 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom LLM to NMT: Advancing Low-Resource Machine Translation with Claude
Apr 22, 2024



We show that Claude 3 Opus, a large language model (LLM) released by Anthropic in March 2024, exhibits stronger machine translation competence than other LLMs. Though we find evidence of data contamination with Claude on FLORES-200, we curate new benchmarks that corroborate the effectiveness of Claude for low-resource machine translation into English. We find that Claude has remarkable \textit{resource efficiency} -- the degree to which the quality of the translation model depends on a language pair's resource level. Finally, we show that advancements in LLM translation can be compressed into traditional neural machine translation (NMT) models. Using Claude to generate synthetic data, we demonstrate that knowledge distillation advances the state-of-the-art in Yoruba-English translation, meeting or surpassing strong baselines like NLLB-54B and Google Translate.
Reed at SemEval-2020 Task 9: Fine-Tuning and Bag-of-Words Approaches to Code-Mixed Sentiment Analysis
Aug 04, 2020



We explore the task of sentiment analysis on Hinglish (code-mixed Hindi-English) tweets as participants of Task 9 of the SemEval-2020 competition, known as the SentiMix task. We had two main approaches: 1) applying transfer learning by fine-tuning pre-trained BERT models and 2) training feedforward neural networks on bag-of-words representations. During the evaluation phase of the competition, we obtained an F-score of 71.3% with our best model, which placed $4^{th}$ out of 62 entries in the official system rankings.
Extending a Parser to Distant Domains Using a Few Dozen Partially Annotated Examples
May 16, 2018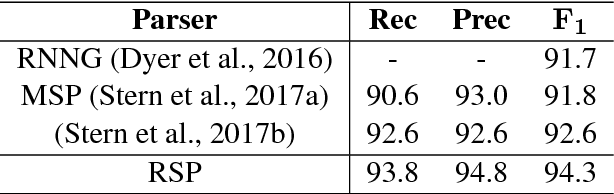

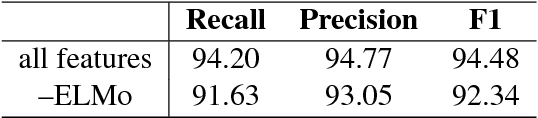
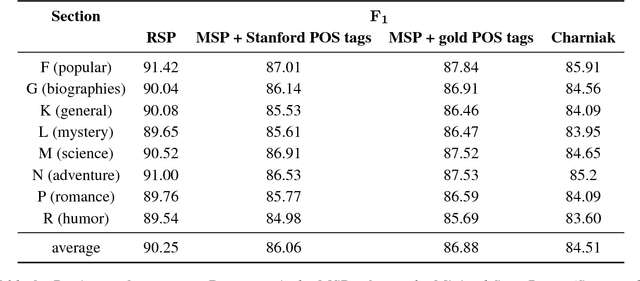
We revisit domain adaptation for parsers in the neural era. First we show that recent advances in word representations greatly diminish the need for domain adaptation when the target domain is syntactically similar to the source domain. As evidence, we train a parser on the Wall Street Jour- nal alone that achieves over 90% F1 on the Brown corpus. For more syntactically dis- tant domains, we provide a simple way to adapt a parser using only dozens of partial annotations. For instance, we increase the percentage of error-free geometry-domain parses in a held-out set from 45% to 73% using approximately five dozen training examples. In the process, we demon- strate a new state-of-the-art single model result on the Wall Street Journal test set of 94.3%. This is an absolute increase of 1.7% over the previous state-of-the-art of 92.6%.
LAYERWIDTH: Analysis of a New Metric for Directed Acyclic Graphs
Oct 19, 2012

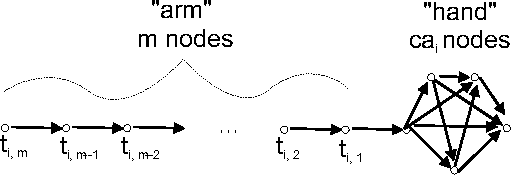
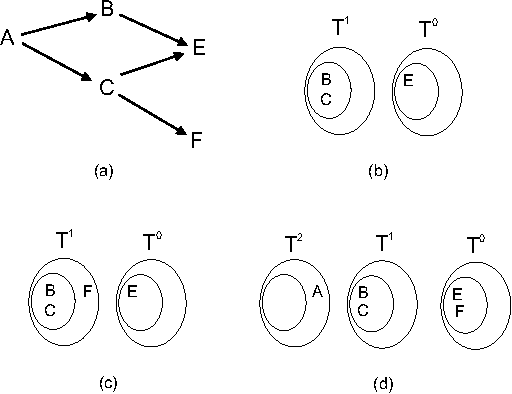
We analyze a new property of directed acyclic graphs (DAGs), called layerwidth, arising from a class of DAGs proposed by Eiter and Lukasiewicz. This class of DAGs permits certain problems of structural model-based causality and explanation to be tractably solved. In this paper, we first address an open question raised by Eiter and Lukasiewicz - the computational complexity of deciding whether a given graph has a bounded layerwidth. After proving that this problem is NP-complete, we proceed by proving numerous important properties of layerwidth that are helpful in efficiently computing the optimal layerwidth. Finally, we compare this new DAG property to two other important DAG properties: treewidth and bandwidth.