Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Purpose Vision Systems
Paper and Code
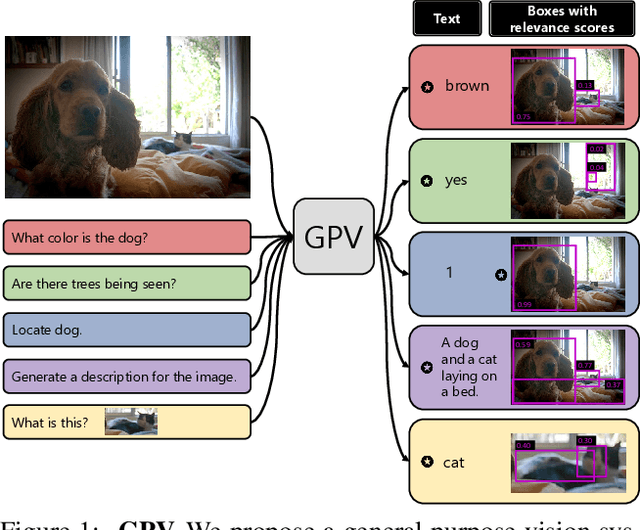
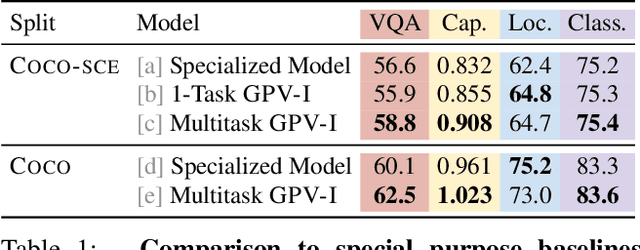


A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system's ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
* Project page: https://prior.allenai.org/projects/gpv
View paper on