 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALoGEN: Fantastic LLM Hallucinations and Where to Find Them
Jan 14, 2025



Despite their impressive ability to generate high-quality and fluent text, generative large language models (LLMs) also produce hallucinations: statements that are misaligned with established world knowledge or provided input context. However, measuring hallucination can be challenging, as having humans verify model generations on-the-fly is both expensive and time-consuming. In this work, we release HALoGEN, a comprehensive hallucination benchmark consisting of: (1) 10,923 prompts for generative models spanning nine domains including programming, scientific attribution, and summarization, and (2) automatic high-precision verifiers for each use case that decompose LLM generations into atomic units, and verify each unit against a high-quality knowledge source. We use this framework to evaluate ~150,000 generations from 14 language models, finding that even the best-performing models are riddled with hallucinations (sometimes up to 86% of generated atomic facts depending on the domain). We further define a novel error classification for LLM hallucinations based on whether they likely stem from incorrect recollection of training data (Type A errors), or incorrect knowledge in training data (Type B errors), or are fabrication (Type C errors). We hope our framework provides a foundation to enable the principled study of why generative models hallucinate, and advances the development of trustworthy large language models.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Nov 21, 2024



Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar's datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o's correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o's 32%. We open-source all of our code, models, datastore, data and a public demo.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
CHIME: LLM-Assisted Hierarchical Organization of Scientific Studies for Literature Review Support
Jul 23, 2024



Literature review requires researchers to synthesize a large amount of information and is increasingly challenging as the scientific literature expands. In this work, we investigate the potential of LLMs for producing hierarchical organizations of scientific studies to assist researchers with literature review. We define hierarchical organizations as tree structures where nodes refer to topical categories and every node is linked to the studies assigned to that category. Our naive LLM-based pipeline for hierarchy generation from a set of studies produces promising yet imperfect hierarchies, motivating us to collect CHIME, an expert-curated dataset for this task focused on biomedicine. Given the challenging and time-consuming nature of building hierarchies from scratch, we use a human-in-the-loop process in which experts correct errors (both links between categories and study assignment) in LLM-generated hierarchies. CHIME contains 2,174 LLM-generated hierarchies covering 472 topics, and expert-corrected hierarchies for a subset of 100 topics. Expert corrections allow us to quantify LLM performance, and we find that while they are quite good at generating and organizing categories, their assignment of studies to categories could be improved. We attempt to train a corrector model with human feedback which improves study assignment by 12.6 F1 points. We release our dataset and models to encourage research on developing better assistive tools for literature review.
SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific Literature
Jun 10, 2024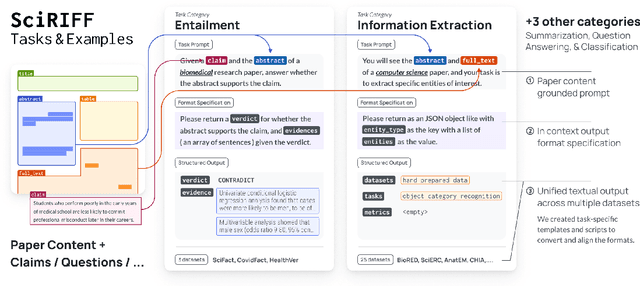
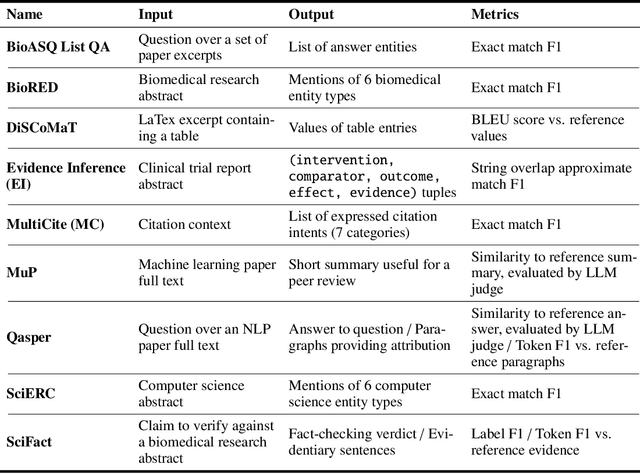
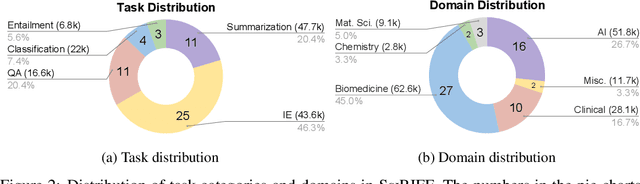
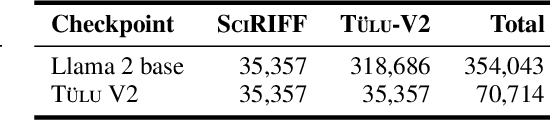
We present SciRIFF (Scientific Resource for Instruction-Following and Finetuning), a dataset of 137K instruction-following demonstrations for 54 tasks covering five essential scientific literature understanding capabilities: information extraction, summarization, question answering, claim verification, and classification. SciRIFF demonstrations are notable for their long input contexts, detailed task specifications, and complex structured outputs. While instruction-following resources are available in specific domains such as clinical medicine and chemistry, SciRIFF is the first dataset focused on extracting and synthesizing information from research literature across a wide range of scientific fields. To demonstrate the utility of SciRIFF, we develop a sample-efficient strategy to adapt a general instruction-following model for science by performing additional finetuning on a mix of general-domain and SciRIFF demonstrations. In evaluations on nine held-out scientific tasks, our model -- called SciTulu -- improves over a strong LLM baseline by 28.1% and 6.5% at the 7B and 70B scales respectively, while maintaining general instruction-following performance within 2% of the baseline. We are optimistic that SciRIFF will facilitate the development and evaluation of LLMs to help researchers navigate the ever-growing body of scientific literature. We release our dataset, model checkpoints, and data processing and evaluation code to enable further research.
Source-Aware Training Enables Knowledge Attribution in Language Models
Apr 11, 2024Large language models (LLMs) learn a vast amount of knowledge during pretraining, but they are often oblivious to the source(s) of such knowledge. We investigate the problem of intrinsic source citation, where LLMs are required to cite the pretraining source supporting a generated response. Intrinsic source citation can enhance LLM transparency, interpretability, and verifiability. To give LLMs such ability, we explore source-aware training -- a post pretraining recipe that involves (i) training the LLM to associate unique source document identifiers with the knowledge in each document, followed by (ii) an instruction-tuning to teach the LLM to cite a supporting pretraining source when prompted. Source-aware training can easily be applied to pretrained LLMs off the shelf, and diverges minimally from existing pretraining/fine-tuning frameworks. Through experiments on carefully curated data, we demonstrate that our training recipe can enable faithful attribution to the pretraining data without a substantial impact on the model's quality compared to standard pretraining. Our results also highlight the importance of data augmentation in achieving attribution. Code and data available here: \url{https://github.com/mukhal/intrinsic-source-citation}
KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research Questions
Mar 06, 2024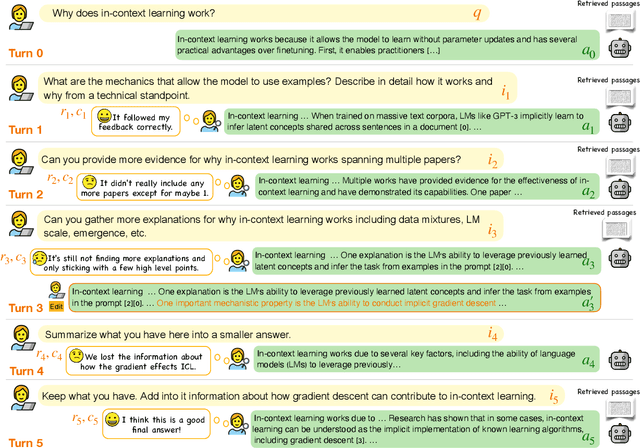

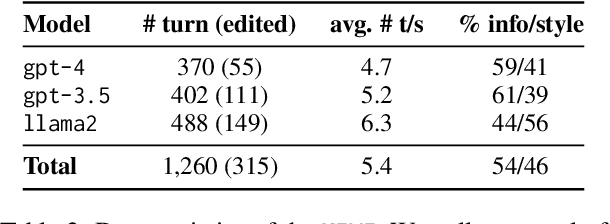
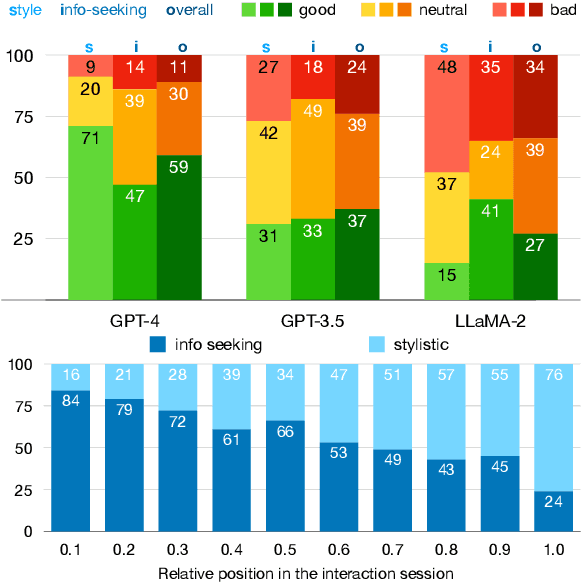
