 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
Nov 20, 2023



Since the release of T\"ULU [Wang et al., 2023b], open resources for instruction tuning have developed quickly, from better base models to new finetuning techniques. We test and incorporate a number of these advances into T\"ULU, resulting in T\"ULU 2, a suite of improved T\"ULU models for advancing the understanding and best practices of adapting pretrained language models to downstream tasks and user preferences. Concretely, we release: (1) T\"ULU-V2-mix, an improved collection of high-quality instruction datasets; (2) T\"ULU 2, LLAMA-2 models finetuned on the V2 mixture; (3) T\"ULU 2+DPO, T\"ULU 2 models trained with direct preference optimization (DPO), including the largest DPO-trained model to date (T\"ULU 2+DPO 70B); (4) CODE T\"ULU 2, CODE LLAMA models finetuned on our V2 mix that outperform CODE LLAMA and its instruction-tuned variant, CODE LLAMA-Instruct. Our evaluation from multiple perspectives shows that the T\"ULU 2 suite achieves state-of-the-art performance among open models and matches or exceeds the performance of GPT-3.5-turbo-0301 on several benchmarks. We release all the checkpoints, data, training and evaluation code to facilitate future open efforts on adapting large language models.
HINT: Hypernetwork Instruction Tuning for Efficient Zero-Shot Generalisation
Dec 20, 2022Recent NLP models have the great ability to generalise `zero-shot' to new tasks using only an instruction as guidance. However, these approaches usually repeat their instructions with every input, requiring costly reprocessing of lengthy instructions for every inference example. To alleviate this, we introduce Hypernetworks for INstruction Tuning (HINT), which convert task instructions and examples using a pretrained text encoder into parameter-efficient modules inserted into an underlying model, eliminating the need to include instructions in the model input. Compared to prior approaches that concatenate instructions with every input instance, we find that HINT models are significantly more compute-efficient and consistently outperform these approaches for a given inference budget.
Staged Training for Transformer Language Models
Mar 11, 2022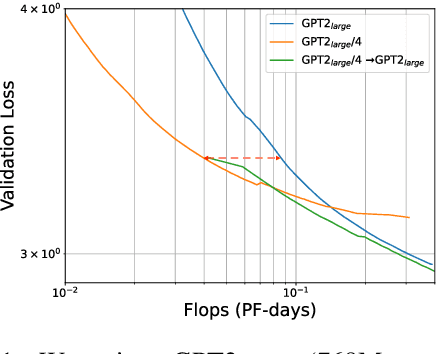
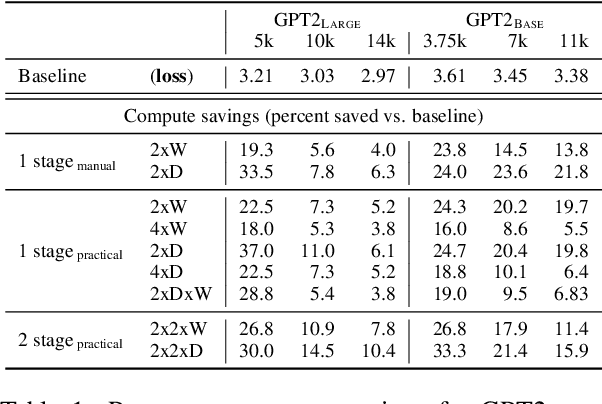
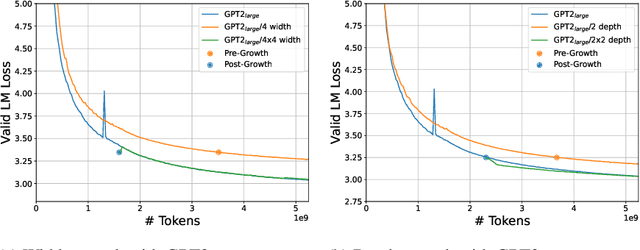
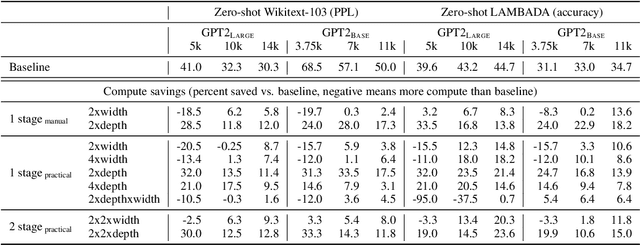
The current standard approach to scaling transformer language models trains each model size from a different random initialization. As an alternative, we consider a staged training setup that begins with a small model and incrementally increases the amount of compute used for training by applying a "growth operator" to increase the model depth and width. By initializing each stage with the output of the previous one, the training process effectively re-uses the compute from prior stages and becomes more efficient. Our growth operators each take as input the entire training state (including model parameters, optimizer state, learning rate schedule, etc.) and output a new training state from which training continues. We identify two important properties of these growth operators, namely that they preserve both the loss and the "training dynamics" after applying the operator. While the loss-preserving property has been discussed previously, to the best of our knowledge this work is the first to identify the importance of preserving the training dynamics (the rate of decrease of the loss during training). To find the optimal schedule for stages, we use the scaling laws from (Kaplan et al., 2020) to find a precise schedule that gives the most compute saving by starting a new stage when training efficiency starts decreasing. We empirically validate our growth operators and staged training for autoregressive language models, showing up to 22% compute savings compared to a strong baseline trained from scratch. Our code is available at https://github.com/allenai/staged-training.
