 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers
Jun 22, 2021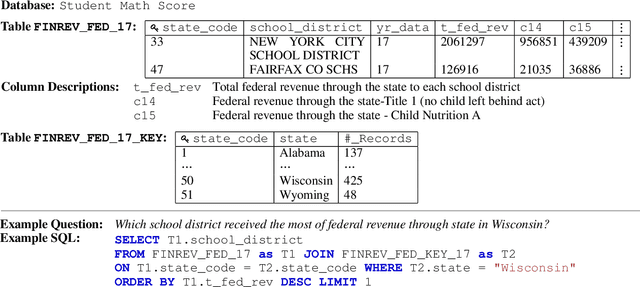
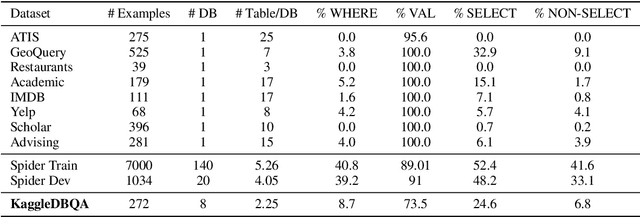
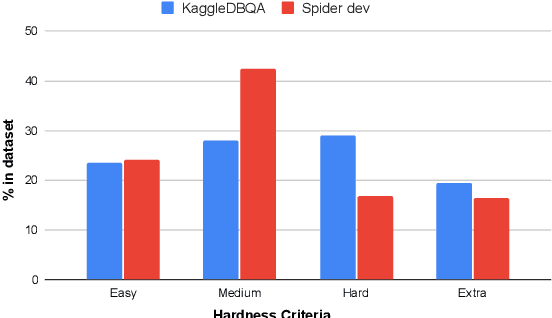

The goal of database question answering is to enable natural language querying of real-life relational databases in diverse application domains. Recently, large-scale datasets such as Spider and WikiSQL facilitated novel modeling techniques for text-to-SQL parsing, improving zero-shot generalization to unseen databases. In this work, we examine the challenges that still prevent these techniques from practical deployment. First, we present KaggleDBQA, a new cross-domain evaluation dataset of real Web databases, with domain-specific data types, original formatting, and unrestricted questions. Second, we re-examine the choice of evaluation tasks for text-to-SQL parsers as applied in real-life settings. Finally, we augment our in-domain evaluation task with database documentation, a naturally occurring source of implicit domain knowledge. We show that KaggleDBQA presents a challenge to state-of-the-art zero-shot parsers but a more realistic evaluation setting and creative use of associated database documentation boosts their accuracy by over 13.2%, doubling their performance.
NL-EDIT: Correcting semantic parse errors through natural language interaction
Mar 26, 2021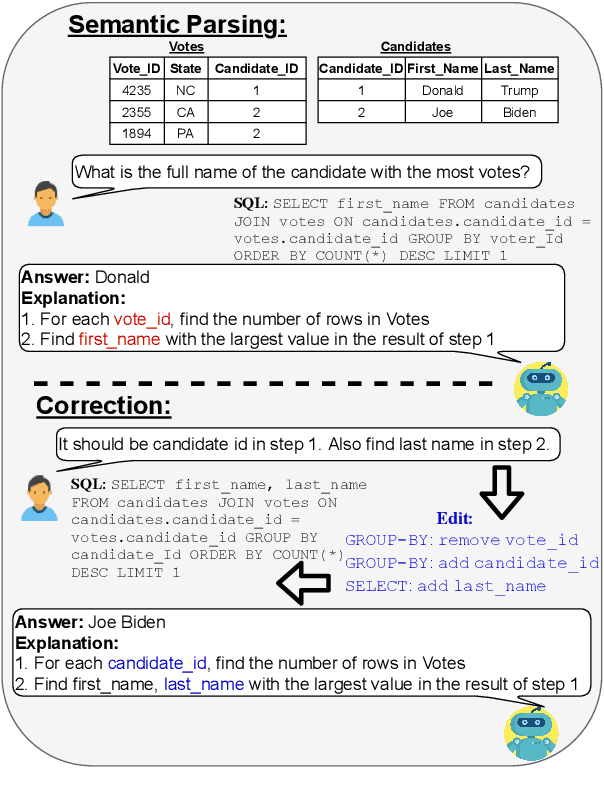


