 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Nov 11, 2025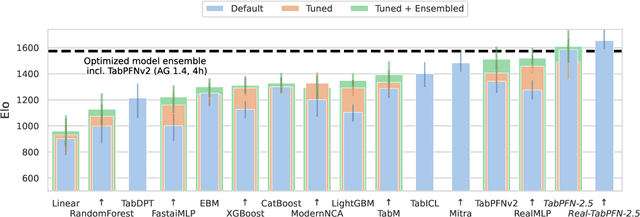
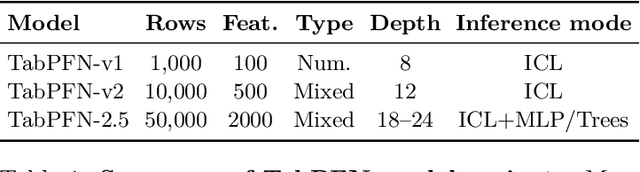
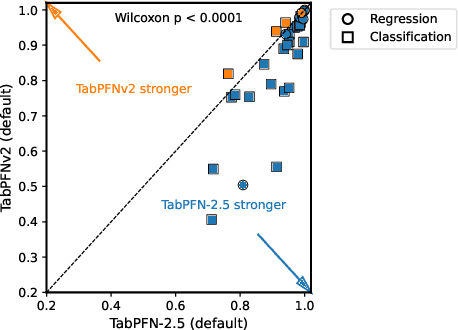
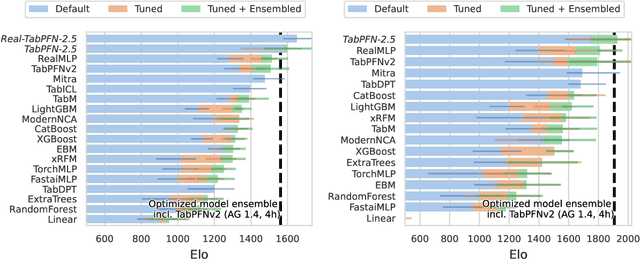
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
DeeperDive: The Unreasonable Effectiveness of Weak Supervision in Document Understanding A Case Study in Collaboration with UiPath Inc
Aug 17, 2022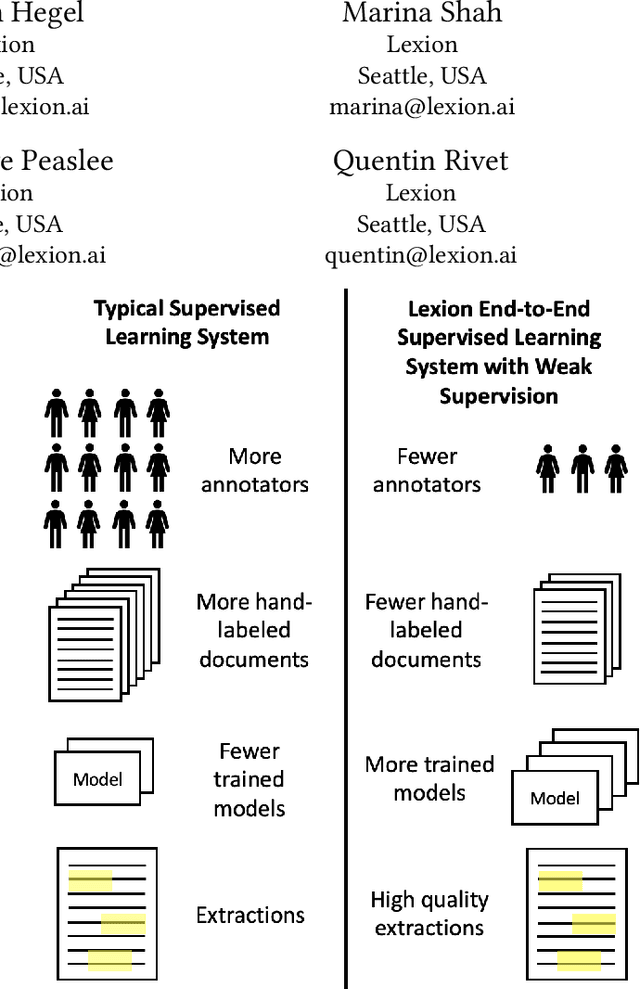


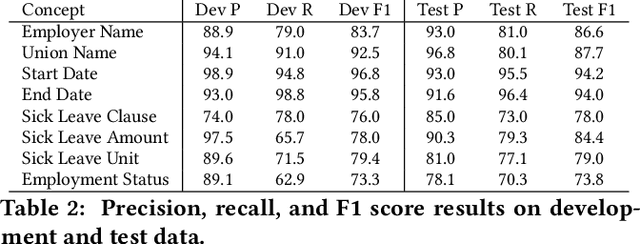
Weak supervision has been applied to various Natural Language Understanding tasks in recent years. Due to technical challenges with scaling weak supervision to work on long-form documents, spanning up to hundreds of pages, applications in the document understanding space have been limited. At Lexion, we built a weak supervision-based system tailored for long-form (10-200 pages long) PDF documents. We use this platform for building dozens of language understanding models and have applied it successfully to various domains, from commercial agreements to corporate formation documents. In this paper, we demonstrate the effectiveness of supervised learning with weak supervision in a situation with limited time, workforce, and training data. We built 8 high quality machine learning models in the span of one week, with the help of a small team of just 3 annotators working with a dataset of under 300 documents. We share some details about our overall architecture, how we utilize weak supervision, and what results we are able to achieve. We also include the dataset for researchers who would like to experiment with alternate approaches or refine ours. Furthermore, we shed some light on the additional complexities that arise when working with poorly scanned long-form documents in PDF format, and some of the techniques that help us achieve state-of-the-art performance on such data.
