 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxServe: Streaming-Centric Serving System for Speech Language Models
Jan 30, 2026Deploying modern Speech Language Models (SpeechLMs) in streaming settings requires systems that provide low latency, high throughput, and strong guarantees of streamability. Existing systems fall short of supporting diverse models flexibly and efficiently. We present VoxServe, a unified serving system for SpeechLMs that optimizes streaming performance. VoxServe introduces a model-execution abstraction that decouples model architecture from system-level optimizations, thereby enabling support for diverse SpeechLM architectures within a single framework. Building on this abstraction, VoxServe implements streaming-aware scheduling and an asynchronous inference pipeline to improve end-to-end efficiency. Evaluations across multiple modern SpeechLMs show that VoxServe achieves 10-20x higher throughput than existing implementations at comparable latency while maintaining high streaming viability. The code of VoxServe is available at https://github.com/vox-serve/vox-serve.
RLBoost: Harvesting Preemptible Resources for Cost-Efficient Reinforcement Learning on LLMs
Oct 22, 2025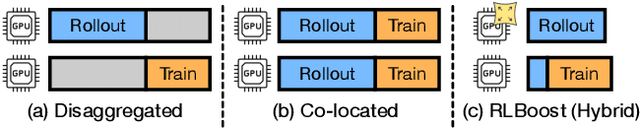
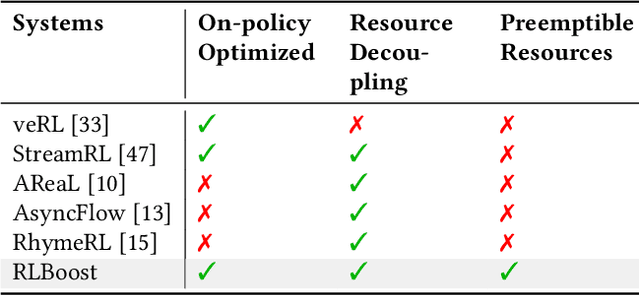
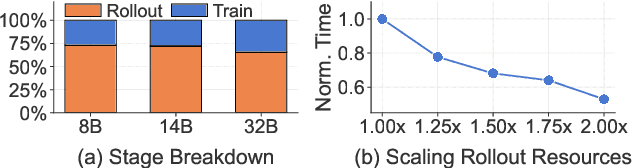
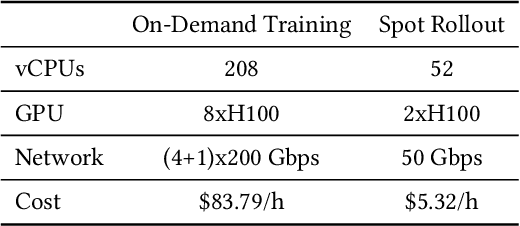
Reinforcement learning (RL) has become essential for unlocking advanced reasoning capabilities in large language models (LLMs). RL workflows involve interleaving rollout and training stages with fundamentally different resource requirements. Rollout typically dominates overall execution time, yet scales efficiently through multiple independent instances. In contrast, training requires tightly-coupled GPUs with full-mesh communication. Existing RL frameworks fall into two categories: co-located and disaggregated architectures. Co-located ones fail to address this resource tension by forcing both stages to share the same GPUs. Disaggregated architectures, without modifications of well-established RL algorithms, suffer from resource under-utilization. Meanwhile, preemptible GPU resources, i.e., spot instances on public clouds and spare capacity in production clusters, present significant cost-saving opportunities for accelerating RL workflows, if efficiently harvested for rollout. In this paper, we present RLBoost, a systematic solution for cost-efficient RL training that harvests preemptible GPU resources. Our key insight is that rollout's stateless and embarrassingly parallel nature aligns perfectly with preemptible and often fragmented resources. To efficiently utilize these resources despite frequent and unpredictable availability changes, RLBoost adopts a hybrid architecture with three key techniques: (1) adaptive rollout offload to dynamically adjust workloads on the reserved (on-demand) cluster, (2) pull-based weight transfer that quickly provisions newly available instances, and (3) token-level response collection and migration for efficient preemption handling and continuous load balancing. Extensive experiments show RLBoost increases training throughput by 1.51x-1.97x while improving cost efficiency by 28%-49% compared to using only on-demand GPU resources.
