or RAG can offer improvements but these models still substantially lag behind human performance.
Debiasing Multimodal Models via Causal Information Minimization
Nov 28, 2023Most existing debiasing methods for multimodal models, including causal intervention and inference methods, utilize approximate heuristics to represent the biases, such as shallow features from early stages of training or unimodal features for multimodal tasks like VQA, etc., which may not be accurate. In this paper, we study bias arising from confounders in a causal graph for multimodal data and examine a novel approach that leverages causally-motivated information minimization to learn the confounder representations. Robust predictive features contain diverse information that helps a model generalize to out-of-distribution data. Hence, minimizing the information content of features obtained from a pretrained biased model helps learn the simplest predictive features that capture the underlying data distribution. We treat these features as confounder representations and use them via methods motivated by causal theory to remove bias from models. We find that the learned confounder representations indeed capture dataset biases, and the proposed debiasing methods improve out-of-distribution (OOD) performance on multiple multimodal datasets without sacrificing in-distribution performance. Additionally, we introduce a novel metric to quantify the sufficiency of spurious features in models' predictions that further demonstrates the effectiveness of our proposed methods. Our code is available at: https://github.com/Vaidehi99/CausalInfoMin
D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning
Oct 11, 2023Analytical theories suggest that higher-quality data can lead to lower test errors in models trained on a fixed data budget. Moreover, a model can be trained on a lower compute budget without compromising performance if a dataset can be stripped of its redundancies. Coreset selection (or data pruning) seeks to select a subset of the training data so as to maximize the performance of models trained on this subset, also referred to as coreset. There are two dominant approaches: (1) geometry-based data selection for maximizing data diversity in the coreset, and (2) functions that assign difficulty scores to samples based on training dynamics. Optimizing for data diversity leads to a coreset that is biased towards easier samples, whereas, selection by difficulty ranking omits easy samples that are necessary for the training of deep learning models. This demonstrates that data diversity and importance scores are two complementary factors that need to be jointly considered during coreset selection. We represent a dataset as an undirected graph and propose a novel pruning algorithm, D2 Pruning, that uses forward and reverse message passing over this dataset graph for coreset selection. D2 Pruning updates the difficulty scores of each example by incorporating the difficulty of its neighboring examples in the dataset graph. Then, these updated difficulty scores direct a graph-based sampling method to select a coreset that encapsulates both diverse and difficult regions of the dataset space. We evaluate supervised and self-supervised versions of our method on various vision and language datasets. Results show that D2 Pruning improves coreset selection over previous state-of-the-art methods for up to 70% pruning rates. Additionally, we find that using D2 Pruning for filtering large multimodal datasets leads to increased diversity in the dataset and improved generalization of pretrained models.
Exposing and Addressing Cross-Task Inconsistency in Unified Vision-Language Models
Mar 28, 2023As general purpose vision models get increasingly effective at a wide set of tasks, it is imperative that they be consistent across the tasks they support. Inconsistent AI models are considered brittle and untrustworthy by human users and are more challenging to incorporate into larger systems that take dependencies on their outputs. Measuring consistency between very heterogeneous tasks that might include outputs in different modalities is challenging since it is difficult to determine if the predictions are consistent with one another. As a solution, we introduce a benchmark dataset, COCOCON, where we use contrast sets created by modifying test instances for multiple tasks in small