The Law of Large Documents: Understanding the Structure of Legal Contracts Using Visual Cues
Jul 16, 2021
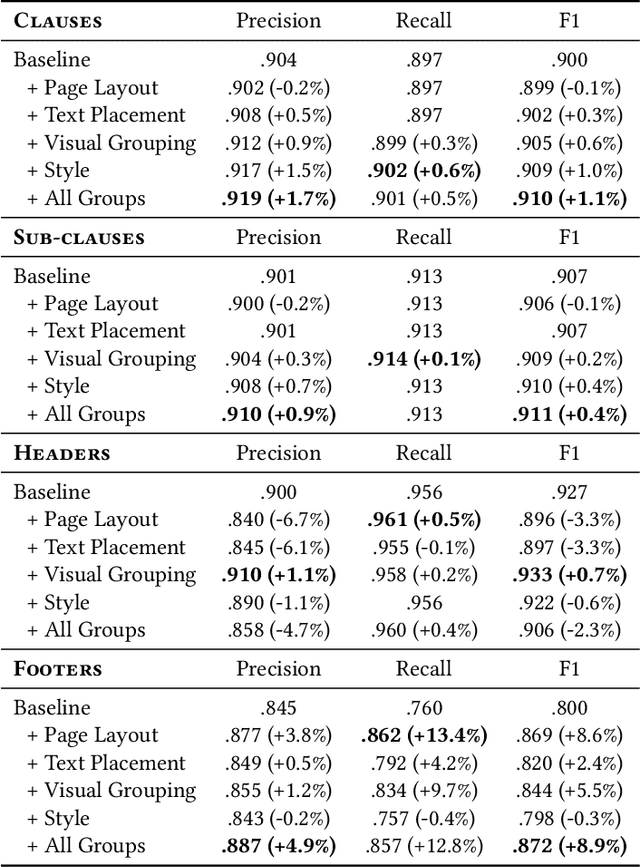
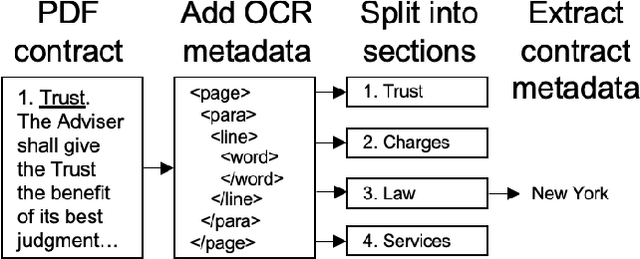
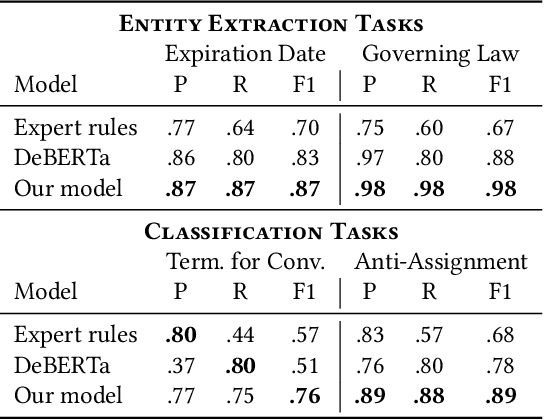
Large, pre-trained transformer models like BERT have achieved state-of-the-art results on document understanding tasks, but most implementations can only consider 512 tokens at a time. For many real-world applications, documents can be much longer, and the segmentation strategies typically used on longer documents miss out on document structure and contextual information, hurting their results on downstream tasks. In our work on legal agreements, we find that visual cues such as layout, style, and placement of text in a document are strong features that are crucial to achieving an acceptable level of accuracy on long documents. We measure the impact of incorporating such visual cues, obtained via computer vision methods, on the accuracy of document understanding tasks including document segmentation, entity extraction, and attribute classification. Our method of segmenting documents based on structural metadata out-performs existing methods on four long-document understanding tasks as measured on the Contract Understanding Atticus Dataset.
