 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymphony: Optimized Model Serving using Centralized Orchestration
Aug 14, 2023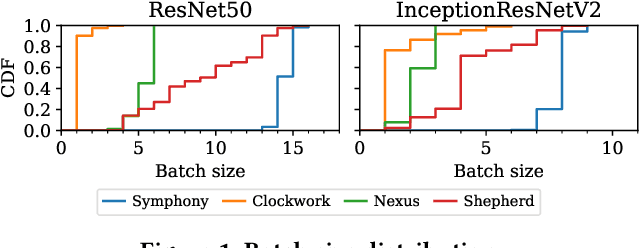
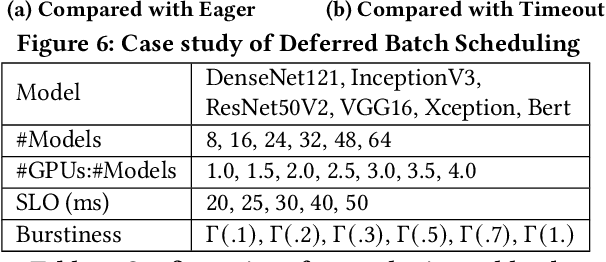
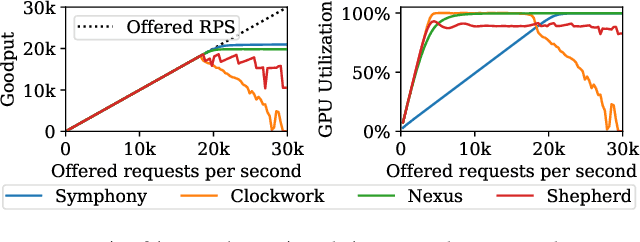
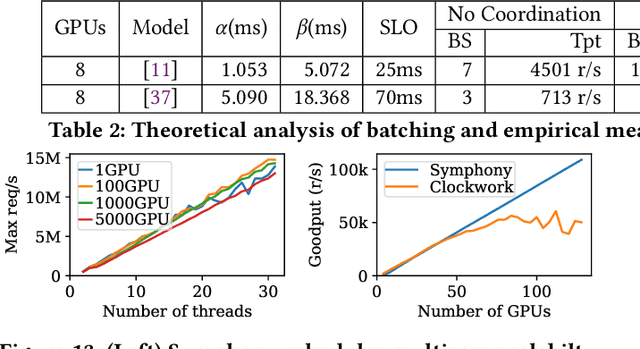
The orchestration of deep neural network (DNN) model inference on GPU clusters presents two significant challenges: achieving high accelerator efficiency given the batching properties of model inference while meeting latency service level objectives (SLOs), and adapting to workload changes both in terms of short-term fluctuations and long-term resource allocation. To address these challenges, we propose Symphony, a centralized scheduling system that can scale to millions of requests per second and coordinate tens of thousands of GPUs. Our system utilizes a non-work-conserving scheduling algorithm capable of achieving high batch efficiency while also enabling robust autoscaling. Additionally, we developed an epoch-scale algorithm that allocates models to sub-clusters based on the compute and memory needs of the models. Through extensive experiments, we demonstrate that Symphony outperforms prior systems by up to 4.7x higher goodput.