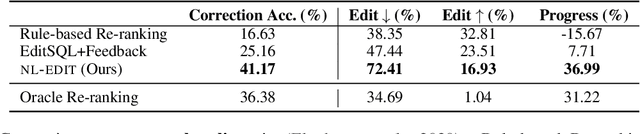
We study semantic parsing in an interactive setting in which users correct errors with natural language feedback. We present NL-EDIT, a model for interpreting natural language feedback in the interaction context to generate a sequence of edits that can be applied to the initial parse to correct its errors. We show that NL-EDIT can boost the accuracy of existing text-to-SQL parsers by up to 20% with only one turn of correction. We analyze the limitations of the model and discuss directions for improvement and evaluation. The code and datasets used in this paper are publicly available at http://aka.ms/NLEdit.
Structure-Grounded Pretraining for Text-to-SQL
Oct 24, 2020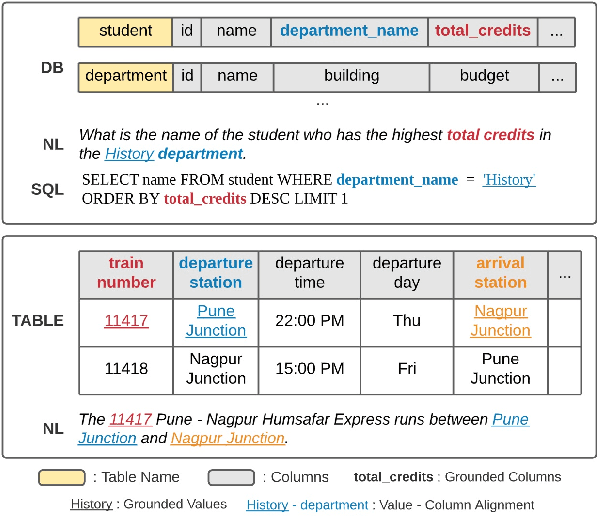
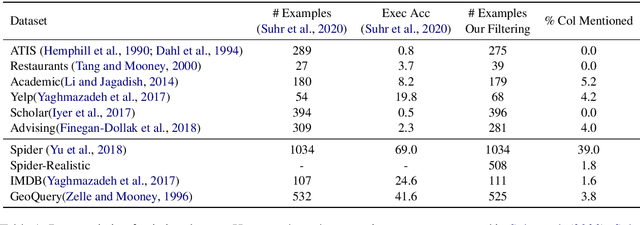
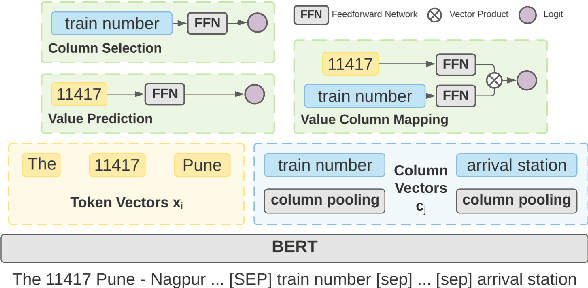

Learning to capture text-table alignment is essential for table related tasks like text-to-SQL. The model needs to correctly recognize natural language references to columns and values and to ground them in the given database schema. In this paper, we present a novel weakly supervised Structure-Grounded pretraining framework (StruG) for text-to-SQL that can effectively learn to capture text-table alignment based on a parallel text-table corpus. We identify a set of novel prediction tasks: column grounding, value grounding and column-value mapping, and train them using weak supervision without requiring complex SQL annotation. Additionally, to evaluate the model under a more realistic setting, we create a new evaluation set Spider-Realistic based on Spider with explicit mentions of column names removed, and adopt two existing single-database text-to-SQL datasets. StruG significantly outperforms BERT-LARGE on Spider and the realistic evaluation sets, while bringing consistent improvement on the large-scale WikiSQL benchmark.
RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
Nov 10, 2019
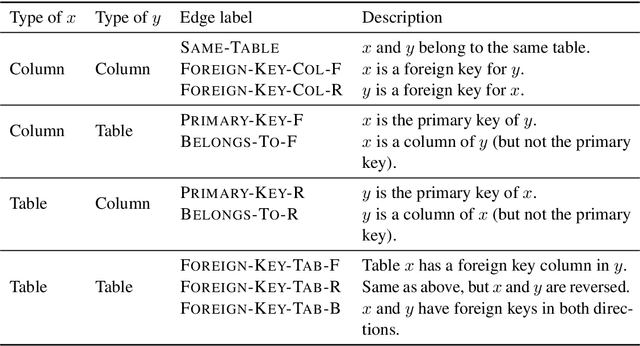
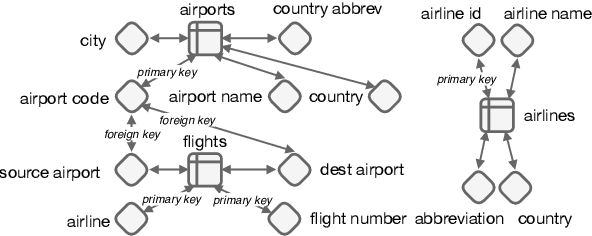
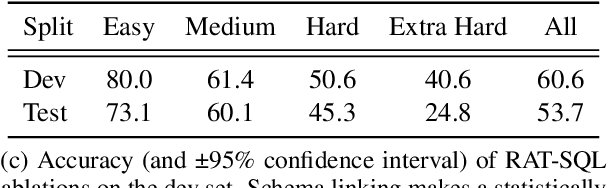
When translating natural language questions into SQL queries to answer questions from a database, contemporary semantic parsing models struggle to generalize to unseen database schemas. The generalization challenge lies in (a) encoding the database relations in an accessible way for the semantic parser, and (b) modeling alignment between database columns and their mentions in a given query. We present a unified framework, based on the relation-aware self-attention mechanism, to address schema encoding, schema linking, and feature representation within a text-to-SQL encoder. On the challenging Spider dataset this framework boosts the exact match accuracy to 53.7%, compared to 47.4% for the state-of-the-art model unaugmented with BERT embeddings. In addition, we observe qualitative improvements in the model's understanding of schema linking and alignment.
DyNet: The Dynamic Neural Network Toolkit
Jan 15, 2017
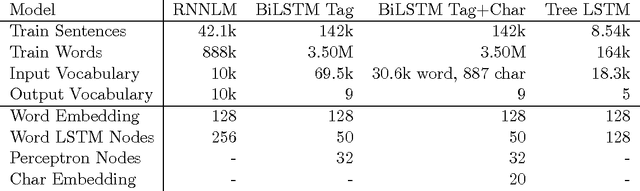


