 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRACULA: Hunting for the Actions Users Want Deep Research Agents to Execute
Apr 26, 2026Scientific Deep Research (DR) agents answer user queries by synthesizing research papers into multi-section reports. User feedback can improve their utility, but existing protocols only score the final report, making it hard to study and learn which intermediate actions DR agents should take to improve reports. We collect DRACULA, the first dataset with user feedback on intermediate actions for DR. Over five weeks, nineteen expert CS researchers ask queries to a DR system that proposes actions (e.g., "Add a section on datasets"). Our users select actions they prefer, then judge whether an output report applied their selections successfully, yielding 8,103 action preferences and 5,230 execution judgments. After confirming a DR agent can execute DRACULA's actions, we study the predictability of user-preferred actions via simulation-how well LLMs predict the actions users select-a step toward learning to generate useful actions. We discover: (1) LLM judges initially struggle to predict action selections, but improve most when using a user's full selection history, rather than self-reported or extrapolated user context signals; (2) Users' selections for the same query differ based on unstated goals, bottlenecking simulation and motivating affordances that let users steer reports; and (3) Our simulation results inform an online intervention that generates new actions based on the user's past interactions, which users pick most often in follow-up studies. Overall, while work extensively studies execution, DRACULA reveals a key challenge is deciding which actions to execute in the first place. We open-source DRACULA's study design, user feedback, and simulation tasks to spur future work on action feedback for long-horizon agents.
LitPivot: Developing Well-Situated Research Ideas Through Dynamic Contextualization and Critique within the Literature Landscape
Apr 03, 2026Developing a novel research idea is hard. It must be distinct enough from prior work to claim a contribution while also building on it. This requires iteratively reviewing literature and refining an idea based on what a researcher reads; yet when an idea changes, the literature that matters often changes with it. Most tools offer limited support for this interplay: literature tools help researchers understand a fixed body of work, while ideation tools evaluate ideas against a static, pre-curated set of papers. We introduce literature-initiated pivots, a mechanism where engagement with literature prompts revision to a developing idea, and where that revision changes which literature is relevant. We operationalize this in LitPivot, where researchers concurrently draft and vet an idea. LitPivot dynamically retrieves clusters of papers relevant to a selected part of the idea and proposes literature-informed critiques for how to revise it. A lab study ($n{=}17$) shows researchers produced higher-rated ideas with stronger self-reported understanding of the literature space; an open-ended study ($n{=}5$) reveals how researchers use LitPivot to iteratively evolve their own ideas.
Improving Attributed Long-form Question Answering with Intent Awareness
Mar 28, 2026Large language models (LLMs) are increasingly being used to generate comprehensive, knowledge-intensive reports. However, while these models are trained on diverse academic papers and reports, they are not exposed to the reasoning processes and intents that guide authors in crafting these documents. We hypothesize that enhancing a model's intent awareness can significantly improve the quality of generated long-form reports. We develop and employ structured, tag-based schemes to better elicit underlying implicit intents to write or cite. We demonstrate that these extracted intents enhance both zero-shot generation capabilities in LLMs and enable the creation of high-quality synthetic data for fine-tuning smaller models. Our experiments reveal improved performance across various challenging scientific report generation tasks, with an average improvement of +2.9 and +12.3 absolute points for large and small models over baselines, respectively. Furthermore, our analysis illuminates how intent awareness enhances model citation usage and substantially improves report readability.
* 39 pages, 7 figures
Language Models Don't Know What You Want: Evaluating Personalization in Deep Research Needs Real Users
Mar 17, 2026Deep Research (DR) tools (e.g. OpenAI DR) help researchers cope with ballooning publishing counts. Such tools can synthesize scientific papers to answer researchers' queries, but lack understanding of their users. We change that in MyScholarQA (MySQA), a personalized DR tool that: 1) infers a profile of a user's research interests; 2) proposes personalized actions for a user's input query; and 3) writes a multi-section report for the query that follows user-approved actions. We first test MySQA with NLP's standard protocol: we design a benchmark of synthetic users and LLM judges, where MySQA beats baselines in citation metrics and personalized action-following. However, we suspect this process does not cover all aspects of personalized DR users value, so we interview users in an online version of MySQA to unmask them. We reveal nine nuanced errors of personalized DR undetectable by our LLM judges, and we study qualitative feedback to form lessons for future DR design. In all, we argue for a pillar of personalization that easy-to-use LLM judges can lead NLP to overlook: real progress in personalization is only possible with real users.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Ai2 Scholar QA: Organized Literature Synthesis with Attribution
Apr 15, 2025Retrieval-augmented generation is increasingly effective in answering scientific questions from literature, but many state-of-the-art systems are expensive and closed-source. We introduce Ai2 Scholar QA, a free online scientific question answering application. To facilitate research, we make our entire pipeline public: as a customizable open-source Python package and interactive web app, along with paper indexes accessible through public APIs and downloadable datasets. We describe our system in detail and present experiments analyzing its key design decisions. In an evaluation on a recent scientific QA benchmark, we find that Ai2 Scholar QA outperforms competing systems.
