 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025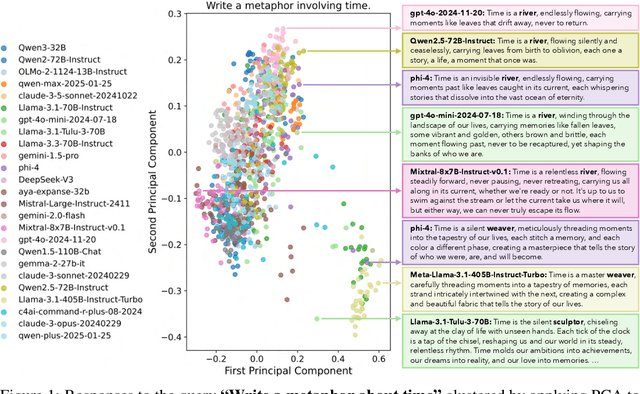
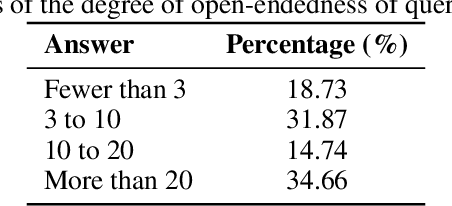
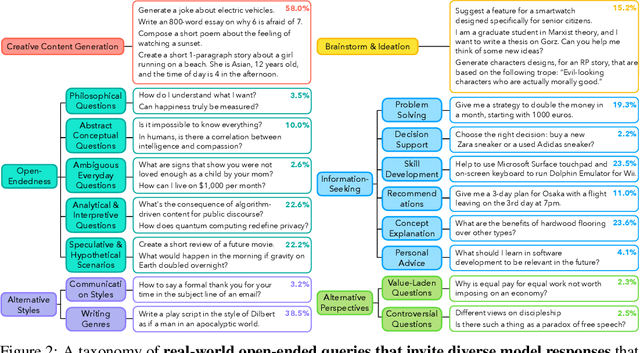

Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language Models
Oct 25, 2024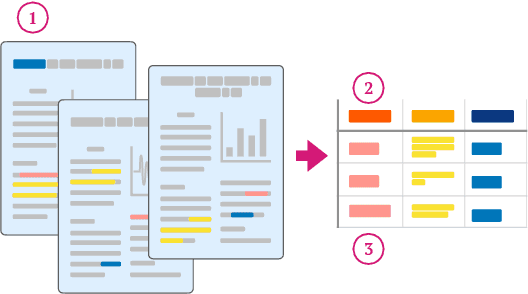

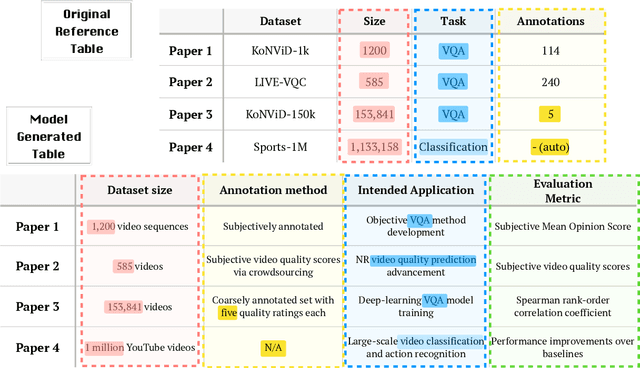
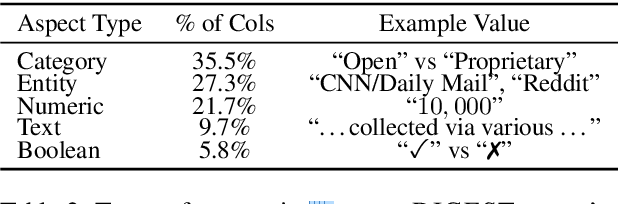
When conducting literature reviews, scientists often create literature review tables - tables whose rows are publications and whose columns constitute a schema, a set of aspects used to compare and contrast the papers. Can we automatically generate these tables using language models (LMs)? In this work, we introduce a framework that leverages LMs to perform this task by decomposing it into separate schema and value generation steps. To enable experimentation, we address two main challenges: First, we overcome a lack of high-quality datasets to benchmark table generation by curating and releasing arxivDIGESTables, a new dataset of 2,228 literature review tables extracted from ArXiv papers that synthesize a total of 7,542 research papers. Second, to support scalable evaluation of model generations against human-authored reference tables, we develop DecontextEval, an automatic evaluation method that aligns elements of tables with the same underlying aspects despite differing surface forms. Given these tools, we evaluate LMs' abilities to reconstruct reference tables, finding this task benefits from additional context to ground the generation (e.g. table captions, in-text references). Finally, through a human evaluation study we find that even when LMs fail to fully reconstruct a reference table, their generated novel aspects can still be useful.
