 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIRAJ: Diverse and Efficient Red-Teaming for LLM Agents via Distilled Structured Reasoning
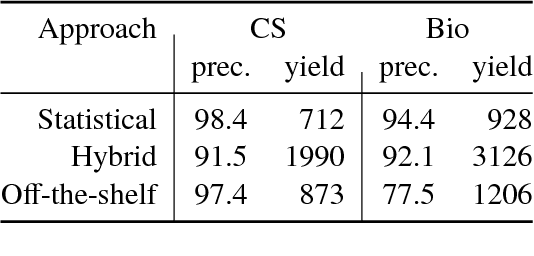
Oct 30, 2025The ability of LLM agents to plan and invoke tools exposes them to new safety risks, making a comprehensive red-teaming system crucial for discovering vulnerabilities and ensuring their safe deployment. We present SIRAJ: a generic red-teaming framework for arbitrary black-box LLM agents. We employ a dynamic two-step process that starts with an agent definition and generates diverse seed test cases that cover various risk outcomes, tool-use trajectories, and risk sources. Then, it iteratively constructs and refines model-based adversarial attacks based on the execution trajectories of former attempts. To optimize the red-teaming cost, we present a model distillation approach that leverages structured forms of a teacher model's reasoning to train smaller models that are equally effective. Across diverse evaluation agent settings, our seed test case generation approach yields 2 -- 2.5x boost to the coverage of risk outcomes and tool-calling trajectories. Our distilled 8B red-teamer model improves attack success rate by 100%, surpassing the 671B Deepseek-R1 model. Our ablations and analyses validate the effectiveness of the iterative framework, structured reasoning, and the generalization of our red-teamer models.
Jailbreak Distillation: Renewable Safety Benchmarking
May 28, 2025Large language models (LLMs) are rapidly deployed in critical applications, raising urgent needs for robust safety benchmarking. We propose Jailbreak Distillation (JBDistill), a novel benchmark construction framework that "distills" jailbreak attacks into high-quality and easily-updatable safety benchmarks. JBDistill utilizes a small set of development models and existing jailbreak attack algorithms to create a candidate prompt pool, then employs prompt selection algorithms to identify an effective subset of prompts as safety benchmarks. JBDistill addresses challenges in existing safety evaluation: the use of consistent evaluation prompts across models ensures fair comparisons and reproducibility. It requires minimal human effort to rerun the JBDistill pipeline and produce updated benchmarks, alleviating concerns on saturation and contamination. Extensive experiments demonstrate our benchmarks generalize robustly to 13 diverse evaluation models held out from benchmark construction, including proprietary, specialized, and newer-generation LLMs, significantly outperforming existing safety benchmarks in effectiveness while maintaining high separability and diversity. Our framework thus provides an effective, sustainable, and adaptable solution for streamlining safety evaluation.
