 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Theory-of-Mind? On the Limits of Social Intelligence in Large LMs
Oct 24, 2022Social intelligence and Theory of Mind (ToM), i.e., the ability to reason about the different mental states, intents, and reactions of all people involved, allow humans to effectively navigate and understand everyday social interactions. As NLP systems are used in increasingly complex social situations, their ability to grasp social dynamics becomes crucial. In this work, we examine the open question of social intelligence and Theory of Mind in modern NLP systems from an empirical and theory-based perspective. We show that one of today's largest language models (GPT-3; Brown et al., 2020) lacks this kind of social intelligence out-of-the box, using two tasks: SocialIQa (Sap et al., 2019), which measures models' ability to understand intents and reactions of participants of social interactions, and ToMi (Le et al., 2019), which measures whether models can infer mental states and realities of participants of situations. Our results show that models struggle substantially at these Theory of Mind tasks, with well-below-human accuracies of 55% and 60% on SocialIQa and ToMi, respectively. To conclude, we draw on theories from pragmatics to contextualize this shortcoming of large language models, by examining the limitations stemming from their data, neural architecture, and training paradigms. Challenging the prevalent narrative that only scale is needed, we posit that person-centric NLP approaches might be more effective towards neural Theory of Mind.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
SocialIQA: Commonsense Reasoning about Social Interactions
Apr 22, 2019



We introduce SocialIQa, the first large-scale benchmark for commonsense reasoning about social situations. This resource contains 45,000 multiple choice questions for probing *emotional* and *social* intelligence in a variety of everyday situations (e.g., Q: ``Skylar went to Jan's birthday party and gave her a gift. What does Skylar need to do before this?'' A: ``Go shopping''). Through crowdsourcing, we collect commonsense questions along with correct and incorrect answers about social interactions, using a new framework that mitigates stylistic artifacts in incorrect answers by asking workers to provide the right answer to the wrong question. While humans can easily solve these questions (90%), our benchmark is more challenging for existing question-answering (QA) models, such as those based on pretrained language models (77%). Notably, we further establish SocialIQa as a resource for transfer learning of commonsense knowledge, achieving state-of-the-art performance on several commonsense reasoning tasks (Winograd Schemas, COPA).
ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning
Oct 31, 2018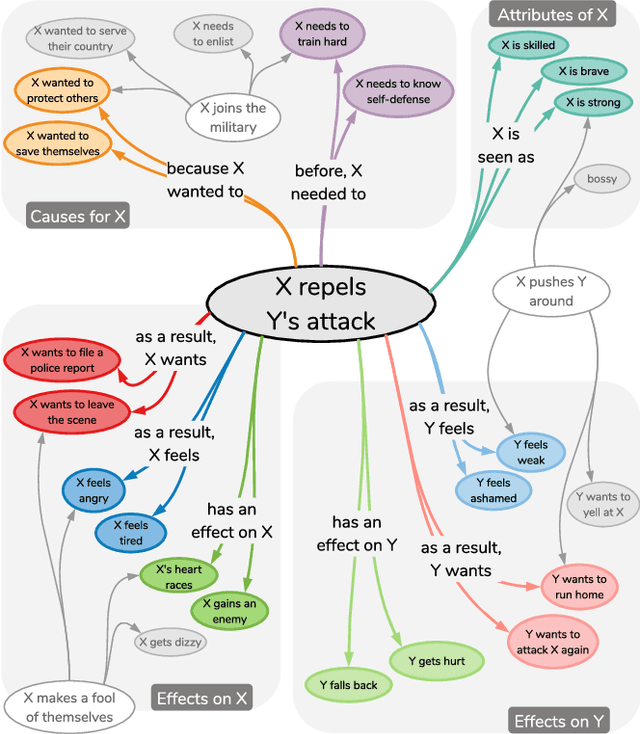
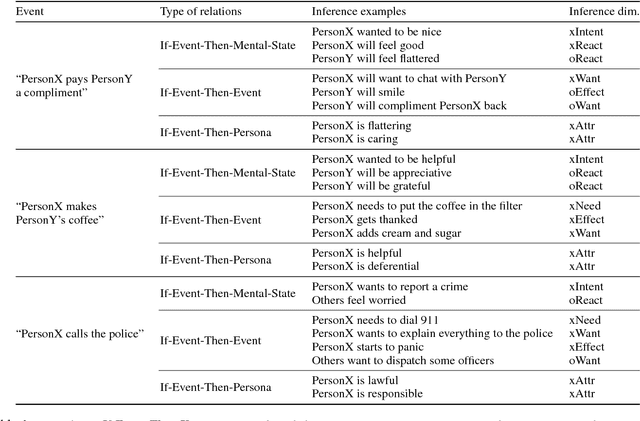

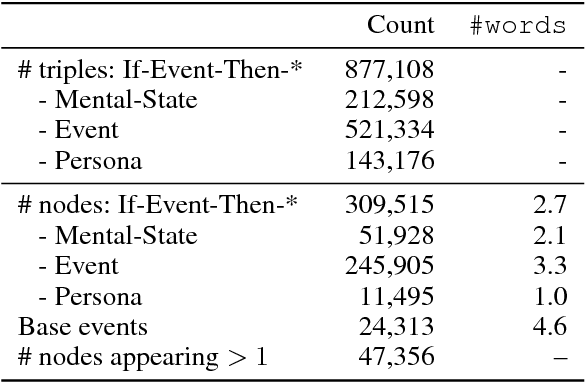
We present ATOMIC, an atlas of everyday commonsense reasoning, organized through 300k textual descriptions. Compared to existing resources that center around taxonomic knowledge, ATOMIC focuses on inferential knowledge organized as typed if-then relations with variables (e.g., "if X pays Y a compliment, then Y will likely return the compliment"). We propose nine if-then relation types to distinguish causes v.s. effects, agents v.s. themes, voluntary v.s. involuntary events, and actions v.s. mental states. By generatively training on the rich inferential knowledge described in ATOMIC, we show that neural models can acquire simple commonsense capabilities and reason about previously unseen events. Experimental results demonstrate that multitask models that incorporate the hierarchical structure of if-then relation types lead to more accurate inference compared to models trained in isolation, as measured by both automatic and human evaluation.