Heterogeneous Bitwidth Binarization in Convolutional Neural Networks
Oct 31, 2018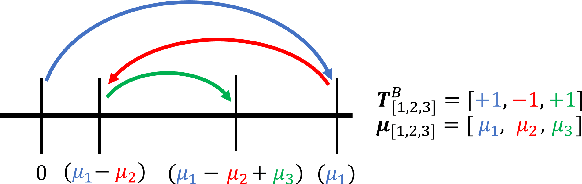
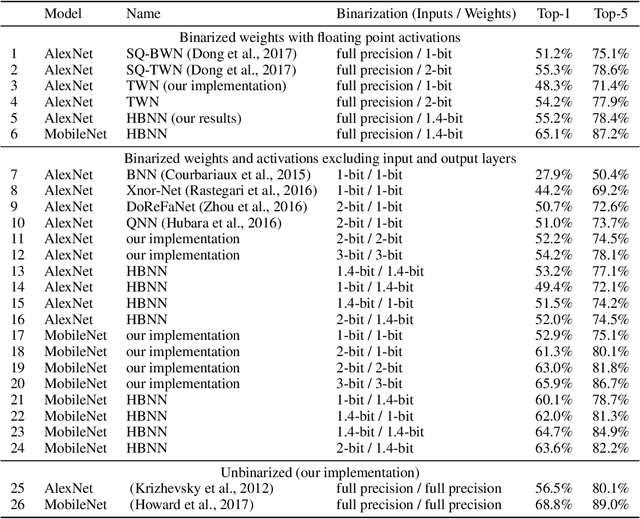
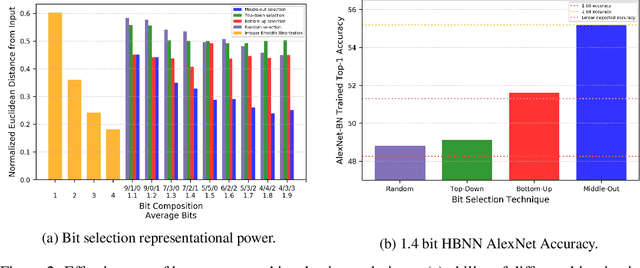
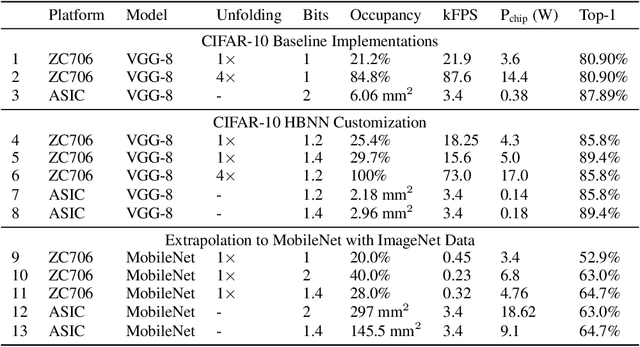
Recent work has shown that fast, compact low-bitwidth neural networks can be surprisingly accurate. These networks use homogeneous binarization: all parameters in each layer or (more commonly) the whole model have the same low bitwidth (e.g., 2 bits). However, modern hardware allows efficient designs where each arithmetic instruction can have a custom bitwidth, motivating heterogeneous binarization, where every parameter in the network may have a different bitwidth. In this paper, we show that it is feasible and useful to select bitwidths at the parameter granularity during training. For instance a heterogeneously quantized version of modern networks such as AlexNet and MobileNet, with the right mix of 1-, 2- and 3-bit parameters that average to just 1.4 bits can equal the accuracy of homogeneous 2-bit versions of these networks. Further, we provide analyses to show that the heterogeneously binarized systems yield FPGA- and ASIC-based implementations that are correspondingly more efficient in both circuit area and energy efficiency than their homogeneous counterparts.
Focus: Querying Large Video Datasets with Low Latency and Low Cost
Jan 10, 2018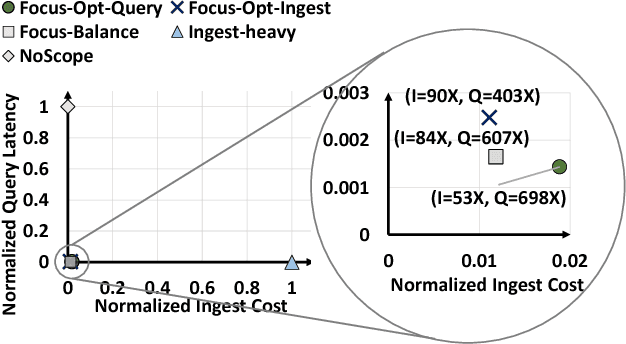
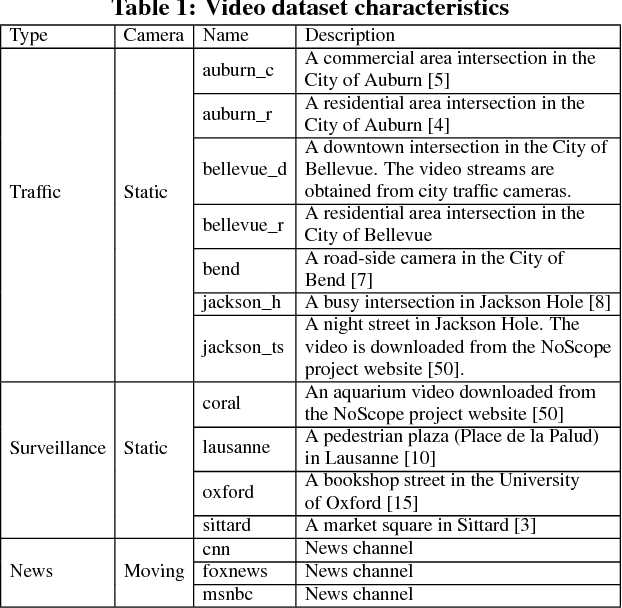
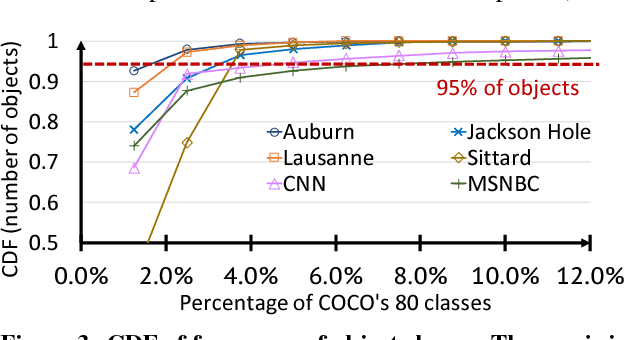
Large volumes of videos are continuously recorded from cameras deployed for traffic control and surveillance with the goal of answering "after the fact" queries: identify video frames with objects of certain classes (cars, bags) from many days of recorded video. While advancements in convolutional neural networks (CNNs) have enabled answering such queries with high accuracy, they are too expensive and slow. We build Focus, a system for low-latency and low-cost querying on large video datasets. Focus uses cheap ingestion techniques to index the videos by the objects occurring in them. At ingest-time, it uses compression and video-specific specialization of CNNs. Focus handles the lower accuracy of the cheap CNNs by judiciously leveraging expensive CNNs at query-time. To reduce query time latency, we cluster similar objects and hence avoid redundant processing. Using experiments on video streams from traffic, surveillance and news channels, we see that Focus uses 58X fewer GPU cycles than running expensive ingest processors and is 37X faster than processing all the video at query time.
Fast Video Classification via Adaptive Cascading of Deep Models
Jul 02, 2017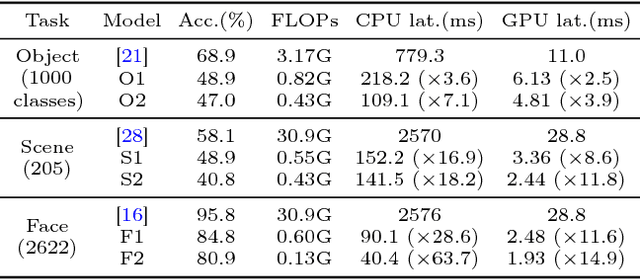

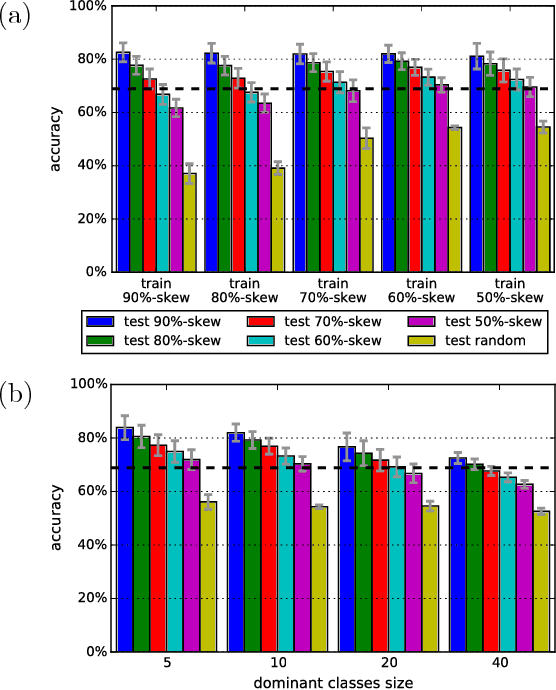
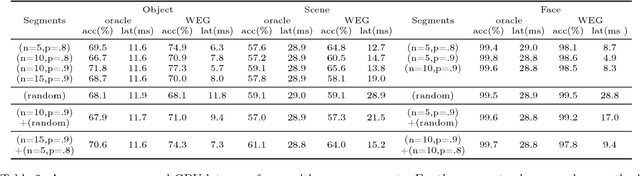
Recent advances have enabled "oracle" classifiers that can classify across many classes and input distributions with high accuracy without retraining. However, these classifiers are relatively heavyweight, so that applying them to classify video is costly. We show that day-to-day video exhibits highly skewed class distributions over the short term, and that these distributions can be classified by much simpler models. We formulate the problem of detecting the short-term skews online and exploiting models based on it as a new sequential decision making problem dubbed the Online Bandit Problem, and present a new algorithm to solve it. When applied to recognizing faces in TV shows and movies, we realize end-to-end classification speedups of 2.4-7.8x/2.6-11.2x (on GPU/CPU) relative to a state-of-the-art convolutional neural network, at competitive accuracy.
