 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasis Vector Metric: A Method for Robust Open-Ended State Change Detection
Sep 09, 2025



We test a new method, which we will abbreviate using the acronym BVM (Basis Vectors Method), in its ability to judge the state changes in images through using language embeddings. We used the MIT-States dataset, containing about 53,000 images, to gather all of our data, which has 225 nouns and 115 adjectives, with each noun having about 9 different adjectives, forming approximately 1000 noun-adjective pairs. For our first experiment, we test our method's ability to determine the state of each noun class separately against other metrics for comparison. These metrics are cosine similarity, dot product, product quantization, binary index, Naive Bayes, and a custom neural network. Among these metrics, we found that our proposed BVM performs the best in classifying the states for each noun. We then perform a second experiment where we try using BVM to determine if it can differentiate adjectives from one another for each adjective separately. We compared the abilities of BVM to differentiate adjectives against the proposed method the MIT-States paper suggests: using a logistic regression model. In the end, we did not find conclusive evidence that our BVM metric could perform better than the logistic regression model at discerning adjectives. Yet, we were able to find evidence for possible improvements to our method; this leads to the chance of increasing our method's accuracy through certain changes in our methodologies.
Evaluating Continual Learning on a Home Robot
Jun 04, 2023
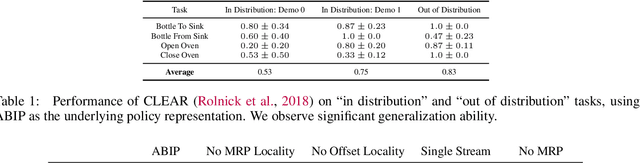
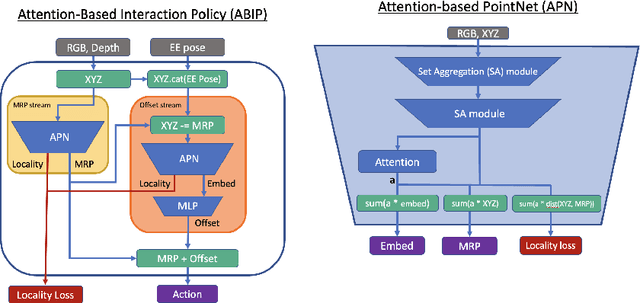

Robots in home environments need to be able to learn new skills continuously as data becomes available, becoming ever more capable over time while using as little real-world data as possible. However, traditional robot learning approaches typically assume large amounts of iid data, which is inconsistent with this goal. In contrast, continual learning methods like CLEAR and SANE allow autonomous agents to learn off of a stream of non-iid samples; they, however, have not previously been demonstrated on real robotics platforms. In this work, we show how continual learning methods can be adapted for use on a real, low-cost home robot, and in particular look at the case where we have extremely small numbers of examples, in a task-id-free setting. Specifically, we propose SANER, a method for continuously learning a library of skills, and ABIP (Attention-Based Interaction Policies) as the backbone to support it. We learn four sequential kitchen tasks on a low-cost home robot, using only a handful of demonstrations per task.
Spatial-Language Attention Policies for Efficient Robot Learning
Apr 21, 2023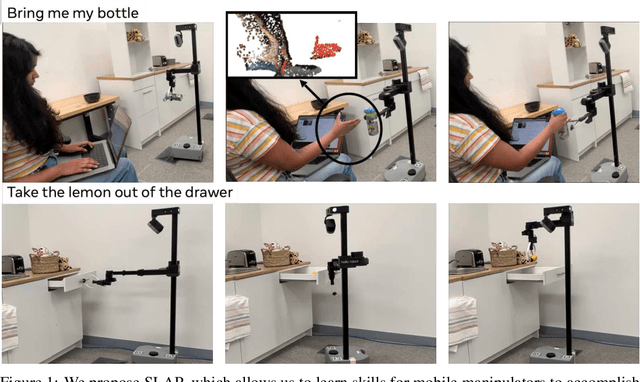
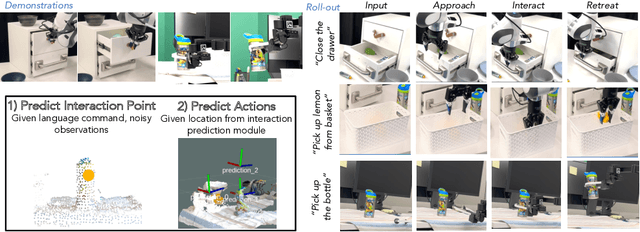
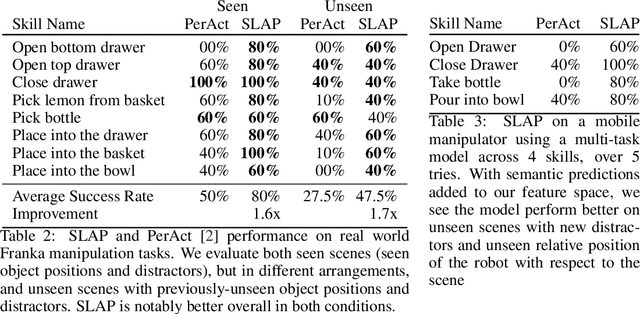
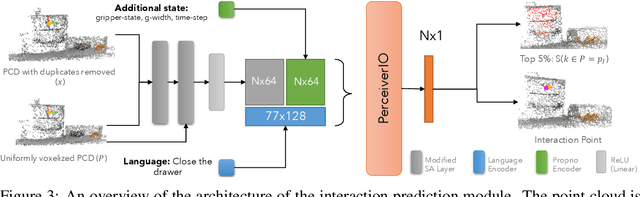
We investigate how to build and train spatial representations for robot decision making with Transformers. In particular, for robots to operate in a range of environments, we must be able to quickly train or fine-tune robot sensorimotor policies that are robust to clutter, data efficient, and generalize well to different circumstances. As a solution, we propose Spatial Language Attention Policies (SLAP). SLAP uses three-dimensional tokens as the input representation to train a single multi-task, language-conditioned action prediction policy. Our method shows 80% success rate in the real world across eight tasks with a single model, and a 47.5% success rate when unseen clutter and unseen object configurations are introduced, even with only a handful of examples per task. This represents an improvement of 30% over prior work (20% given unseen distractors and configurations).
Self-Activating Neural Ensembles for Continual Reinforcement Learning
Dec 31, 2022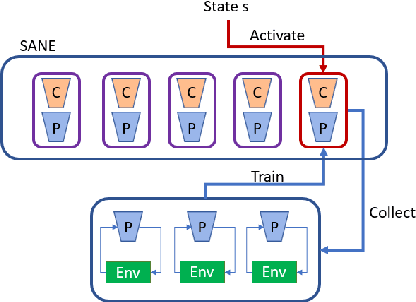