SuperGen: An Efficient Ultra-high-resolution Video Generation System with Sketching and Tiling
Aug 25, 2025Diffusion models have recently achieved remarkable success in generative tasks (e.g., image and video generation), and the demand for high-quality content (e.g., 2K/4K videos) is rapidly increasing across various domains. However, generating ultra-high-resolution videos on existing standard-resolution (e.g., 720p) platforms remains challenging due to the excessive re-training requirements and prohibitively high computational and memory costs. To this end, we introduce SuperGen, an efficient tile-based framework for ultra-high-resolution video generation. SuperGen features a novel training-free algorithmic innovation with tiling to successfully support a wide range of resolutions without additional training efforts while significantly reducing both memory footprint and computational complexity. Moreover, SuperGen incorporates a tile-tailored, adaptive, region-aware caching strategy that accelerates video generation by exploiting redundancy across denoising steps and spatial regions. SuperGen also integrates cache-guided, communication-minimized tile parallelism for enhanced throughput and minimized latency. Evaluations demonstrate that SuperGen harvests the maximum performance gains while achieving high output quality across various benchmarks.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025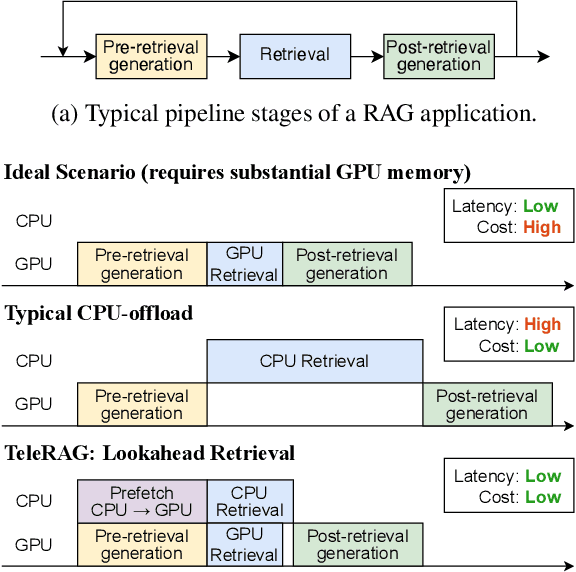



Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
Tactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context LLMs
Feb 17, 2025Long-context models are essential for many applications but face inefficiencies in loading large KV caches during decoding. Prior methods enforce fixed token budgets for sparse attention, assuming a set number of tokens can approximate full attention. However, these methods overlook variations in the importance of attention across heads, layers, and contexts. To address these limitations, we propose Tactic, a sparsity-adaptive and calibration-free sparse attention mechanism that dynamically selects tokens based on their cumulative attention scores rather than a fixed token budget. By setting a target fraction of total attention scores, Tactic ensures that token selection naturally adapts to variations in attention sparsity. To efficiently approximate this selection, Tactic leverages clustering-based sorting and distribution fitting, allowing it to accurately estimate token importance with minimal computational overhead. We show that Tactic outperforms existing sparse attention algorithms, achieving superior accuracy and up to 7.29x decode attention speedup. This improvement translates to an overall 1.58x end-to-end inference speedup, making Tactic a practical and effective solution for long-context LLM inference in accuracy-sensitive applications.
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Jan 02, 2025



Transformers, driven by attention mechanisms, form the foundation of large language models (LLMs). As these models scale up, efficient GPU attention kernels become essential for high-throughput and low-latency inference. Diverse LLM applications demand flexible and high-performance attention solutions. We present FlashInfer: a customizable and efficient attention engine for LLM serving. FlashInfer tackles KV-cache storage heterogeneity using block-sparse format and composable formats to optimize memory access and reduce redundancy. It also offers a customizable attention template, enabling adaptation to various settings through Just-In-Time (JIT) compilation. Additionally, FlashInfer's load-balanced scheduling algorithm adjusts to dynamism of user requests while maintaining compatibility with CUDAGraph which requires static configuration. FlashInfer have been integrated into leading LLM serving frameworks like SGLang, vLLM and MLC-Engine. Comprehensive kernel-level and end-to-end evaluations demonstrate FlashInfer's ability to significantly boost kernel performance across diverse inference scenarios: compared to state-of-the-art LLM serving solutions, FlashInfer achieve 29-69% inter-token-latency reduction compared to compiler backends for LLM serving benchmark, 28-30% latency reduction for long-context inference, and 13-17% speedup for LLM serving with parallel generation.
ForestColl: Efficient Collective Communications on Heterogeneous Network Fabrics
Feb 09, 2024



As modern DNN models grow ever larger, collective communications between the accelerators (allreduce, etc.) emerge as a significant performance bottleneck. Designing efficient communication schedules is challenging given today's highly diverse and heterogeneous network fabrics. In this paper, we present ForestColl, a tool that generates efficient schedules for any network topology. ForestColl constructs broadcast/aggregation spanning trees as the communication schedule, achieving theoretically minimum network congestion. Its schedule generation runs in strongly polynomial time and is highly scalable. ForestColl supports any network fabrics, including both switching fabrics and direct connections, as well as any network graph structure. We evaluated ForestColl on multi-cluster AMD MI250 and NVIDIA A100 platforms. ForestColl's schedules achieved up to 52\% higher performance compared to the vendors' own optimized communication libraries, RCCL and NCCL. ForestColl also outperforms other state-of-the-art schedule generation techniques with both up to 61\% more efficient generated schedules and orders of magnitude faster schedule generation speed.
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Nov 07, 2023



The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to $7.73\times$ compared to the FP16 and by $2.53\times$ compared to INT8 quantization, while maintaining the same latency target.