Do Deep Convolutional Nets Really Need to be Deep and Convolutional?
Mar 04, 2017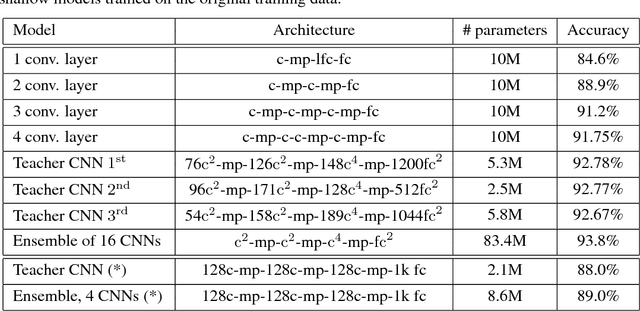
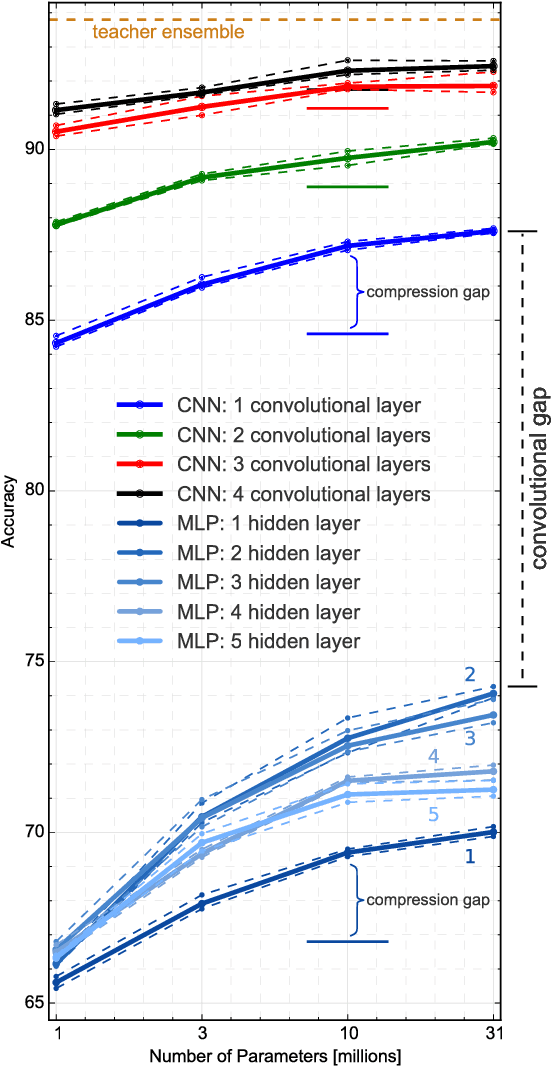
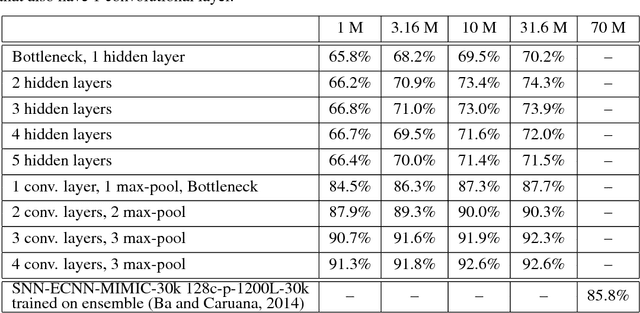
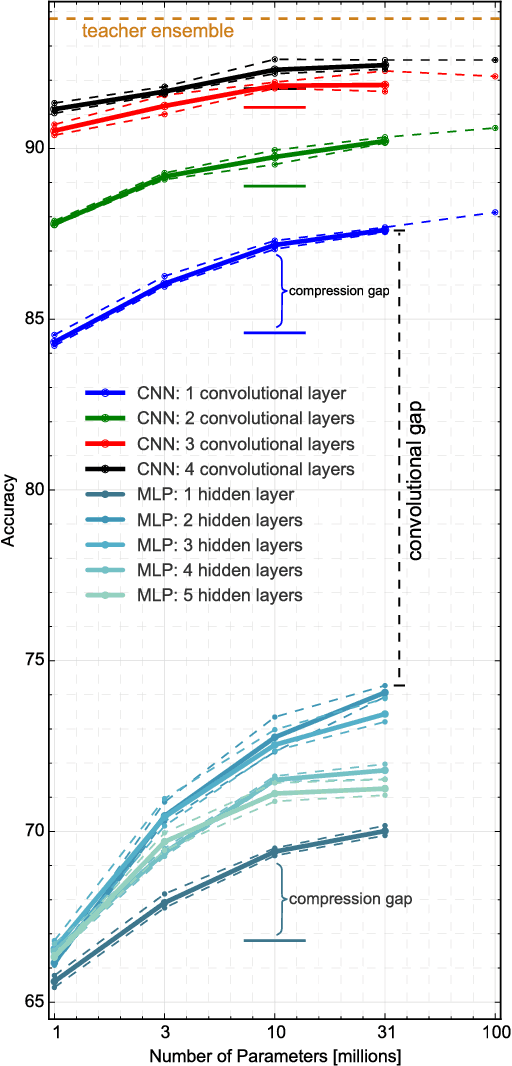
Yes, they do. This paper provides the first empirical demonstration that deep convolutional models really need to be both deep and convolutional, even when trained with methods such as distillation that allow small or shallow models of high accuracy to be trained. Although previous research showed that shallow feed-forward nets sometimes can learn the complex functions previously learned by deep nets while using the same number of parameters as the deep models they mimic, in this paper we demonstrate that the same methods cannot be used to train accurate models on CIFAR-10 unless the student models contain multiple layers of convolution. Although the student models do not have to be as deep as the teacher model they mimic, the students need multiple convolutional layers to learn functions of comparable accuracy as the deep convolutional teacher.