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
Jun 01, 2021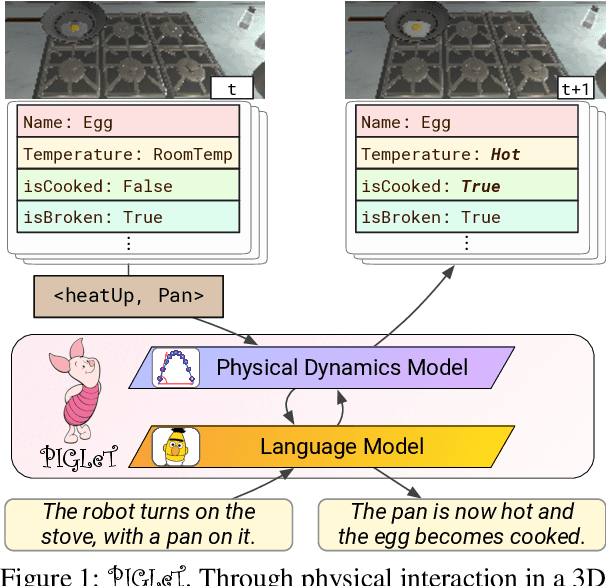
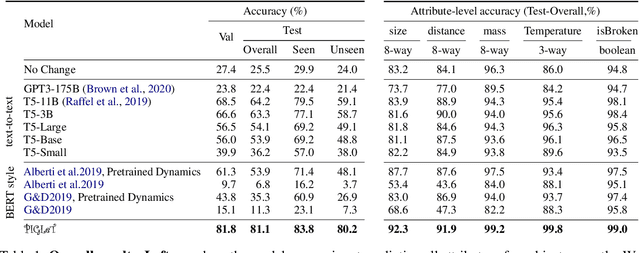

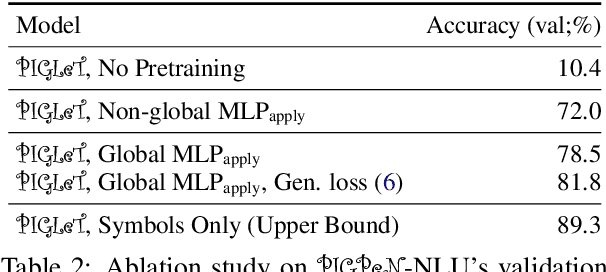
We propose PIGLeT: a model that learns physical commonsense knowledge through interaction, and then uses this knowledge to ground language. We factorize PIGLeT into a physical dynamics model, and a separate language model. Our dynamics model learns not just what objects are but also what they do: glass cups break when thrown, plastic ones don't. We then use it as the interface to our language model, giving us a unified model of linguistic form and grounded meaning. PIGLeT can read a sentence, simulate neurally what might happen next, and then communicate that result through a literal symbolic representation, or natural language. Experimental results show that our model effectively learns world dynamics, along with how to communicate them. It is able to correctly forecast "what happens next" given an English sentence over 80% of the time, outperforming a 100x larger, text-to-text approach by over 10%. Likewise, its natural language summaries of physical interactions are also judged by humans as more accurate than LM alternatives. We present comprehensive analysis showing room for future work.