Scideator: Human-LLM Scientific Idea Generation Grounded in Research-Paper Facet Recombination
Sep 23, 2024



The scientific ideation process often involves blending salient aspects of existing papers to create new ideas. To see if large language models (LLMs) can assist this process, we contribute Scideator, a novel mixed-initiative tool for scientific ideation. Starting from a user-provided set of papers, Scideator extracts key facets (purposes, mechanisms, and evaluations) from these and relevant papers, allowing users to explore the idea space by interactively recombining facets to synthesize inventive ideas. Scideator also helps users to gauge idea novelty by searching the literature for potential overlaps and showing automated novelty assessments and explanations. To support these tasks, Scideator introduces four LLM-powered retrieval-augmented generation (RAG) modules: Analogous Paper Facet Finder, Faceted Idea Generator, Idea Novelty Checker, and Idea Novelty Iterator. In a within-subjects user study, 19 computer-science researchers identified significantly more interesting ideas using Scideator compared to a strong baseline combining a scientific search engine with LLM interaction.
A Controllable QA-based Framework for Decontextualization
May 24, 2023Many real-world applications require surfacing extracted snippets to users, whether motivated by assistive tools for literature surveys or document cross-referencing, or needs to mitigate and recover from model generated inaccuracies., Yet, these passages can be difficult to consume when divorced from their original document context. In this work, we explore the limits of LLMs to perform decontextualization of document snippets in user-facing scenarios, focusing on two real-world settings - question answering and citation context previews for scientific documents. We propose a question-answering framework for decontextualization that allows for better handling of user information needs and preferences when determining the scope of rewriting. We present results showing state-of-the-art LLMs under our framework remain competitive with end-to-end approaches. We also explore incorporating user preferences into the system, finding our framework allows for controllability.
In Search of Verifiability: Explanations Rarely Enable Complementary Performance in AI-Advised Decision Making
May 16, 2023The current literature on AI-advised decision making -- involving explainable AI systems advising human decision makers -- presents a series of inconclusive and confounding results. To synthesize these findings, we propose a simple theory that elucidates the frequent failure of AI explanations to engender appropriate reliance and complementary decision making performance. We argue explanations are only useful to the extent that they allow a human decision maker to verify the correctness of an AI's prediction, in contrast to other desiderata, e.g., interpretability or spelling out the AI's reasoning process. Prior studies find in many decision making contexts AI explanations do not facilitate such verification. Moreover, most contexts fundamentally do not allow verification, regardless of explanation method. We conclude with a discussion of potential approaches for more effective explainable AI-advised decision making and human-AI collaboration.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
Augmenting Scientific Papers with Just-in-Time, Position-Sensitive Definitions of Terms and Symbols
Sep 29, 2020
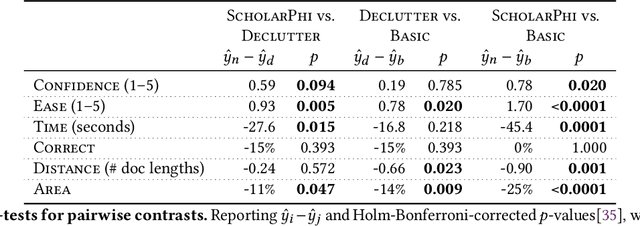

Despite the central importance of research papers to scientific progress, they can be difficult to read. Comprehension is often stymied when the information needed to understand a passage resides somewhere else: in another section, or in another paper. In this work, we envision how interfaces can bring definitions of technical terms and symbols to readers when and where they need them most. We introduce ScholarPhi, an augmented reading interface with four novel features: (1) tooltips that surface position-sensitive definitions from elsewhere in a paper, (2) a filter over the paper that "declutters" it to reveal how the term or symbol is used across the paper, (3) automatic equation diagrams that expose multiple definitions in parallel, and (4) an automatically generated glossary of important terms and symbols. A usability study showed that the tool helps researchers of all experience levels read papers. Furthermore, researchers were eager to have ScholarPhi's definitions available to support their everyday reading.
Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance
Jun 30, 2020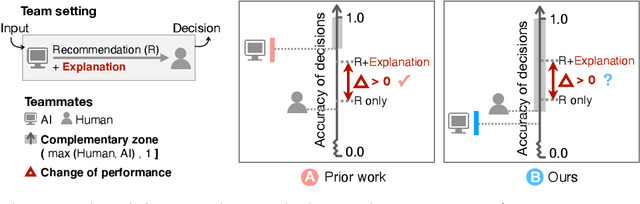
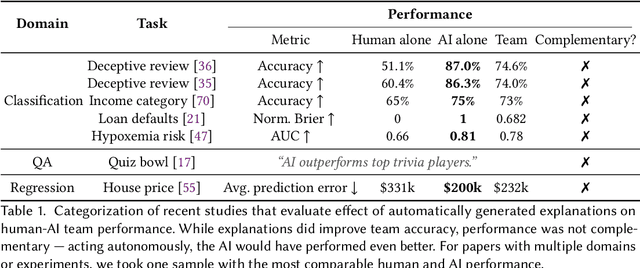
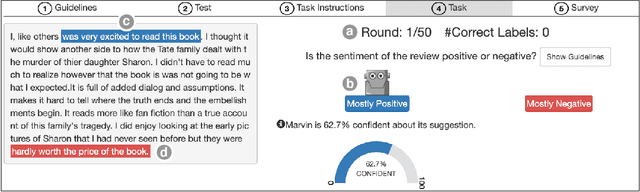
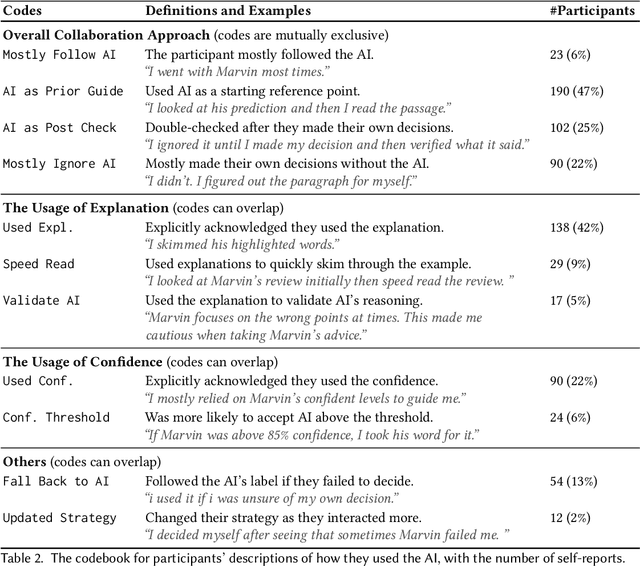
Increasingly, organizations are pairing humans with AI systems to improve decision-making and reducing costs. Proponents of human-centered AI argue that team performance can even further improve when the AI model explains its recommendations. However, a careful analysis of existing literature reveals that prior studies observed improvements due to explanations only when the AI, alone, outperformed both the human and the best human-AI team. This raises an important question: can explanations lead to complementary performance, i.e., with accuracy higher than both the human and the AI working alone? We address this question by devising comprehensive studies on human-AI teaming, where participants solve a task with help from an AI system without explanations and from one with varying types of AI explanation support. We carefully controlled to ensure comparable human and AI accuracy across experiments on three NLP datasets (two for sentiment analysis and one for question answering). While we found complementary improvements from AI augmentation, they were not increased by state-of-the-art explanations compared to simpler strategies, such as displaying the AI's confidence. We show that explanations increase the chance that humans will accept the AI's recommendation regardless of whether the AI is correct. While this clarifies the gains in team performance from explanations in prior work, it poses new challenges for human-centered AI: how can we best design systems to produce complementary performance? Can we develop explanatory approaches that help humans decide whether and when to trust AI input?