Blending LSTMs into CNNs
Sep 14, 2016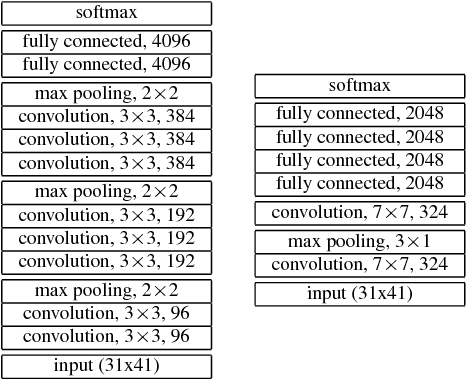
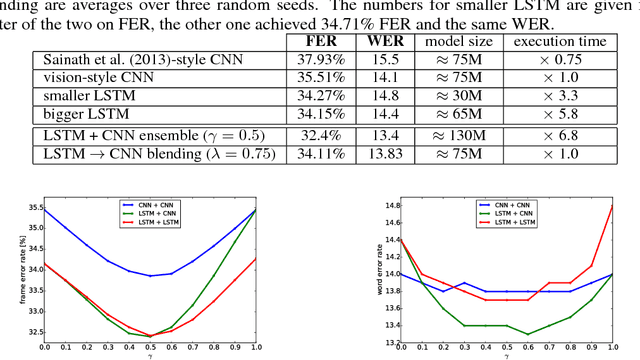

We consider whether deep convolutional networks (CNNs) can represent decision functions with similar accuracy as recurrent networks such as LSTMs. First, we show that a deep CNN with an architecture inspired by the models recently introduced in image recognition can yield better accuracy than previous convolutional and LSTM networks on the standard 309h Switchboard automatic speech recognition task. Then we show that even more accurate CNNs can be trained under the guidance of LSTMs using a variant of model compression, which we call model blending because the teacher and student models are similar in complexity but different in inductive bias. Blending further improves the accuracy of our CNN, yielding a computationally efficient model of accuracy higher than any of the other individual models. Examining the effect of "dark knowledge" in this model compression task, we find that less than 1% of the highest probability labels are needed for accurate model compression.