 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiGraphs: A Wikipedia Text - Knowledge Graph Paired Dataset
Jul 20, 2021

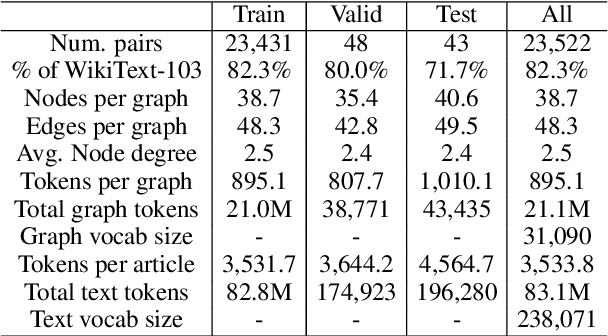

We present a new dataset of Wikipedia articles each paired with a knowledge graph, to facilitate the research in conditional text generation, graph generation and graph representation learning. Existing graph-text paired datasets typically contain small graphs and short text (1 or few sentences), thus limiting the capabilities of the models that can be learned on the data. Our new dataset WikiGraphs is collected by pairing each Wikipedia article from the established WikiText-103 benchmark (Merity et al., 2016) with a subgraph from the Freebase knowledge graph (Bollacker et al., 2008). This makes it easy to benchmark against other state-of-the-art text generative models that are capable of generating long paragraphs of coherent text. Both the graphs and the text data are of significantly larger scale compared to prior graph-text paired datasets. We present baseline graph neural network and transformer model results on our dataset for 3 tasks: graph -> text generation, graph -> text retrieval and text -> graph retrieval. We show that better conditioning on the graph provides gains in generation and retrieval quality but there is still large room for improvement.
Do Deep Convolutional Nets Really Need to be Deep and Convolutional?
Mar 04, 2017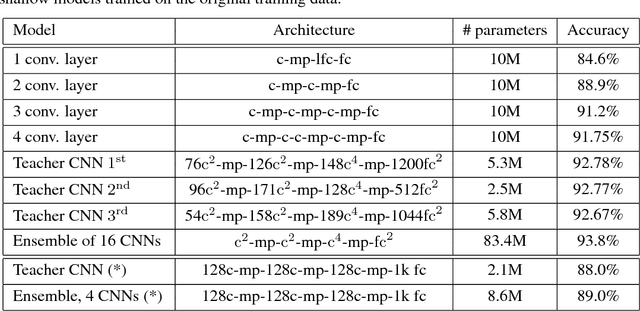
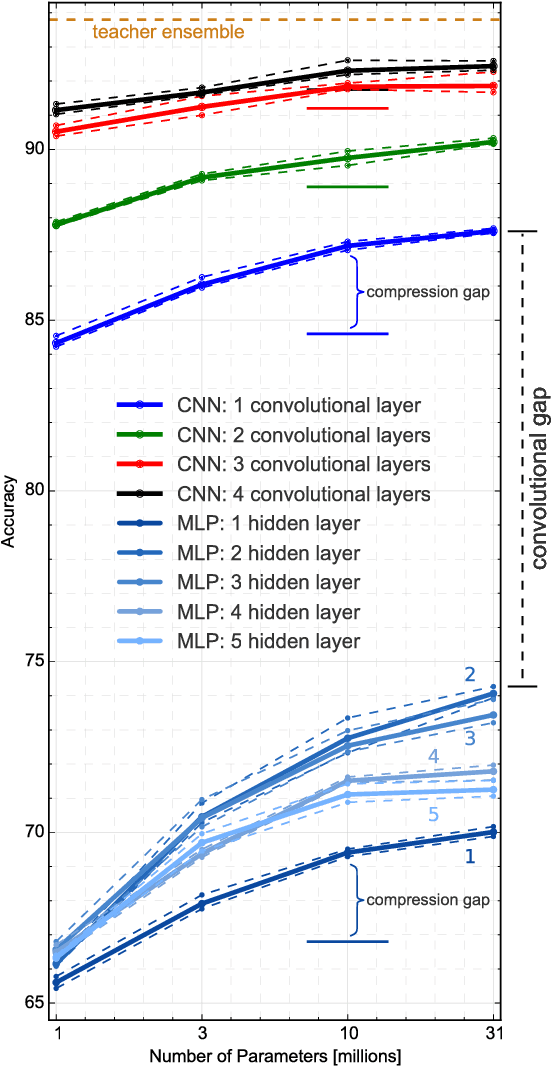
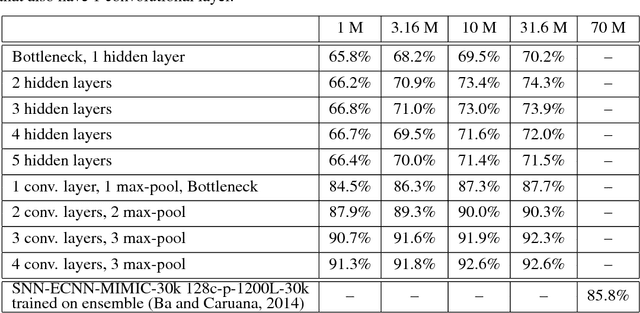
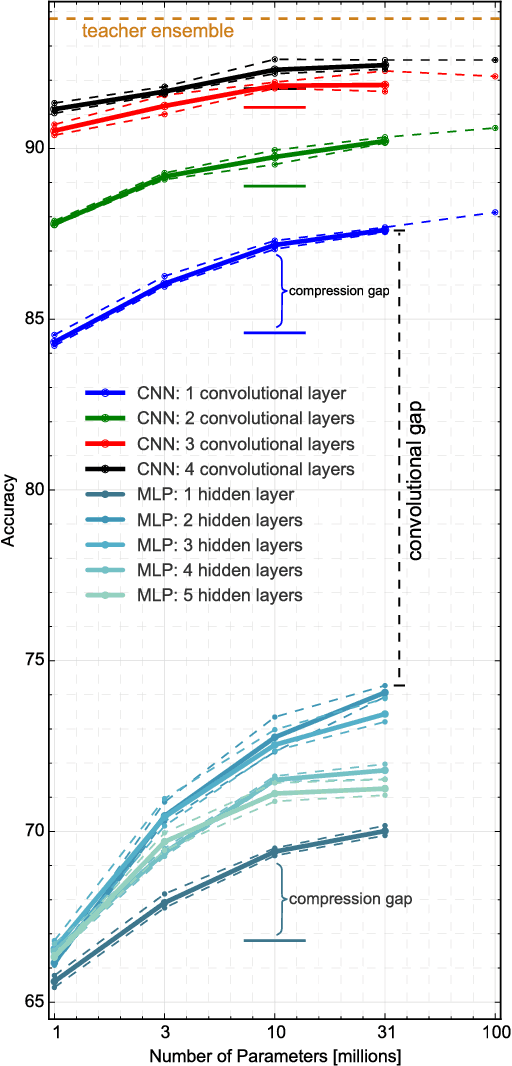