Shallow Syntax in Deep Water
Aug 29, 2019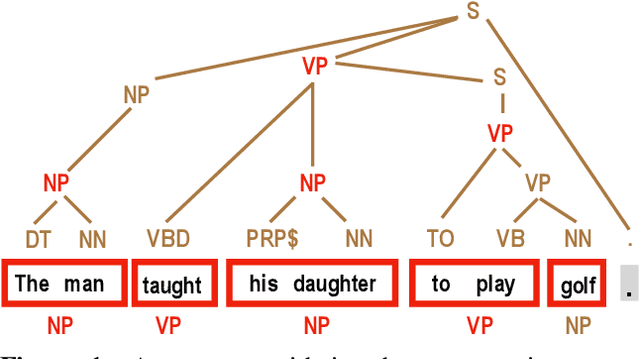
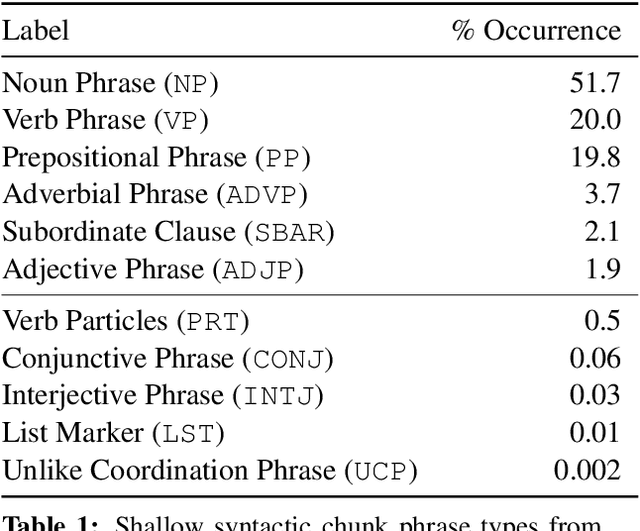
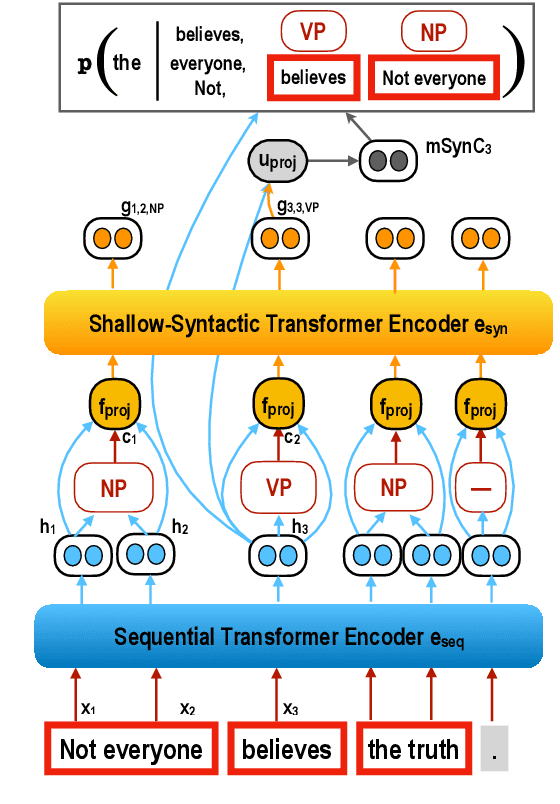
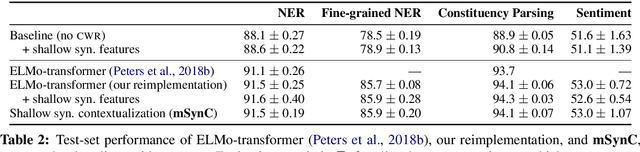
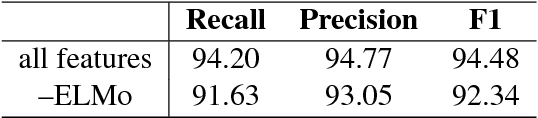
Shallow syntax provides an approximation of phrase-syntactic structure of sentences; it can be produced with high accuracy, and is computationally cheap to obtain. We investigate the role of shallow syntax-aware representations for NLP tasks using two techniques. First, we enhance the ELMo architecture to allow pretraining on predicted shallow syntactic parses, instead of just raw text, so that contextual embeddings make use of shallow syntactic context. Our second method involves shallow syntactic features obtained automatically on downstream task data. Neither approach leads to a significant gain on any of the four downstream tasks we considered relative to ELMo-only baselines. Further analysis using black-box probes confirms that our shallow-syntax-aware contextual embeddings do not transfer to linguistic tasks any more easily than ELMo's embeddings. We take these findings as evidence that ELMo-style pretraining discovers representations which make additional awareness of shallow syntax redundant.