Shallow Syntax in Deep Water
Aug 29, 2019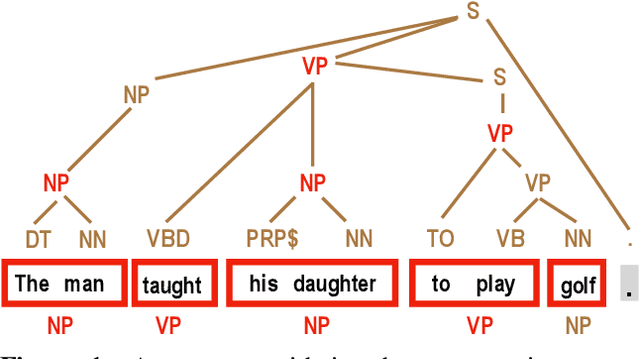
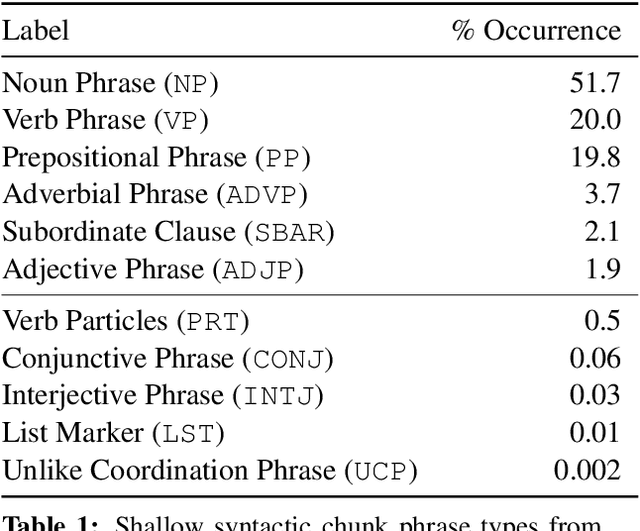
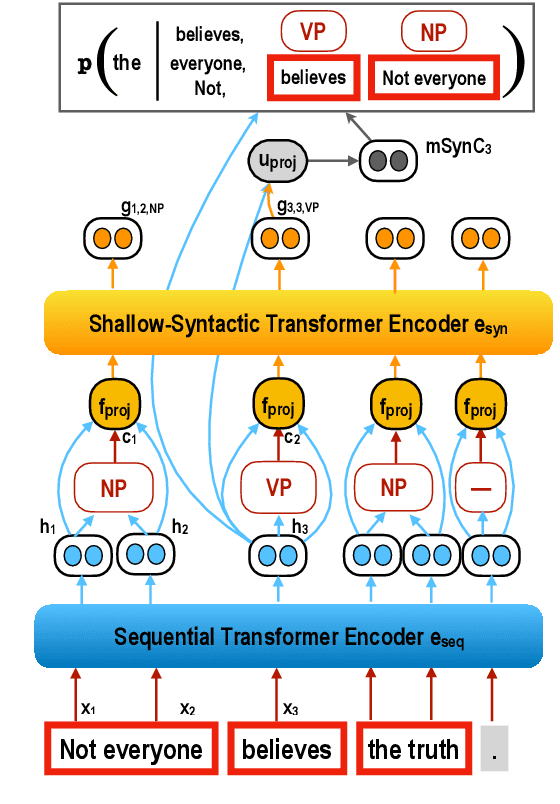
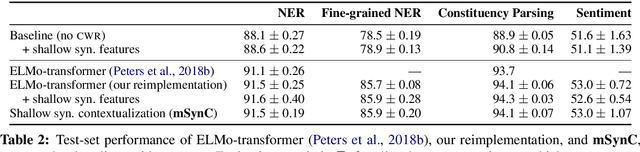
Shallow syntax provides an approximation of phrase-syntactic structure of sentences; it can be produced with high accuracy, and is computationally cheap to obtain. We investigate the role of shallow syntax-aware representations for NLP tasks using two techniques. First, we enhance the ELMo architecture to allow pretraining on predicted shallow syntactic parses, instead of just raw text, so that contextual embeddings make use of shallow syntactic context. Our second method involves shallow syntactic features obtained automatically on downstream task data. Neither approach leads to a significant gain on any of the four downstream tasks we considered relative to ELMo-only baselines. Further analysis using black-box probes confirms that our shallow-syntax-aware contextual embeddings do not transfer to linguistic tasks any more easily than ELMo's embeddings. We take these findings as evidence that ELMo-style pretraining discovers representations which make additional awareness of shallow syntax redundant.
ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning
Oct 31, 2018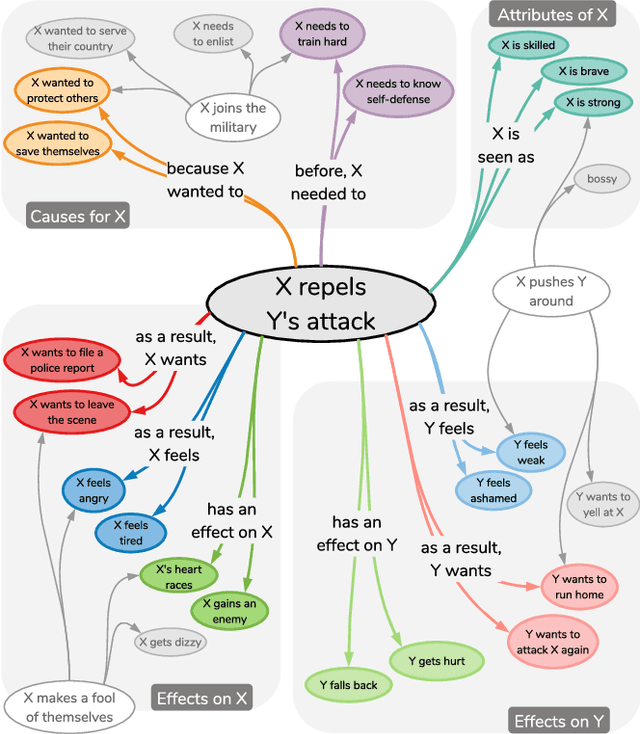
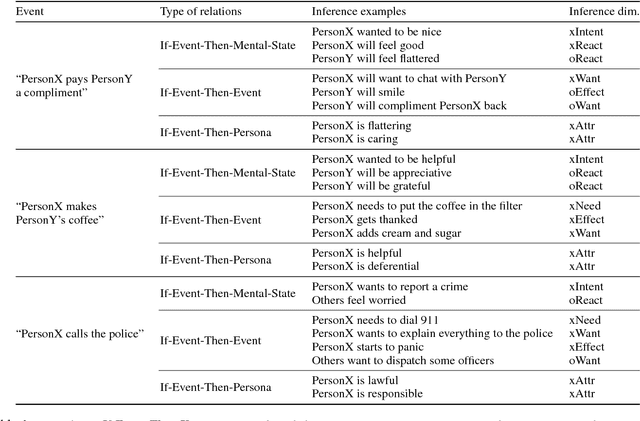

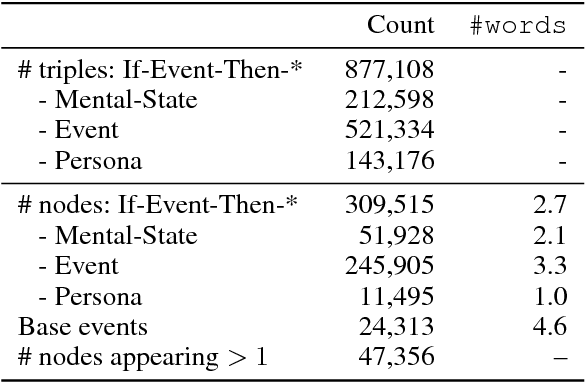
We present ATOMIC, an atlas of everyday commonsense reasoning, organized through 300k textual descriptions. Compared to existing resources that center around taxonomic knowledge, ATOMIC focuses on inferential knowledge organized as typed if-then relations with variables (e.g., "if X pays Y a compliment, then Y will likely return the compliment"). We propose nine if-then relation types to distinguish causes v.s. effects, agents v.s. themes, voluntary v.s. involuntary events, and actions v.s. mental states. By generatively training on the rich inferential knowledge described in ATOMIC, we show that neural models can acquire simple commonsense capabilities and reason about previously unseen events. Experimental results demonstrate that multitask models that incorporate the hierarchical structure of if-then relation types lead to more accurate inference compared to models trained in isolation, as measured by both automatic and human evaluation.