 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere does a computer vision model make mistakes? Using interactive visualizations to find where and how CV models can improve
May 19, 2023
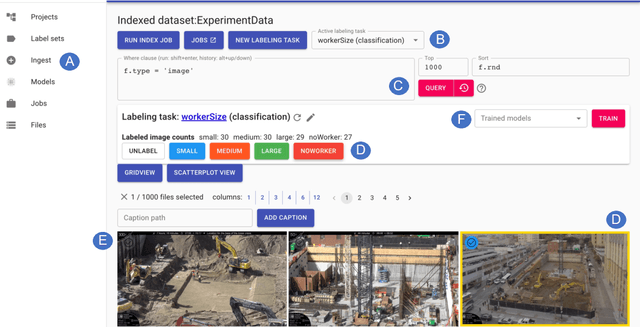
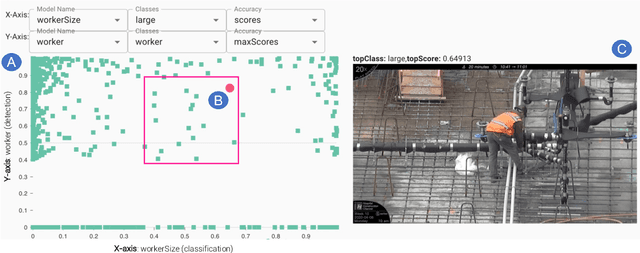
Creating Computer Vision (CV) models remains a complex and taxing practice for end-users to build, inspect, and improve these models. Interactive ML perspectives have helped address some of these issues by considering a teacher-in-the-loop where planning, teaching, and evaluating tasks take place. To improve the experience of end-users with various levels of ML expertise, we designed and evaluated two interactive visualizations in the context of Sprite, a system for creating CV classification and detection models for images originating from videos. We study how these visualizations, as part of the machine teaching loop, help users identify (evaluate) and select (plan) images where a model is struggling and improve the model being trained. We found that users who had used the visualizations found more images across a wider set of potential types of model errors, as well as in assessing and contrasting the prediction behavior of one or more models, thus reducing the potential effort required to improve a model.
Focus: Querying Large Video Datasets with Low Latency and Low Cost
Jan 10, 2018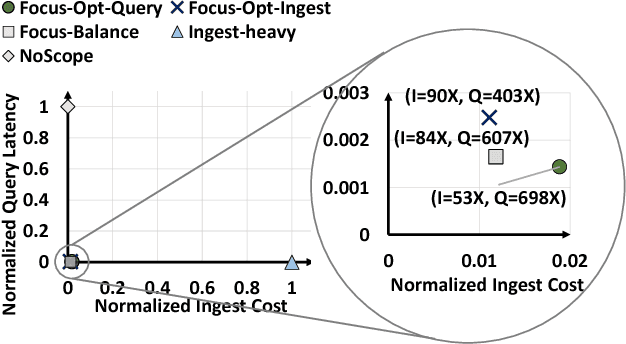
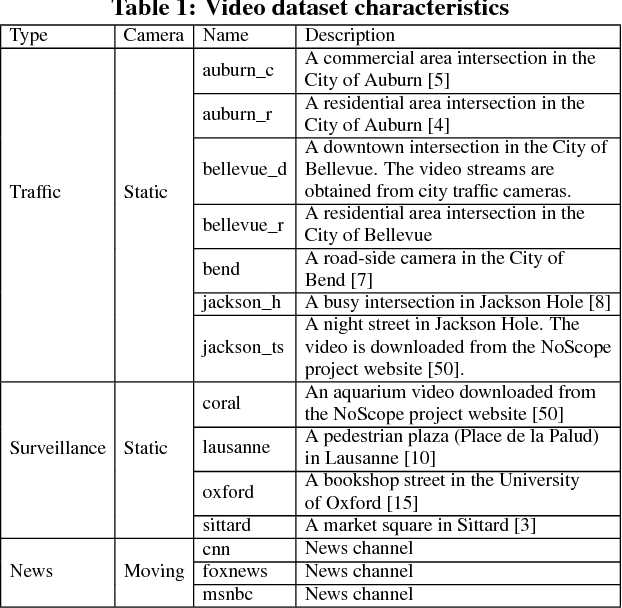
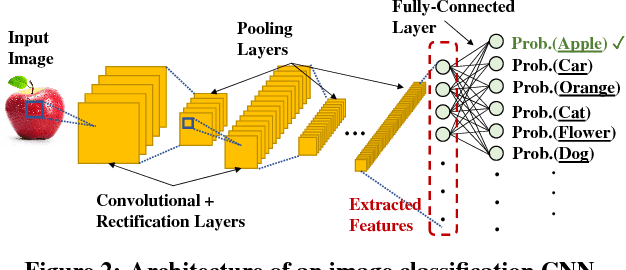
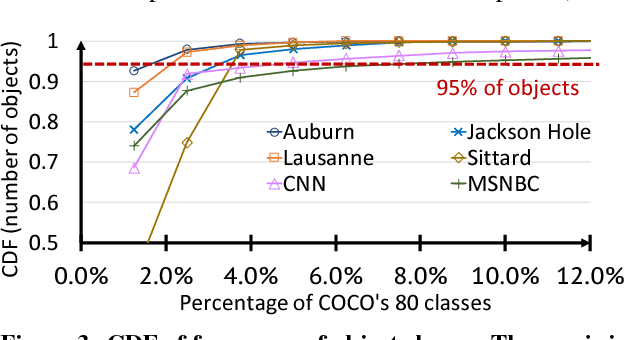
Large volumes of videos are continuously recorded from cameras deployed for traffic control and surveillance with the goal of answering "after the fact" queries: identify video frames with objects of certain classes (cars, bags) from many days of recorded video. While advancements in convolutional neural networks (CNNs) have enabled answering such queries with high accuracy, they are too expensive and slow. We build Focus, a system for low-latency and low-cost querying on large video datasets. Focus uses cheap ingestion techniques to index the videos by the objects occurring in them. At ingest-time, it uses compression and video-specific specialization of CNNs. Focus handles the lower accuracy of the cheap CNNs by judiciously leveraging expensive CNNs at query-time. To reduce query time latency, we cluster similar objects and hence avoid redundant processing. Using experiments on video streams from traffic, surveillance and news channels, we see that Focus uses 58X fewer GPU cycles than running expensive ingest processors and is 37X faster than processing all the video at query time.