 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Syntax in Deep Water
Paper and Code
Aug 29, 2019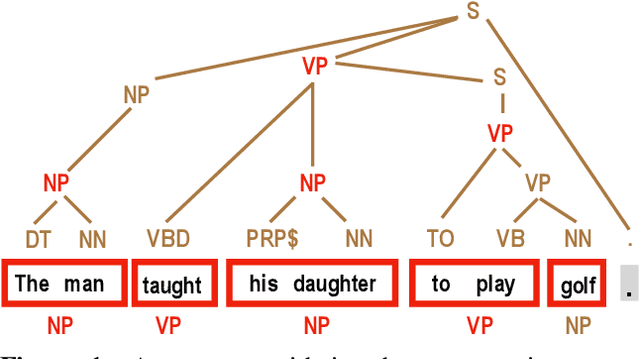
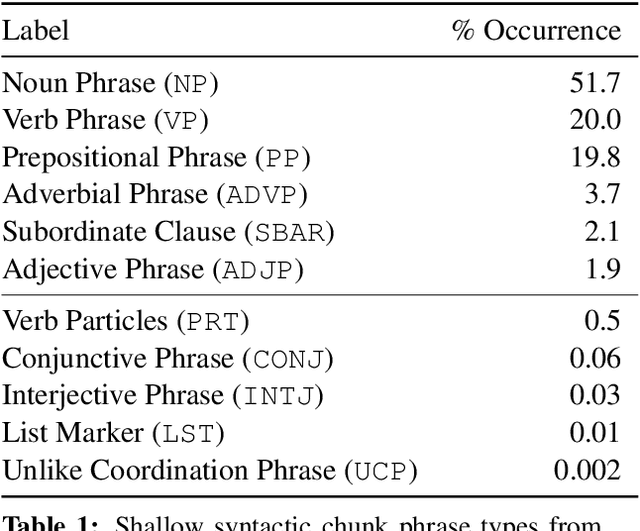
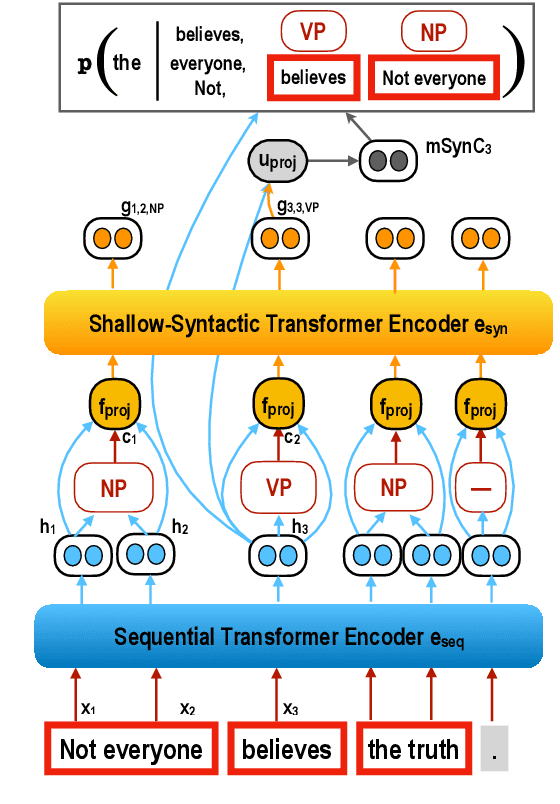
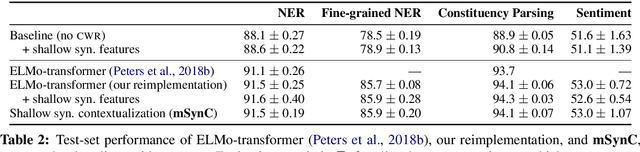
Shallow syntax provides an approximation of phrase-syntactic structure of sentences; it can be produced with high accuracy, and is computationally cheap to obtain. We investigate the role of shallow syntax-aware representations for NLP tasks using two techniques. First, we enhance the ELMo architecture to allow pretraining on predicted shallow syntactic parses, instead of just raw text, so that contextual embeddings make use of shallow syntactic context. Our second method involves shallow syntactic features obtained automatically on downstream task data. Neither approach leads to a significant gain on any of the four downstream tasks we considered relative to ELMo-only baselines. Further analysis using black-box probes confirms that our shallow-syntax-aware contextual embeddings do not transfer to linguistic tasks any more easily than ELMo's embeddings. We take these findings as evidence that ELMo-style pretraining discovers representations which make additional awareness of shallow syntax redundant.