Yes, they do. This paper provides the first empirical demonstration that deep convolutional models really need to be both deep and convolutional, even when trained with methods such as distillation that allow small or shallow models of high accuracy to be trained. Although previous research showed that shallow feed-forward nets sometimes can learn the complex functions previously learned by deep nets while using the same number of parameters as the deep models they mimic, in this paper we demonstrate that the same methods cannot be used to train accurate models on CIFAR-10 unless the student models contain multiple layers of convolution. Although the student models do not have to be as deep as the teacher model they mimic, the students need multiple convolutional layers to learn functions of comparable accuracy as the deep convolutional teacher.
Blending LSTMs into CNNs
Sep 14, 2016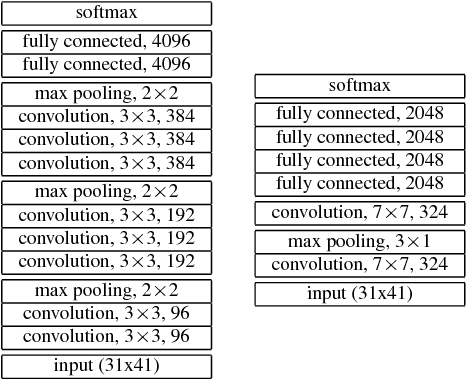
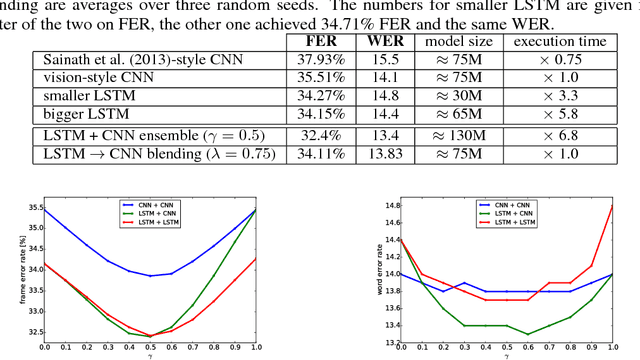

We consider whether deep convolutional networks (CNNs) can represent decision functions with similar accuracy as recurrent networks such as LSTMs. First, we show that a deep CNN with an architecture inspired by the models recently introduced in image recognition can yield better accuracy than previous convolutional and LSTM networks on the standard 309h Switchboard automatic speech recognition task. Then we show that even more accurate CNNs can be trained under the guidance of LSTMs using a variant of model compression, which we call model blending because the teacher and student models are similar in complexity but different in inductive bias. Blending further improves the accuracy of our CNN, yielding a computationally efficient model of accuracy higher than any of the other individual models. Examining the effect of "dark knowledge" in this model compression task, we find that less than 1% of the highest probability labels are needed for accurate model compression.