We describe DyNet, a toolkit for implementing neural network models based on dynamic declaration of network structure. In the static declaration strategy that is used in toolkits like Theano, CNTK, and TensorFlow, the user first defines a computation graph (a symbolic representation of the computation), and then examples are fed into an engine that executes this computation and computes its derivatives. In DyNet's dynamic declaration strategy, computation graph construction is mostly transparent, being implicitly constructed by executing procedural code that computes the network outputs, and the user is free to use different network structures for each input. Dynamic declaration thus facilitates the implementation of more complicated network architectures, and DyNet is specifically designed to allow users to implement their models in a way that is idiomatic in their preferred programming language (C++ or Python). One challenge with dynamic declaration is that because the symbolic computation graph is defined anew for every training example, its construction must have low overhead. To achieve this, DyNet has an optimized C++ backend and lightweight graph representation. Experiments show that DyNet's speeds are faster than or comparable with static declaration toolkits, and significantly faster than Chainer, another dynamic declaration toolkit. DyNet is released open-source under the Apache 2.0 license and available at http://github.com/clab/dynet.
Blending LSTMs into CNNs
Sep 14, 2016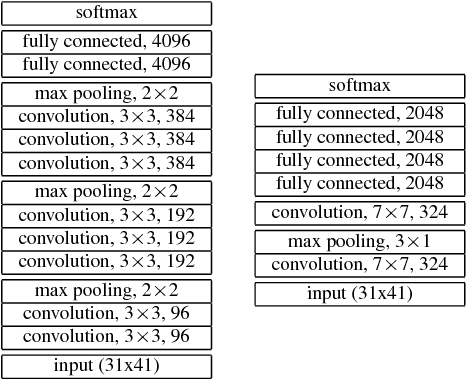
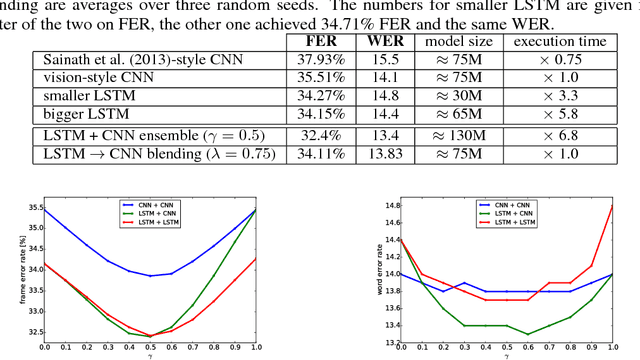

We consider whether deep convolutional networks (CNNs) can represent decision functions with similar accuracy as recurrent networks such as LSTMs. First, we show that a deep CNN with an architecture inspired by the models recently introduced in image recognition can yield better accuracy than previous convolutional and LSTM networks on the standard 309h Switchboard automatic speech recognition task. Then we show that even more accurate CNNs can be trained under the guidance of LSTMs using a variant of model compression, which we call model blending because the teacher and student models are similar in complexity but different in inductive bias. Blending further improves the accuracy of our CNN, yielding a computationally efficient model of accuracy higher than any of the other individual models. Examining the effect of "dark knowledge" in this model compression task, we find that less than 1% of the highest probability labels are needed for accurate model compression.