Controllable Safety Alignment: Inference-Time Adaptation to Diverse Safety Requirements
Oct 11, 2024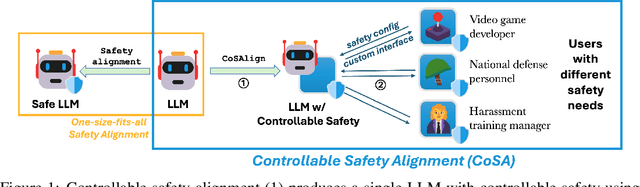
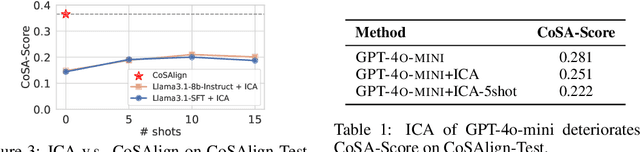
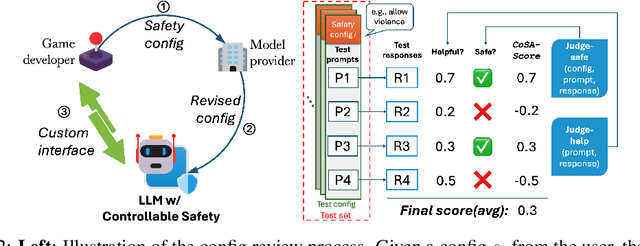
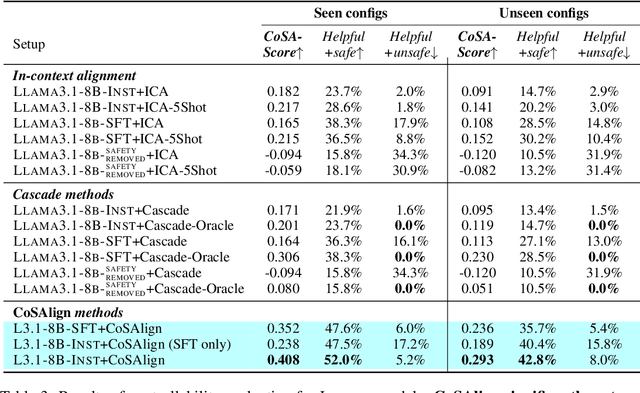
The current paradigm for safety alignment of large language models (LLMs) follows a one-size-fits-all approach: the model refuses to interact with any content deemed unsafe by the model provider. This approach lacks flexibility in the face of varying social norms across cultures and regions. In addition, users may have diverse safety needs, making a model with static safety standards too restrictive to be useful, as well as too costly to be re-aligned. We propose Controllable Safety Alignment (CoSA), a framework designed to adapt models to diverse safety requirements without re-training. Instead of aligning a fixed model, we align models to follow safety configs -- free-form natural language descriptions of the desired safety behaviors -- that are provided as part of the system prompt. To adjust model safety behavior, authorized users only need to modify such safety configs at inference time. To enable that, we propose CoSAlign, a data-centric method for aligning LLMs to easily adapt to diverse safety configs. Furthermore, we devise a novel controllability evaluation protocol that considers both helpfulness and configured safety, summarizing them into CoSA-Score, and construct CoSApien, a human-authored benchmark that consists of real-world LLM use cases with diverse safety requirements and corresponding evaluation prompts. We show that CoSAlign leads to substantial gains of controllability over strong baselines including in-context alignment. Our framework encourages better representation and adaptation to pluralistic human values in LLMs, and thereby increasing their practicality.
NL-EDIT: Correcting semantic parse errors through natural language interaction
Mar 26, 2021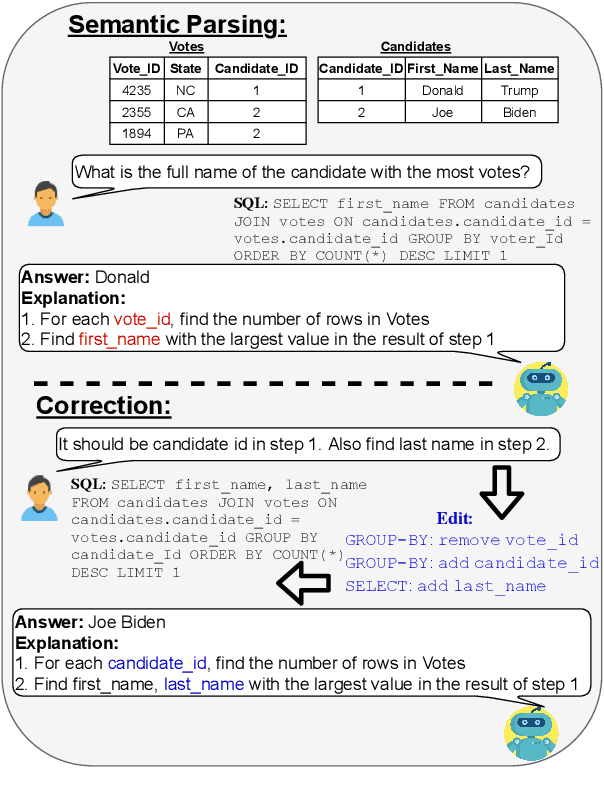


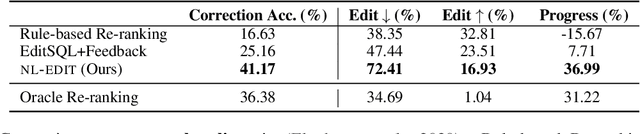
We study semantic parsing in an interactive setting in which users correct errors with natural language feedback. We present NL-EDIT, a model for interpreting natural language feedback in the interaction context to generate a sequence of edits that can be applied to the initial parse to correct its errors. We show that NL-EDIT can boost the accuracy of existing text-to-SQL parsers by up to 20% with only one turn of correction. We analyze the limitations of the model and discuss directions for improvement and evaluation. The code and datasets used in this paper are publicly available at http://aka.ms/NLEdit.
Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback
Jun 01, 2020
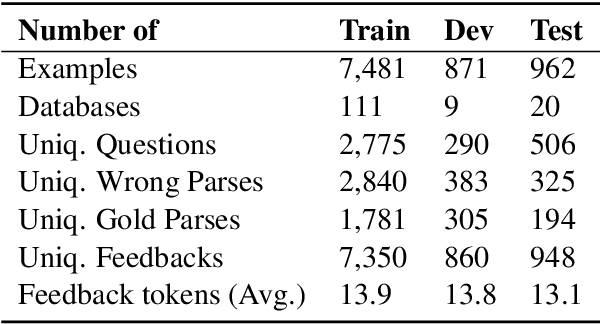


We study the task of semantic parse correction with natural language feedback. Given a natural language utterance, most semantic parsing systems pose the problem as one-shot translation where the utterance is mapped to a corresponding logical form. In this paper, we investigate a more interactive scenario where humans can further interact with the system by providing free-form natural language feedback to correct the system when it generates an inaccurate interpretation of an initial utterance. We focus on natural language to SQL systems and construct, SPLASH, a dataset of utterances, incorrect SQL interpretations and the corresponding natural language feedback. We compare various reference models for the correction task and show that incorporating such a rich form of feedback can significantly improve the overall semantic parsing accuracy while retaining the flexibility of natural language interaction. While we estimated human correction accuracy is 81.5%, our best model achieves only 25.1%, which leaves a large gap for improvement in future research. SPLASH is publicly available at https://aka.ms/Splash_dataset.
Generating Natural Language Adversarial Examples
Sep 24, 2018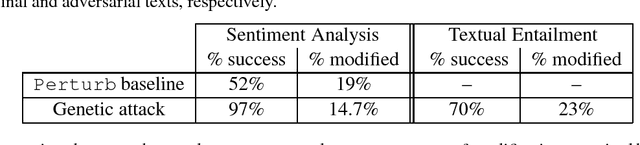
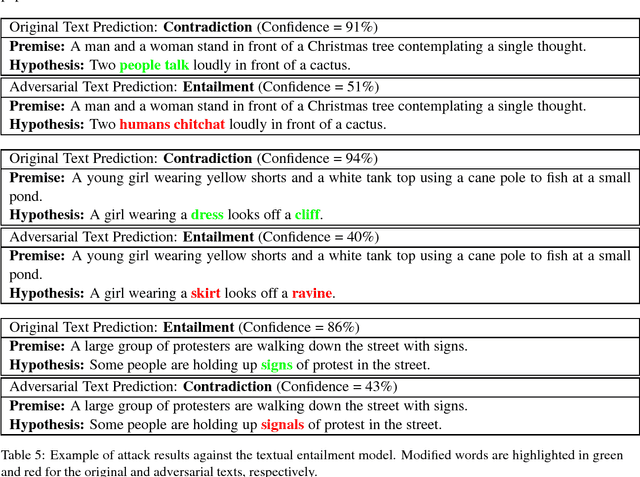
Deep neural networks (DNNs) are vulnerable to adversarial examples, perturbations to correctly classified examples which can cause the model to misclassify. In the image domain, these perturbations are often virtually indistinguishable to human perception, causing humans and state-of-the-art models to disagree. However, in the natural language domain, small perturbations are clearly perceptible, and the replacement of a single word can drastically alter the semantics of the document. Given these challenges, we use a black-box population-based optimization algorithm to generate semantically and syntactically similar adversarial examples that fool well-trained sentiment analysis and textual entailment models with success rates of 97% and 70%, respectively. We additionally demonstrate that 92.3% of the successful sentiment analysis adversarial examples are classified to their original label by 20 human annotators, and that the examples are perceptibly quite similar. Finally, we discuss an attempt to use adversarial training as a defense, but fail to yield improvement, demonstrating the strength and diversity of our adversarial examples. We hope our findings encourage researchers to pursue improving the robustness of DNNs in the natural language domain.