To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks
Mar 14, 2019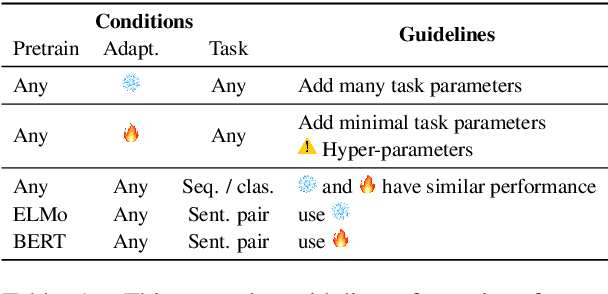
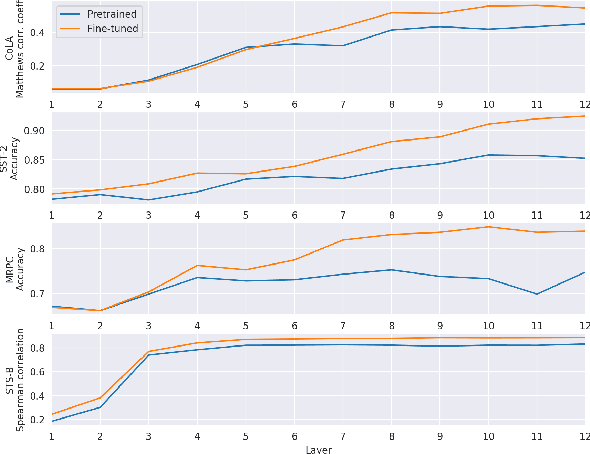
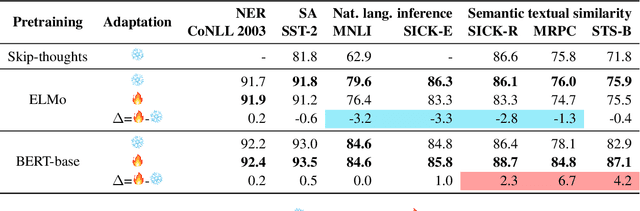
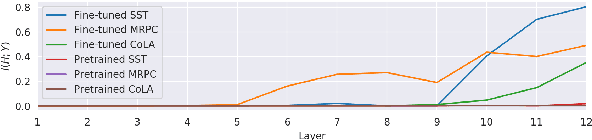
While most previous work has focused on different pretraining objectives and architectures for transfer learning, we ask how to best adapt the pretrained model to a given target task. We focus on the two most common forms of adaptation, feature extraction (where the pretrained weights are frozen), and directly fine-tuning the pretrained model. Our empirical results across diverse NLP tasks with two state-of-the-art models show that the relative performance of fine-tuning vs. feature extraction depends on the similarity of the pretraining and target tasks. We explore possible explanations for this finding and provide a set of adaptation guidelines for the NLP practitioner.
AllenNLP: A Deep Semantic Natural Language Processing Platform
May 31, 2018This paper describes AllenNLP, a platform for research on deep learning methods in natural language understanding. AllenNLP is designed to support researchers who want to build novel language understanding models quickly and easily. It is built on top of PyTorch, allowing for dynamic computation graphs, and provides (1) a flexible data API that handles intelligent batching and padding, (2) high-level abstractions for common operations in working with text, and (3) a modular and extensible experiment framework that makes doing good science easy. It also includes reference implementations of high quality approaches for both core semantic problems (e.g. semantic role labeling (Palmer et al., 2005)) and language understanding applications (e.g. machine comprehension (Rajpurkar et al., 2016)). AllenNLP is an ongoing open-source effort maintained by engineers and researchers at the Allen Institute for Artificial Intelligence.