but semantically meaningful ways to change the gold label, and outline metrics for measuring if a model is consistent by ranking the original and perturbed instances across tasks. We find that state-of-the-art systems suffer from a surprisingly high degree of inconsistent behavior across tasks, especially for more heterogeneous tasks. Finally, we propose using a rank correlation-based auxiliary objective computed over large automatically created cross-task contrast sets to improve the multi-task consistency of large unified models, while retaining their original accuracy on downstream tasks. Project website available at https://adymaharana.github.io/cococon/
StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation
Sep 13, 2022

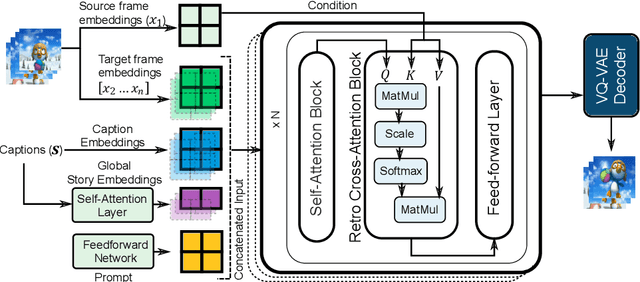
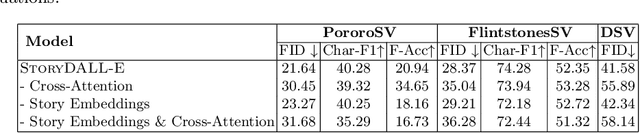
Recent advances in text-to-image synthesis have led to large pretrained transformers with excellent capabilities to generate visualizations from a given text. However, these models are ill-suited for specialized tasks like story visualization, which requires an agent to produce a sequence of images given a corresponding sequence of captions, forming a narrative. Moreover, we find that the story visualization task fails to accommodate generalization to unseen plots and characters in new narratives. Hence, we first propose the task of story continuation, where the generated visual story is conditioned on a source image, allowing for better generalization to narratives with new characters. Then, we enhance or 'retro-fit' the pretrained text-to-image synthesis models with task-specific modules for (a) sequential image generation and (b) copying relevant elements from an initial frame. Then, we explore full-model finetuning, as well as prompt-based tuning for parameter-efficient adaptation, of the pre-trained model. We evaluate our approach StoryDALL-E on two existing datasets, PororoSV and FlintstonesSV, and introduce a new dataset DiDeMoSV collected from a video-captioning dataset. We also develop a model StoryGANc based on Generative Adversarial Networks (GAN) for story continuation, and compare it with the StoryDALL-E model to demonstrate the advantages of our approach. We show that our retro-fitting approach outperforms GAN-based models for story continuation and facilitates copying of visual elements from the source image, thereby improving continuity in the generated visual story. Finally, our analysis suggests that pretrained transformers struggle to comprehend narratives containing several characters. Overall, our work demonstrates that pretrained text-to-image synthesis models can be adapted for complex and low-resource tasks like story continuation.
Integrating Visuospatial, Linguistic and Commonsense Structure into Story Visualization
Oct 21, 2021

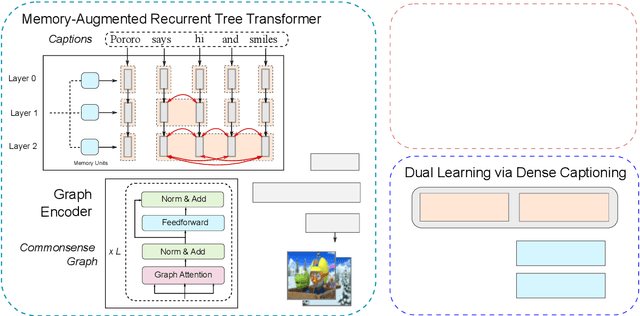
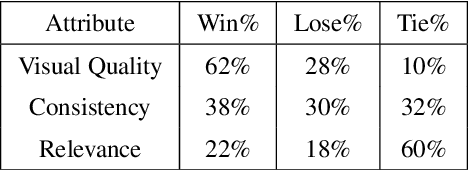
While much research has been done in text-to-image synthesis, little work has been done to explore the usage of linguistic structure of the input text. Such information is even more important for story visualization since its inputs have an explicit narrative structure that needs to be translated into an image sequence (or visual story). Prior work in this domain has shown that there is ample room for improvement in the generated image sequence in terms of visual quality, consistency and relevance. In this paper, we first explore the use of constituency parse trees using a Transformer-based recurrent architecture for encoding structured input. Second, we augment the structured input with commonsense information and study the impact of this external knowledge on the generation of visual story. Third, we also incorporate visual structure via bounding boxes and dense captioning to provide feedback about the characters/objects in generated images within a dual learning setup. We show that off-the-shelf dense-captioning models trained on Visual Genome can improve the spatial structure of images from a different target domain without needing fine-tuning. We train the model end-to-end using intra-story contrastive loss (between words and image sub-regions) and show significant improvements in several metrics (and human evaluation) for multiple datasets. Finally, we provide an analysis of the linguistic and visuo-spatial information. Code and data: https://github.com/adymaharana/VLCStoryGan.
