 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeperDive: The Unreasonable Effectiveness of Weak Supervision in Document Understanding A Case Study in Collaboration with UiPath Inc
Aug 17, 2022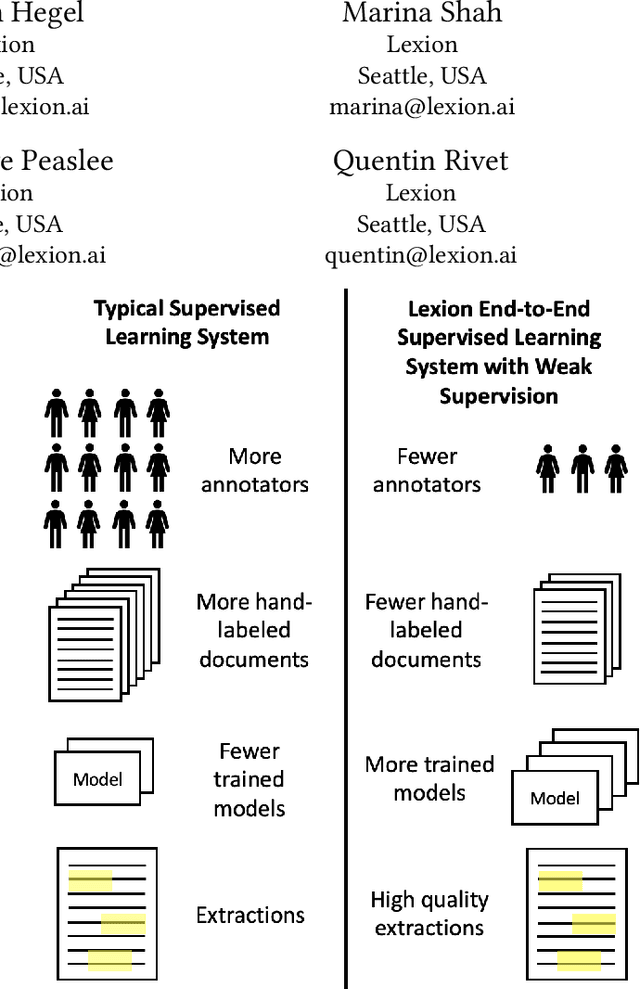


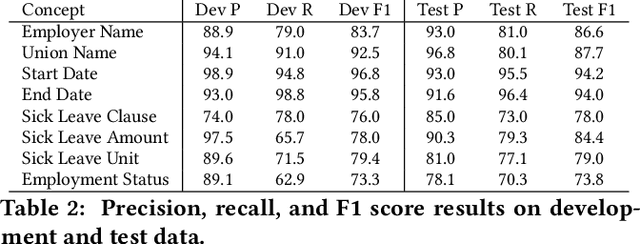
Weak supervision has been applied to various Natural Language Understanding tasks in recent years. Due to technical challenges with scaling weak supervision to work on long-form documents, spanning up to hundreds of pages, applications in the document understanding space have been limited. At Lexion, we built a weak supervision-based system tailored for long-form (10-200 pages long) PDF documents. We use this platform for building dozens of language understanding models and have applied it successfully to various domains, from commercial agreements to corporate formation documents. In this paper, we demonstrate the effectiveness of supervised learning with weak supervision in a situation with limited time, workforce, and training data. We built 8 high quality machine learning models in the span of one week, with the help of a small team of just 3 annotators working with a dataset of under 300 documents. We share some details about our overall architecture, how we utilize weak supervision, and what results we are able to achieve. We also include the dataset for researchers who would like to experiment with alternate approaches or refine ours. Furthermore, we shed some light on the additional complexities that arise when working with poorly scanned long-form documents in PDF format, and some of the techniques that help us achieve state-of-the-art performance on such data.