Assessing Composition in Sentence Vector Representations
Sep 11, 2018

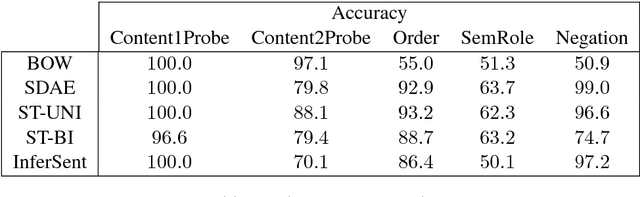
An important component of achieving language understanding is mastering the composition of sentence meaning, but an immediate challenge to solving this problem is the opacity of sentence vector representations produced by current neural sentence composition models. We present a method to address this challenge, developing tasks that directly target compositional meaning information in sentence vector representations with a high degree of precision and control. To enable the creation of these controlled tasks, we introduce a specialized sentence generation system that produces large, annotated sentence sets meeting specified syntactic, semantic and lexical constraints. We describe the details of the method and generation system, and then present results of experiments applying our method to probe for compositional information in embeddings from a number of existing sentence composition models. We find that the method is able to extract useful information about the differing capacities of these models, and we discuss the implications of our results with respect to these systems' capturing of sentence information. We make available for public use the datasets used for these experiments, as well as the generation system.
* COLING 2018
Construction of the Literature Graph in Semantic Scholar
May 06, 2018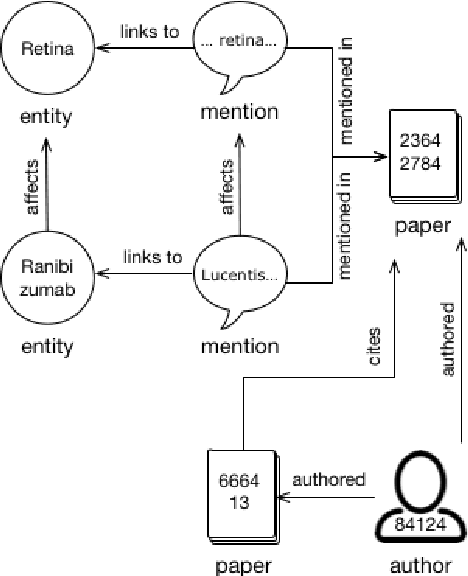
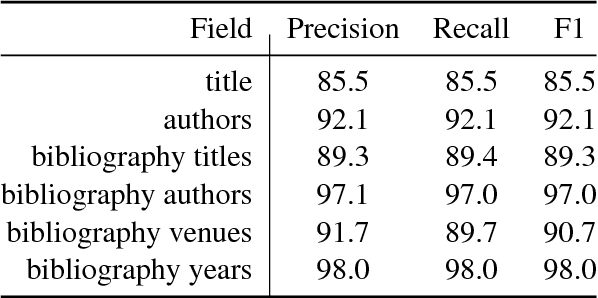

We describe a deployed scalable system for organizing published scientific literature into a heterogeneous graph to facilitate algorithmic manipulation and discovery. The resulting literature graph consists of more than 280M nodes, representing papers, authors, entities and various interactions