Improving Generation and Evaluation of Visual Stories via Semantic Consistency
May 20, 2021
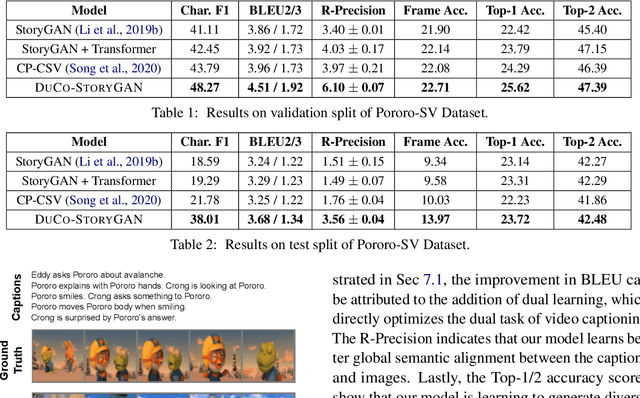
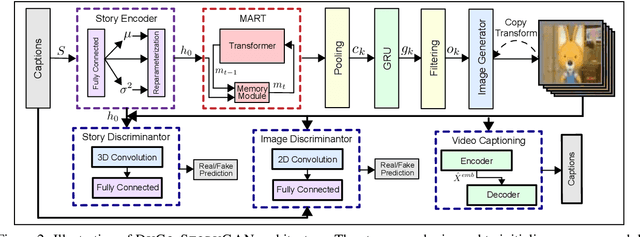
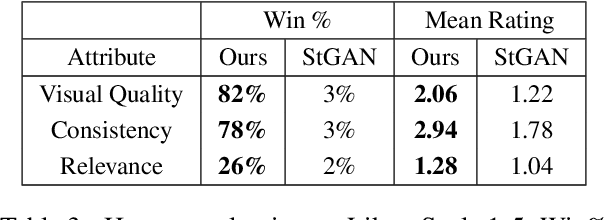
Story visualization is an under-explored task that falls at the intersection of many important research directions in both computer vision and natural language processing. In this task, given a series of natural language captions which compose a story, an agent must generate a sequence of images that correspond to the captions. Prior work has introduced recurrent generative models which outperform text-to-image synthesis models on this task. However, there is room for improvement of generated images in terms of visual quality, coherence and relevance. We present a number of improvements to prior modeling approaches, including (1) the addition of a dual learning framework that utilizes video captioning to reinforce the semantic alignment between the story and generated images, (2) a copy-transform mechanism for sequentially-consistent story visualization, and (3) MART-based transformers to model complex interactions between frames. We present ablation studies to demonstrate the effect of each of these techniques on the generative power of the model for both individual images as well as the entire narrative. Furthermore, due to the complexity and generative nature of the task, standard evaluation metrics do not accurately reflect performance. Therefore, we also provide an exploration of evaluation metrics for the model, focused on aspects of the generated frames such as the presence/quality of generated characters, the relevance to captions, and the diversity of the generated images. We also present correlation experiments of our proposed automated metrics with human evaluations. Code and data available at: https://github.com/adymaharana/StoryViz