The Law of Large Documents: Understanding the Structure of Legal Contracts Using Visual Cues
Jul 16, 2021
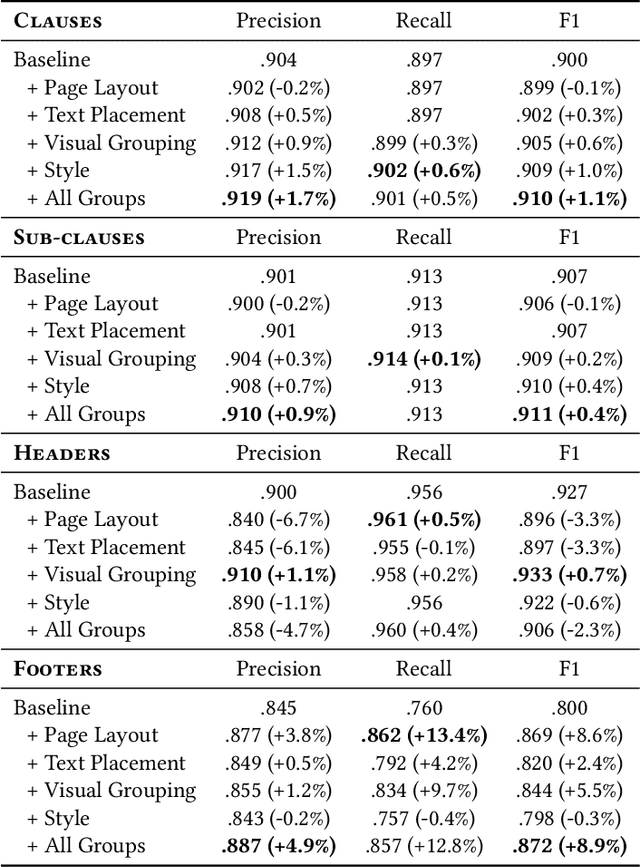
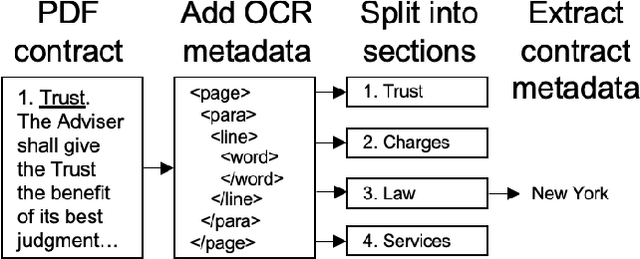
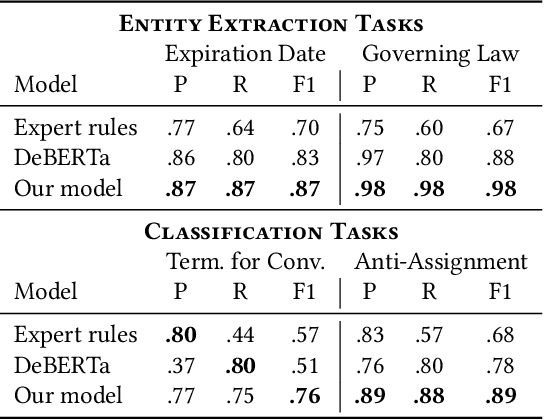
Large, pre-trained transformer models like BERT have achieved state-of-the-art results on document understanding tasks, but most implementations can only consider 512 tokens at a time. For many real-world applications, documents can be much longer, and the segmentation strategies typically used on longer documents miss out on document structure and contextual information, hurting their results on downstream tasks. In our work on legal agreements, we find that visual cues such as layout, style, and placement of text in a document are strong features that are crucial to achieving an acceptable level of accuracy on long documents. We measure the impact of incorporating such visual cues, obtained via computer vision methods, on the accuracy of document understanding tasks including document segmentation, entity extraction, and attribute classification. Our method of segmenting documents based on structural metadata out-performs existing methods on four long-document understanding tasks as measured on the Contract Understanding Atticus Dataset.
Substance over Style: Document-Level Targeted Content Transfer
Oct 16, 2020
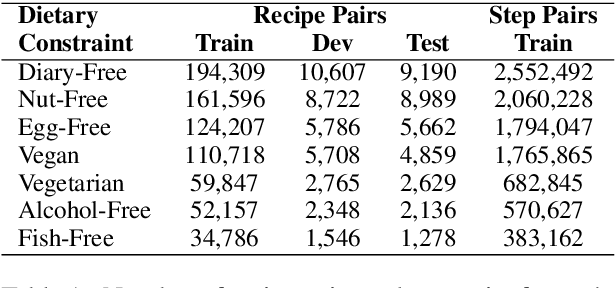


Existing language models excel at writing from scratch, but many real-world scenarios require rewriting an existing document to fit a set of constraints. Although sentence-level rewriting has been fairly well-studied, little work has addressed the challenge of rewriting an entire document coherently. In this work, we introduce the task of document-level targeted content transfer and address it in the recipe domain, with a recipe as the document and a dietary restriction (such as vegan or dairy-free) as the targeted constraint. We propose a novel model for this task based on the generative pre-trained language model (GPT-2) and train on a large number of roughly-aligned recipe pairs (https://github.com/microsoft/document-level-targeted-content-transfer). Both automatic and human evaluations show that our model out-performs existing methods by generating coherent and diverse rewrites that obey the constraint while remaining close to the original document. Finally, we analyze our model's rewrites to assess progress toward the goal of making language generation more attuned to constraints that are substantive rather than stylistic.