Extending a Parser to Distant Domains Using a Few Dozen Partially Annotated Examples
May 16, 2018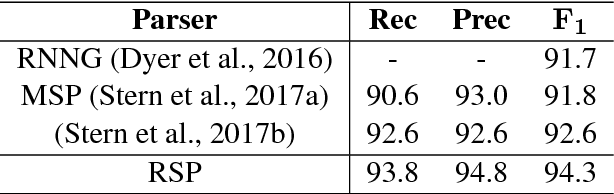

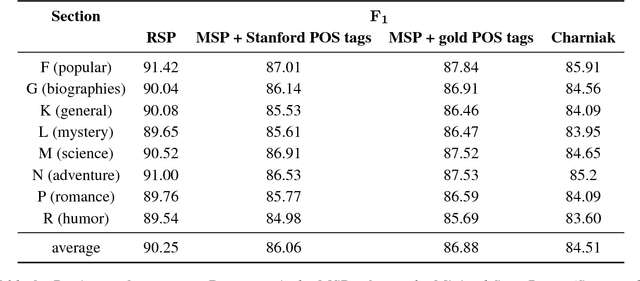
We revisit domain adaptation for parsers in the neural era. First we show that recent advances in word representations greatly diminish the need for domain adaptation when the target domain is syntactically similar to the source domain. As evidence, we train a parser on the Wall Street Jour- nal alone that achieves over 90% F1 on the Brown corpus. For more syntactically dis- tant domains, we provide a simple way to adapt a parser using only dozens of partial annotations. For instance, we increase the percentage of error-free geometry-domain parses in a held-out set from 45% to 73% using approximately five dozen training examples. In the process, we demon- strate a new state-of-the-art single model result on the Wall Street Journal test set of 94.3%. This is an absolute increase of 1.7% over the previous state-of-the-art of 92.6%.
Construction of the Literature Graph in Semantic Scholar
May 06, 2018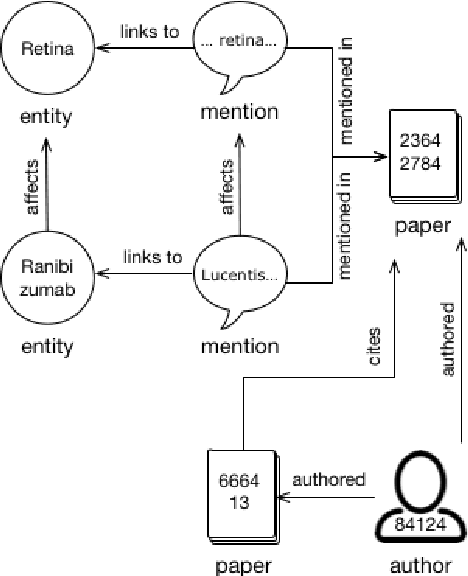
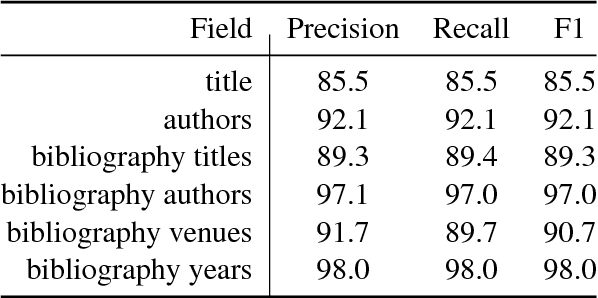
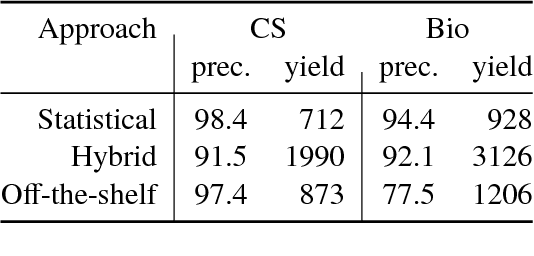

We describe a deployed scalable system for organizing published scientific literature into a heterogeneous graph to facilitate algorithmic manipulation and discovery. The resulting literature graph consists of more than 280M nodes, representing papers, authors, entities and various interactions between them (e.g., authorships, citations, entity mentions). We reduce literature graph construction into familiar NLP tasks (e.g., entity extraction and linking), point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task. The methods described in this paper are used to enable semantic features in www.semanticscholar.org