Adversarial Augmentation Policy Search for Domain and Cross-Lingual Generalization in Reading Comprehension
May 01, 2020
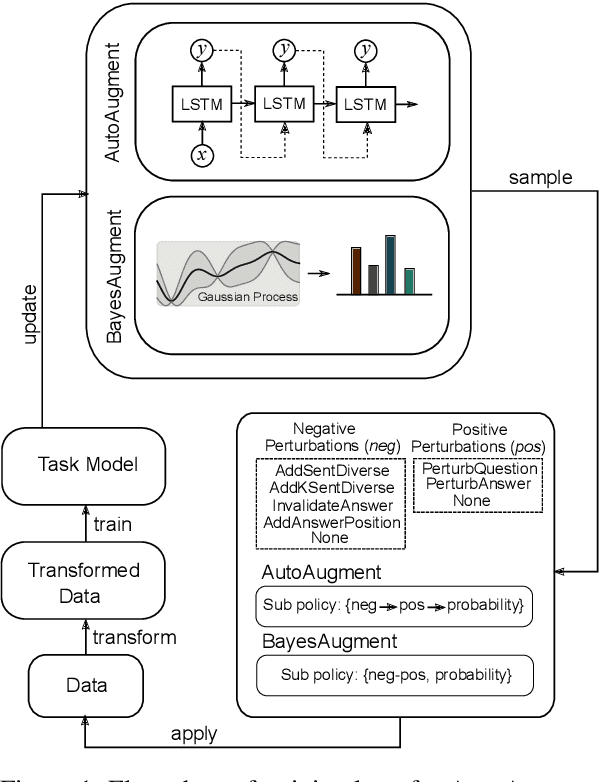
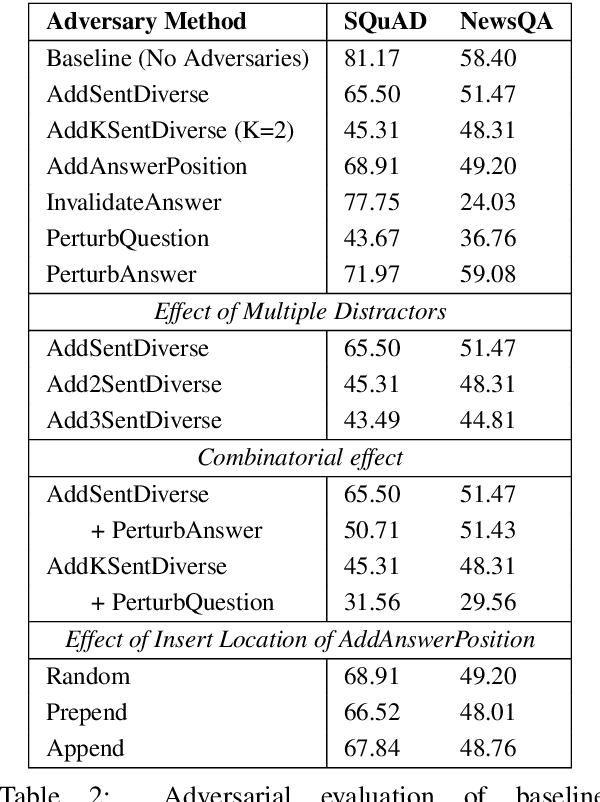
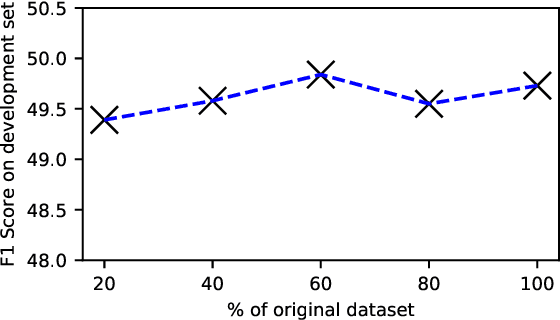
Reading comprehension models often overfit to nuances of training datasets and fail at adversarial evaluation. Training with adversarially augmented dataset improves robustness against those adversarial attacks but hurts generalization of the models. In this work, we present several effective adversaries and automated data augmentation policy search methods with the goal of making reading comprehension models more robust to adversarial evaluation, but also improving generalization to the source domain as well as new domains and languages. We first propose three new methods for generating QA adversaries, that introduce multiple points of confusion within the context, show dependence on insertion location of the distractor, and reveal the compounding effect of mixing adversarial strategies with syntactic and semantic paraphrasing methods. Next, we find that augmenting the training datasets with uniformly sampled adversaries improves robustness to the adversarial attacks but leads to decline in performance on the original unaugmented dataset. We address this issue via RL and more efficient Bayesian policy search methods for automatically learning the best augmentation policy combinations of the transformation probability for each adversary in a large search space. Using these learned policies, we show that adversarial training can lead to significant improvements in in-domain, out-of-domain, and cross-lingual (German, Russian, Turkish) generalization without any use of training data from the target domain or language.