 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Generalizing Verifiable Instruction Following
Jul 03, 2025A crucial factor for successful human and AI interaction is the ability of language models or chatbots to follow human instructions precisely. A common feature of instructions are output constraints like ``only answer with yes or no" or ``mention the word `abrakadabra' at least 3 times" that the user adds to craft a more useful answer. Even today's strongest models struggle with fulfilling such constraints. We find that most models strongly overfit on a small set of verifiable constraints from the benchmarks that test these abilities, a skill called precise instruction following, and are not able to generalize well to unseen output constraints. We introduce a new benchmark, IFBench, to evaluate precise instruction following generalization on 58 new, diverse, and challenging verifiable out-of-domain constraints. In addition, we perform an extensive analysis of how and on what data models can be trained to improve precise instruction following generalization. Specifically, we carefully design constraint verification modules and show that reinforcement learning with verifiable rewards (RLVR) significantly improves instruction following. In addition to IFBench, we release 29 additional new hand-annotated training constraints and verification functions, RLVR training prompts, and code.
Large-Scale Data Selection for Instruction Tuning
Mar 03, 2025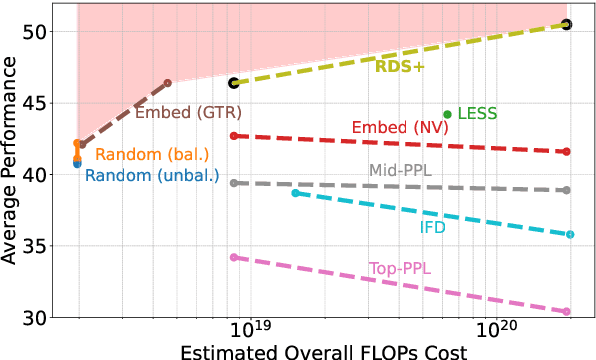


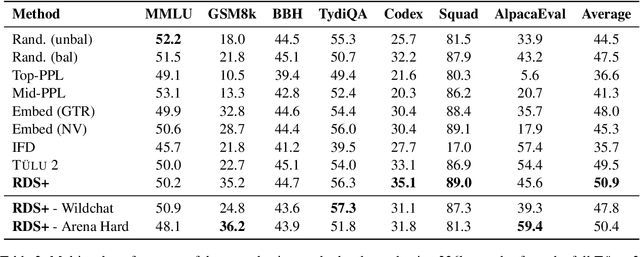
Selecting high-quality training data from a larger pool is a crucial step when instruction-tuning language models, as carefully curated datasets often produce models that outperform those trained on much larger, noisier datasets. Automated data selection approaches for instruction-tuning are typically tested by selecting small datasets (roughly 10k samples) from small pools (100-200k samples). However, popular deployed instruction-tuned models often train on hundreds of thousands to millions of samples, subsampled from even larger data pools. We present a systematic study of how well data selection methods scale to these settings, selecting up to 2.5M samples from pools of up to 5.8M samples and evaluating across 7 diverse tasks. We show that many recently proposed methods fall short of random selection in this setting (while using more compute), and even decline in performance when given access to larger pools of data to select over. However, we find that a variant of representation-based data selection (RDS+), which uses weighted mean pooling of pretrained LM hidden states, consistently outperforms more complex methods across all settings tested -- all whilst being more compute-efficient. Our findings highlight that the scaling properties of proposed automated selection methods should be more closely examined. We release our code, data, and models at https://github.com/hamishivi/automated-instruction-selection.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
HREF: Human Response-Guided Evaluation of Instruction Following in Language Models
Dec 20, 2024Evaluating the capability of Large Language Models (LLMs) in following instructions has heavily relied on a powerful LLM as the judge, introducing unresolved biases that deviate the judgments from human judges. In this work, we reevaluate various choices for automatic evaluation on a wide range of instruction-following tasks. We experiment with methods that leverage human-written responses and observe that they enhance the reliability of automatic evaluations across a wide range of tasks, resulting in up to a 3.2% improvement in agreement with human judges. We also discovered that human-written responses offer an orthogonal perspective to model-generated responses in following instructions and should be used as an additional context when comparing model responses. Based on these observations, we develop a new evaluation benchmark, Human Response-Guided Evaluation of Instruction Following (HREF), comprising 4,258 samples across 11 task categories with a composite evaluation setup, employing a composite evaluation setup that selects the most reliable method for each category. In addition to providing reliable evaluation, HREF emphasizes individual task performance and is free from contamination. Finally, we study the impact of key design choices in HREF, including the size of the evaluation set, the judge model, the baseline model, and the prompt template. We host a live leaderboard that evaluates LLMs on the private evaluation set of HREF.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024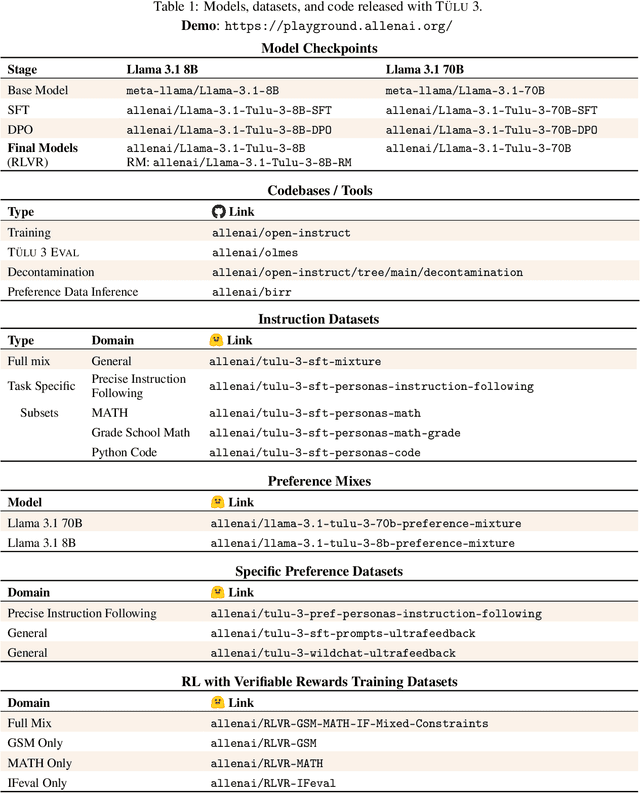