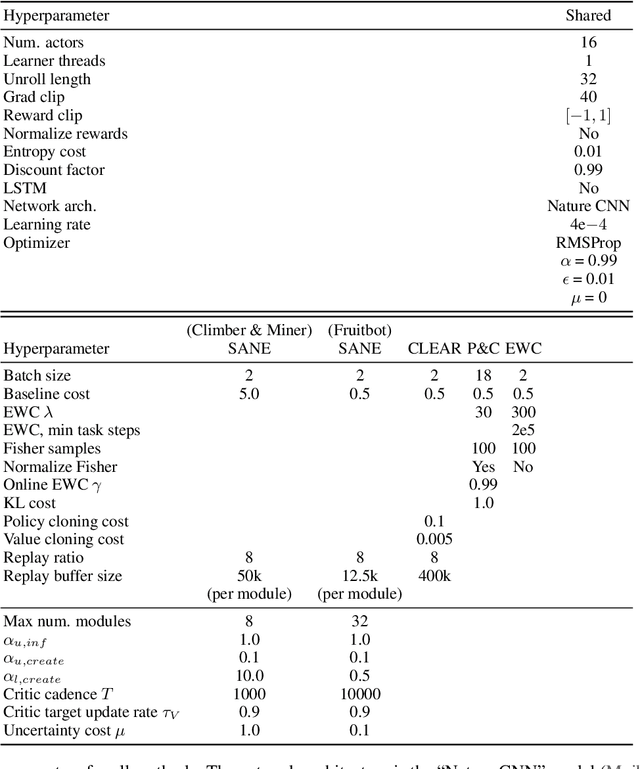
The ability for an agent to continuously learn new skills without catastrophically forgetting existing knowledge is of critical importance for the development of generally intelligent agents. Most methods devised to address this problem depend heavily on well-defined task boundaries, and thus depend on human supervision. Our task-agnostic method, Self-Activating Neural Ensembles (SANE), uses a modular architecture designed to avoid catastrophic forgetting without making any such assumptions. At the beginning of each trajectory, a module in the SANE ensemble is activated to determine the agent's next policy. During training, new modules are created as needed and only activated modules are updated to ensure that unused modules remain unchanged. This system enables our method to retain and leverage old skills, while growing and learning new ones. We demonstrate our approach on visually rich procedurally generated environments.
* Code available here: https://github.com/AGI-Labs/continual_rl
CORA: Benchmarks, Baselines, and Metrics as a Platform for Continual Reinforcement Learning Agents
Oct 19, 2021Progress in continual reinforcement learning has been limited due to several barriers to entry: missing code, high compute requirements, and a lack of suitable benchmarks. In this work, we present CORA, a platform for Continual Reinforcement Learning Agents that provides benchmarks, baselines, and metrics in a single code package. The benchmarks we provide are designed to evaluate different aspects of the continual RL challenge, such as catastrophic forgetting, plasticity, ability to generalize, and sample-efficient learning. Three of the benchmarks utilize video game environments (Atari, Procgen, NetHack). The fourth benchmark, CHORES, consists of four different task sequences in a visually realistic home simulator, drawn from a diverse set of task and scene parameters. To compare continual RL methods on these benchmarks, we prepare three metrics in CORA: continual evaluation, forgetting, and zero-shot forward transfer. Finally, CORA includes a set of performant, open-source baselines of existing algorithms for researchers to use and expand on. We release CORA and hope that the continual RL community can benefit from our contributions, to accelerate the development of new continual RL algorithms.