Large language models (LLMs) adapted to follow user instructions are now widely deployed as conversational agents. In this work, we examine one increasingly common instruction-following task: providing writing assistance to compose a long-form answer. To evaluate the capabilities of current LLMs on this task, we construct KIWI, a dataset of knowledge-intensive writing instructions in the scientific domain. Given a research question, an initial model-generated answer and a set of relevant papers, an expert annotator iteratively issues instructions for the model to revise and improve its answer. We collect 1,260 interaction turns from 234 interaction sessions with three state-of-the-art LLMs. Each turn includes a user instruction, a model response, and a human evaluation of the model response. Through a detailed analysis of the collected responses, we find that all models struggle to incorporate new information into an existing answer, and to perform precise and unambiguous edits. Further, we find that models struggle to judge whether their outputs successfully followed user instructions, with accuracy at least 10 points short of human agreement. Our findings indicate that KIWI will be a valuable resource to measure progress and improve LLMs' instruction-following capabilities for knowledge intensive writing tasks.
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
Nov 20, 2023Since the release of T\"ULU [Wang et al., 2023b], open resources for instruction tuning have developed quickly, from better base models to new finetuning techniques. We test and incorporate a number of these advances into T\"ULU, resulting in T\"ULU 2, a suite of improved T\"ULU models for advancing the understanding and best practices of adapting pretrained language models to downstream tasks and user preferences. Concretely, we release: (1) T\"ULU-V2-mix, an improved collection of high-quality instruction datasets; (2) T\"ULU 2, LLAMA-2 models finetuned on the V2 mixture; (3) T\"ULU 2+DPO, T\"ULU 2 models trained with direct preference optimization (DPO), including the largest DPO-trained model to date (T\"ULU 2+DPO 70B); (4) CODE T\"ULU 2, CODE LLAMA models finetuned on our V2 mix that outperform CODE LLAMA and its instruction-tuned variant, CODE LLAMA-Instruct. Our evaluation from multiple perspectives shows that the T\"ULU 2 suite achieves state-of-the-art performance among open models and matches or exceeds the performance of GPT-3.5-turbo-0301 on several benchmarks. We release all the checkpoints, data, training and evaluation code to facilitate future open efforts on adapting large language models.
Language Models Hallucinate, but May Excel at Fact Verification
Oct 23, 2023Recent progress in natural language processing (NLP) owes much to remarkable advances in large language models (LLMs). Nevertheless, LLMs frequently "hallucinate," resulting in non-factual outputs. Our carefully designed human evaluation substantiates the serious hallucination issue, revealing that even GPT-3.5 produces factual outputs less than 25% of the time. This underscores the importance of fact verifiers in order to measure and incentivize progress. Our systematic investigation affirms that LLMs can be repurposed as effective fact verifiers with strong correlations with human judgments, at least in the Wikipedia domain. Surprisingly, FLAN-T5-11B, the least factual generator in our study, performs the best as a fact verifier, even outperforming more capable LLMs like GPT3.5 and ChatGPT. Delving deeper, we analyze the reliance of these LLMs on high-quality evidence, as well as their deficiencies in robustness and generalization ability. Our study presents insights for developing trustworthy generation models.