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
Oct 24, 2024



Learning from human feedback has enabled the alignment of language models (LMs) with human preferences. However, directly collecting human preferences can be expensive, time-consuming, and can have high variance. An appealing alternative is to distill preferences from LMs as a source of synthetic annotations as they are more consistent, cheaper, and scale better than human annotation; however, they are also prone to biases and errors. In this work, we introduce a routing framework that combines inputs from humans and LMs to achieve better annotation quality, while reducing the total cost of human annotation. The crux of our approach is to identify preference instances that will benefit from human annotations. We formulate this as an optimization problem: given a preference dataset and an evaluation metric, we train a performance prediction model to predict a reward model's performance on an arbitrary combination of human and LM annotations and employ a routing strategy that selects a combination that maximizes predicted performance. We train the performance prediction model on MultiPref, a new preference dataset with 10K instances paired with human and LM labels. We show that the selected hybrid mixture of LM and direct human preferences using our routing framework achieves better reward model performance compared to using either one exclusively. We simulate selective human preference collection on three other datasets and show that our method generalizes well to all three. We analyze features from the routing model to identify characteristics of instances that can benefit from human feedback, e.g., prompts with a moderate safety concern or moderate intent complexity. We release the dataset, annotation platform, and source code used in this study to foster more efficient and accurate preference collection in the future.
Scalable Data Ablation Approximations for Language Models through Modular Training and Merging
Oct 21, 2024


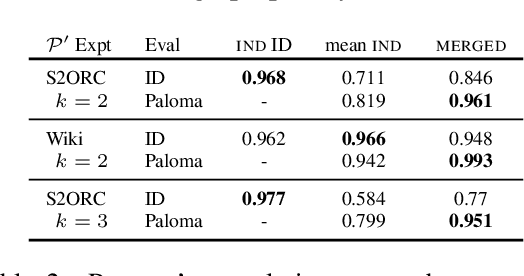
Training data compositions for Large Language Models (LLMs) can significantly affect their downstream performance. However, a thorough data ablation study exploring large sets of candidate data mixtures is typically prohibitively expensive since the full effect is seen only after training the models; this can lead practitioners to settle for sub-optimal data mixtures. We propose an efficient method for approximating data ablations which trains individual models on subsets of a training corpus and reuses them across evaluations of combinations of subsets. In continued pre-training experiments, we find that, given an arbitrary evaluation set, the perplexity score of a single model trained on a candidate set of data is strongly correlated with perplexity scores of parameter averages of models trained on distinct partitions of that data. From this finding, we posit that researchers and practitioners can conduct inexpensive simulations of data ablations by maintaining a pool of models that were each trained on partitions of a large training corpus, and assessing candidate data mixtures by evaluating parameter averages of combinations of these models. This approach allows for substantial improvements in amortized training efficiency -- scaling only linearly with respect to new data -- by enabling reuse of previous training computation, opening new avenues for improving model performance through rigorous, incremental data assessment and mixing.
Merge to Learn: Efficiently Adding Skills to Language Models with Model Merging
Oct 16, 2024