Exploring Long-Term Prediction of Type 2 Diabetes Microvascular Complications
Dec 02, 2024



Electronic healthcare records (EHR) contain a huge wealth of data that can support the prediction of clinical outcomes. EHR data is often stored and analysed using clinical codes (ICD10, SNOMED), however these can differ across registries and healthcare providers. Integrating data across systems involves mapping between different clinical ontologies requiring domain expertise, and at times resulting in data loss. To overcome this, code-agnostic models have been proposed. We assess the effectiveness of a code-agnostic representation approach on the task of long-term microvascular complication prediction for individuals living with Type 2 Diabetes. Our method encodes individual EHRs as text using fine-tuned, pretrained clinical language models. Leveraging large-scale EHR data from the UK, we employ a multi-label approach to simultaneously predict the risk of microvascular complications across 1-, 5-, and 10-year windows. We demonstrate that a code-agnostic approach outperforms a code-based model and illustrate that performance is better with longer prediction windows but is biased to the first occurring complication. Overall, we highlight that context length is vitally important for model performance. This study highlights the possibility of including data from across different clinical ontologies and is a starting point for generalisable clinical models.
ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language Models
Oct 25, 2024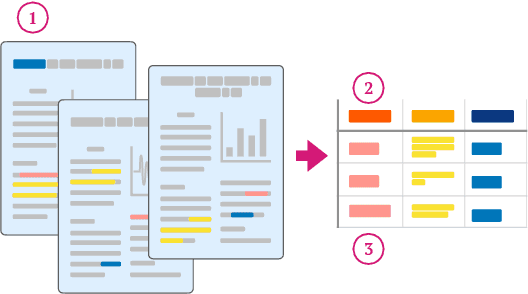

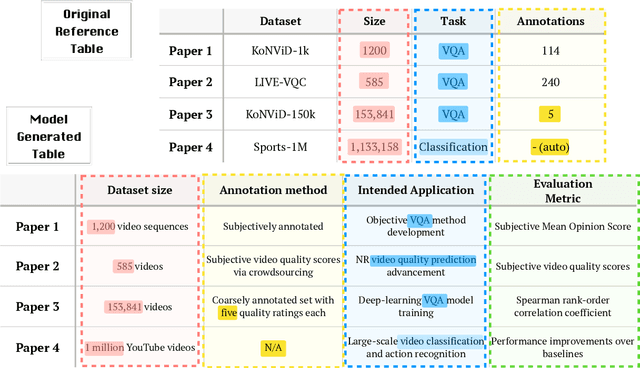
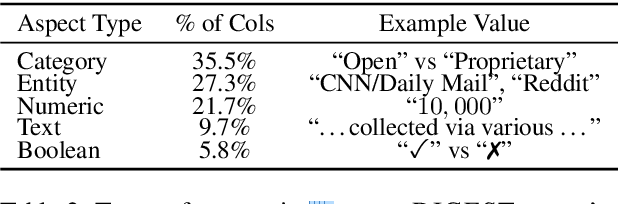
When conducting literature reviews, scientists often create literature review tables - tables whose rows are publications and whose columns constitute a schema, a set of aspects used to compare and contrast the papers. Can we automatically generate these tables using language models (LMs)? In this work, we introduce a framework that leverages LMs to perform this task by decomposing it into separate schema and value generation steps. To enable experimentation, we address two main challenges: First, we overcome a lack of high-quality datasets to benchmark table generation by curating and releasing arxivDIGESTables, a new dataset of 2,228 literature review tables extracted from ArXiv papers that synthesize a total of 7,542 research papers. Second, to support scalable evaluation of model generations against human-authored reference tables, we develop DecontextEval, an automatic evaluation method that aligns elements of tables with the same underlying aspects despite differing surface forms. Given these tools, we evaluate LMs' abilities to reconstruct reference tables, finding this task benefits from additional context to ground the generation (e.g. table captions, in-text references). Finally, through a human evaluation study we find that even when LMs fail to fully reconstruct a reference table, their generated novel aspects can still be useful.