between them (e.g., authorships, citations, entity mentions). We reduce literature graph construction into familiar NLP tasks (e.g., entity extraction and linking), point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task. The methods described in this paper are used to enable semantic features in www.semanticscholar.org
Embed and Conquer: Scalable Embeddings for Kernel k-Means on MapReduce
Jan 29, 2014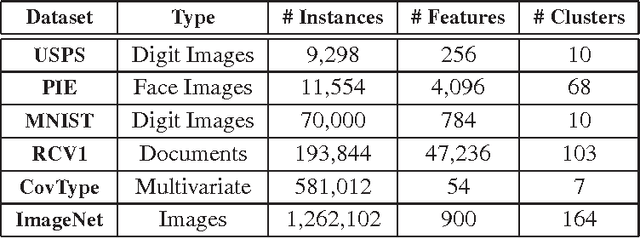
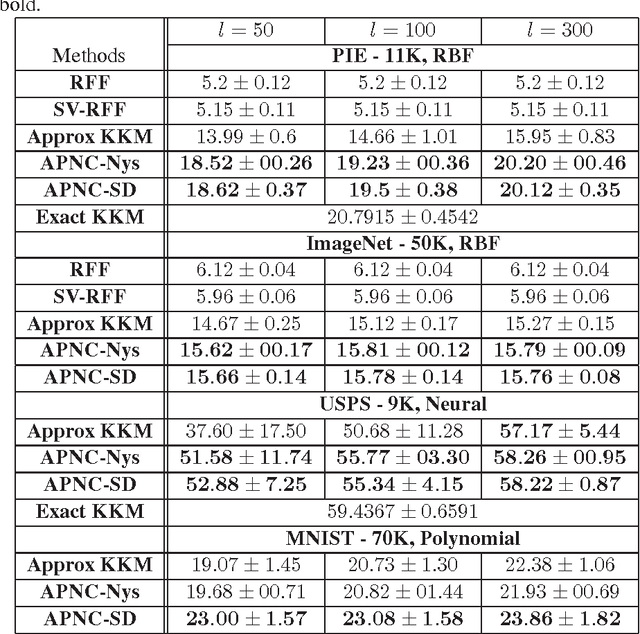
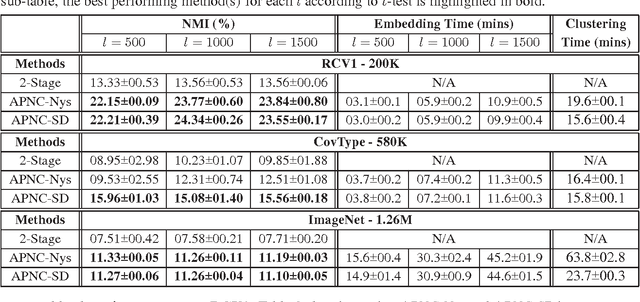
The kernel $k$-means is an effective method for data clustering which extends the commonly-used $k$-means algorithm to work on a similarity matrix over complex data structures. The kernel $k$-means algorithm is however computationally very complex as it requires the complete data matrix to be calculated and stored. Further, the kernelized nature of the kernel $k$-means algorithm hinders the parallelization of its computations on modern infrastructures for distributed computing. In this paper, we are defining a family of kernel-based low-dimensional embeddings that allows for scaling kernel $k$-means on MapReduce via an efficient and unified parallelization strategy. Afterwards, we propose two methods for low-dimensional embedding that adhere to our definition of the embedding family. Exploiting the proposed parallelization strategy, we present two scalable MapReduce algorithms for kernel $k$-means. We demonstrate the effectiveness and efficiency of the proposed algorithms through an empirical evaluation on benchmark data sets.
Greedy Column Subset Selection for Large-scale Data Sets
Dec 24, 2013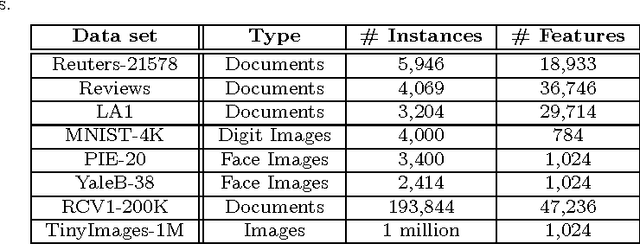
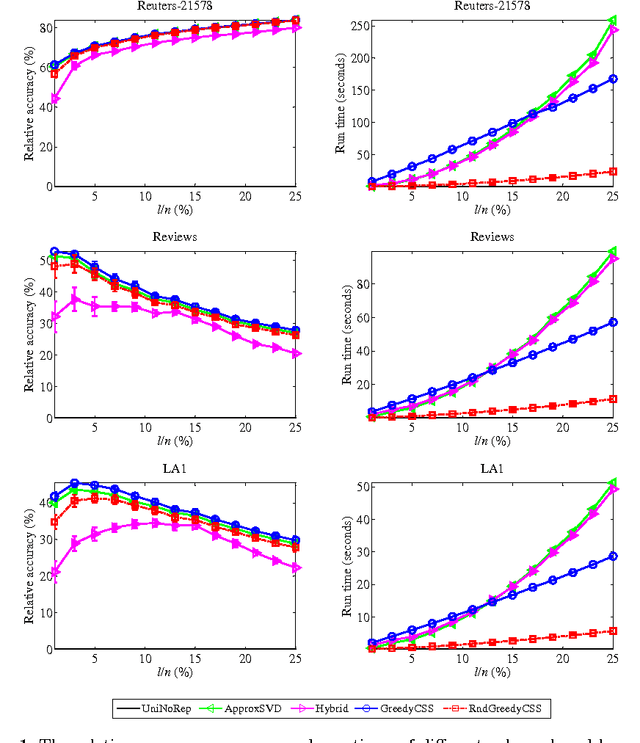
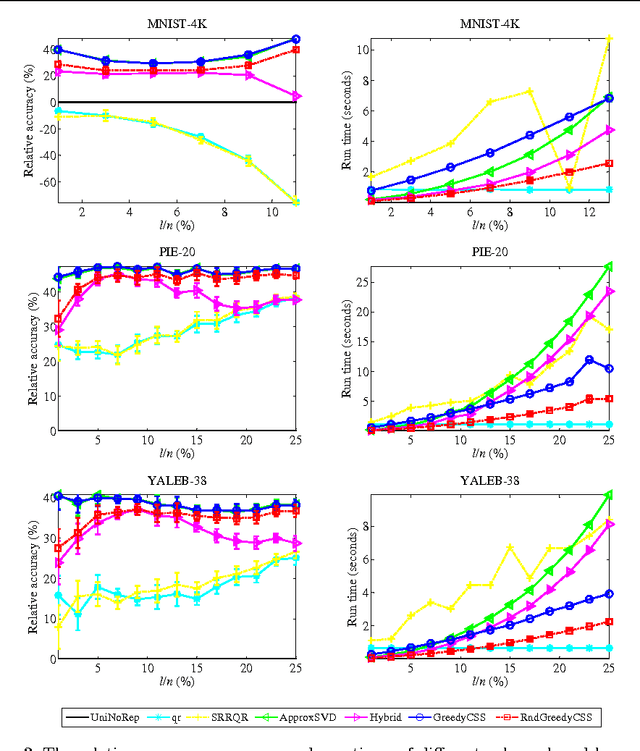
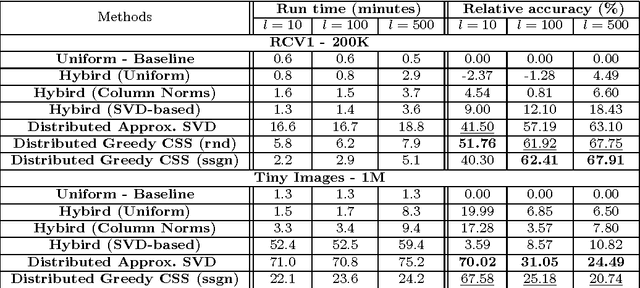
In today's information systems, the availability of massive amounts of data necessitates the development of fast and accurate algorithms to summarize these data and represent them in a succinct format. One crucial problem in big data analytics is the selection of representative instances from large and massively-distributed data, which is formally known as the Column Subset Selection (CSS) problem. The solution to this problem enables data analysts to understand the insights of the data and explore its hidden structure. The selected instances can also be used for data preprocessing tasks such as learning a low-dimensional embedding of the data points or computing a low-rank approximation of the corresponding matrix. This paper presents a fast and accurate greedy algorithm for large-scale column subset selection. The algorithm minimizes an objective function which measures the reconstruction error of the data matrix based on the subset of selected columns. The paper first presents a centralized greedy algorithm for column subset selection which depends on a novel recursive formula for calculating the reconstruction error of the data matrix. The paper then presents a MapReduce algorithm which selects a few representative columns from a matrix whose columns are massively distributed across several commodity machines. The algorithm first learns a concise representation of all columns using random projection, and it then solves a generalized column subset selection problem at each machine in which a subset of columns are selected from the sub-matrix on that machine such that the reconstruction error of the concise representation is minimized. The paper demonstrates the effectiveness and efficiency of the proposed algorithm through an empirical evaluation on benchmark data sets.