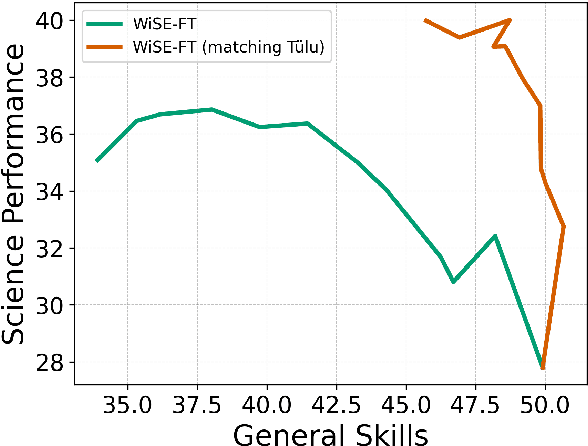
Adapting general-purpose language models to new skills is currently an expensive process that must be repeated as new instruction datasets targeting new skills are created, or can cause the models to forget older skills. In this work, we investigate the effectiveness of adding new skills to preexisting models by training on the new skills in isolation and later merging with the general model (e.g. using task vectors). In experiments focusing on scientific literature understanding, safety, and coding, we find that the parallel-train-then-merge procedure, which is significantly cheaper than retraining the models on updated data mixtures, is often comparably effective. Our experiments also show that parallel training is especially well-suited for enabling safety features in LMs relative to continued finetuning and retraining, as it dramatically improves model compliance with safe prompts while preserving its ability to refuse dangerous or harmful prompts.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024
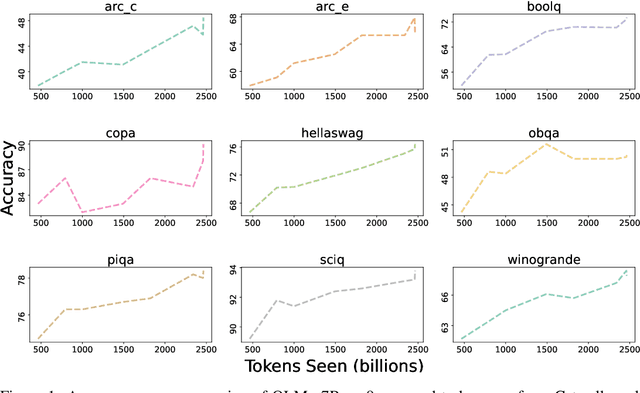
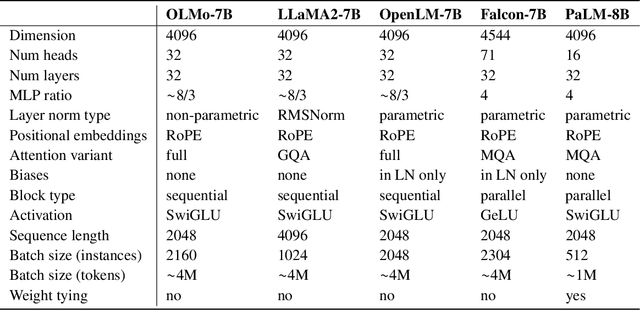
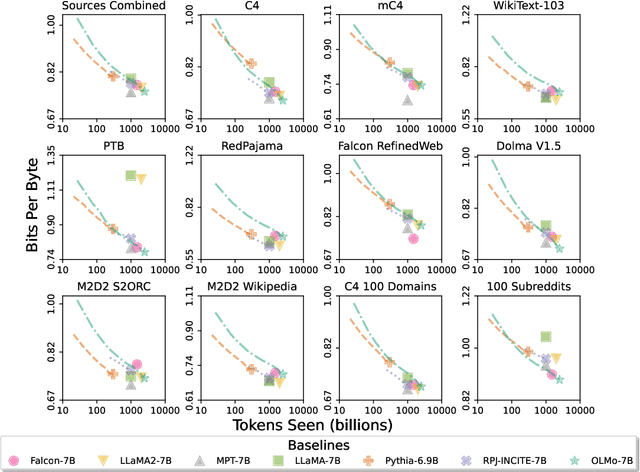
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.