CHIME: LLM-Assisted Hierarchical Organization of Scientific Studies for Literature Review Support
Jul 23, 2024



Literature review requires researchers to synthesize a large amount of information and is increasingly challenging as the scientific literature expands. In this work, we investigate the potential of LLMs for producing hierarchical organizations of scientific studies to assist researchers with literature review. We define hierarchical organizations as tree structures where nodes refer to topical categories and every node is linked to the studies assigned to that category. Our naive LLM-based pipeline for hierarchy generation from a set of studies produces promising yet imperfect hierarchies, motivating us to collect CHIME, an expert-curated dataset for this task focused on biomedicine. Given the challenging and time-consuming nature of building hierarchies from scratch, we use a human-in-the-loop process in which experts correct errors (both links between categories and study assignment) in LLM-generated hierarchies. CHIME contains 2,174 LLM-generated hierarchies covering 472 topics, and expert-corrected hierarchies for a subset of 100 topics. Expert corrections allow us to quantify LLM performance, and we find that while they are quite good at generating and organizing categories, their assignment of studies to categories could be improved. We attempt to train a corrector model with human feedback which improves study assignment by 12.6 F1 points. We release our dataset and models to encourage research on developing better assistive tools for literature review.
SciRIFF: A Resource to Enhance Language Model Instruction-Following over Scientific Literature
Jun 10, 2024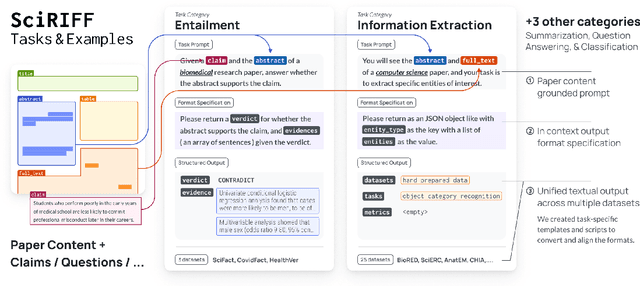
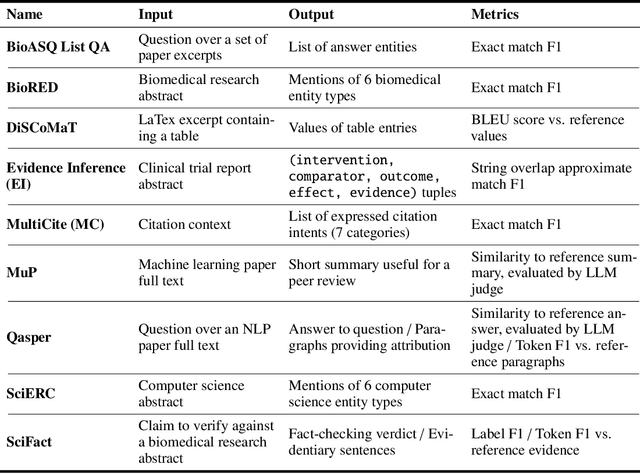
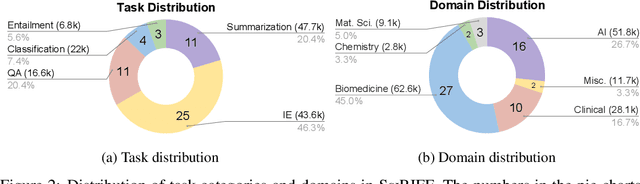
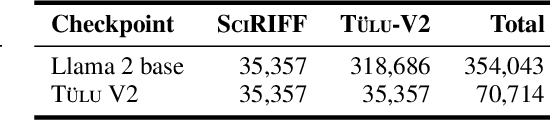
We present SciRIFF (Scientific Resource for Instruction-Following and Finetuning), a dataset of 137K instruction-following demonstrations for 54 tasks covering five essential scientific literature understanding capabilities: information extraction, summarization, question answering, claim verification, and classification. SciRIFF demonstrations are notable for their long input contexts, detailed task specifications, and complex structured outputs. While instruction-following resources are available in specific domains such as clinical medicine and chemistry, SciRIFF is the first dataset focused on extracting and synthesizing information from research literature across a wide range of scientific fields. To demonstrate the utility of SciRIFF, we develop a sample-efficient strategy to adapt a general instruction-following model for science by performing additional finetuning on a mix of general-domain and SciRIFF demonstrations. In evaluations on nine held-out scientific tasks, our model -- called SciTulu -- improves over a strong LLM baseline by 28.1% and 6.5% at the 7B and 70B scales respectively, while maintaining general instruction-following performance within 2% of the baseline. We are optimistic that SciRIFF will facilitate the development and evaluation of LLMs to help researchers navigate the ever-growing body of scientific literature. We release our dataset, model checkpoints, and data processing and evaluation code to enable further research.