Punica: Multi-Tenant LoRA Serving
Oct 28, 2023
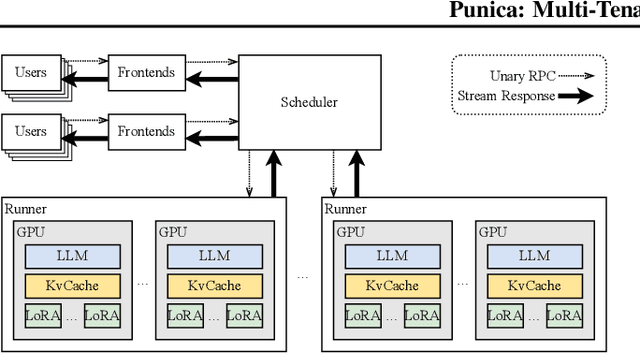
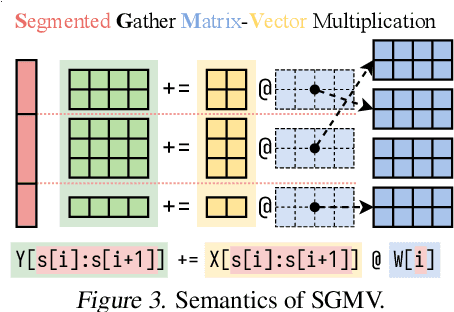
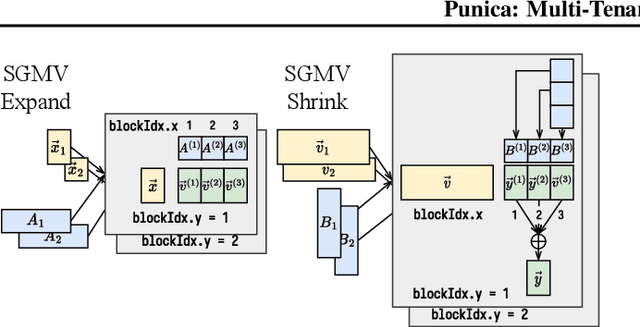
Low-rank adaptation (LoRA) has become an important and popular method to adapt pre-trained models to specific domains. We present Punica, a system to serve multiple LoRA models in a shared GPU cluster. Punica contains a new CUDA kernel design that allows batching of GPU operations for different LoRA models. This allows a GPU to hold only a single copy of the underlying pre-trained model when serving multiple, different LoRA models, significantly enhancing GPU efficiency in terms of both memory and computation. Our scheduler consolidates multi-tenant LoRA serving workloads in a shared GPU cluster. With a fixed-sized GPU cluster, our evaluations show that Punica achieves 12x higher throughput in serving multiple LoRA models compared to state-of-the-art LLM serving systems while only adding 2ms latency per token. Punica is open source at https://github.com/punica-ai/punica .
Symphony: Optimized Model Serving using Centralized Orchestration
Aug 14, 2023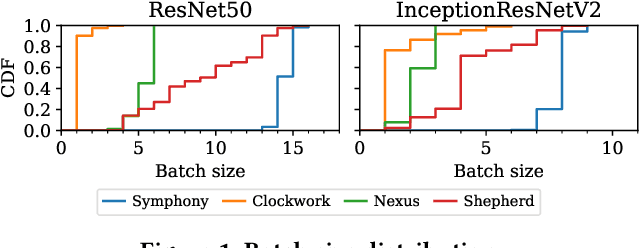
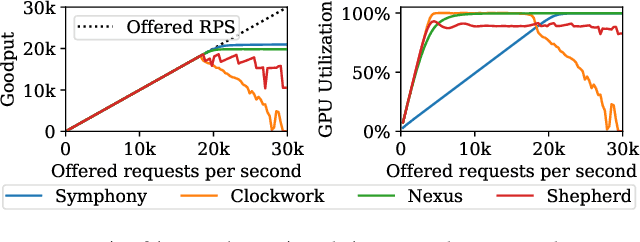
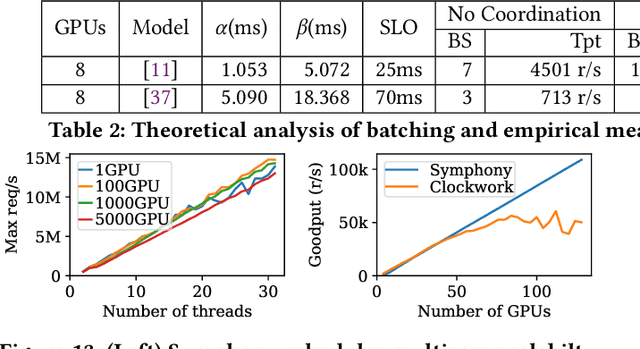
The orchestration of deep neural network (DNN) model inference on GPU clusters presents two significant challenges: achieving high accelerator efficiency given the batching properties of model inference while meeting latency service level objectives (SLOs), and adapting to workload changes both in terms of short-term fluctuations and long-term resource allocation. To address these challenges, we propose Symphony, a centralized scheduling system that can scale to millions of requests per second and coordinate tens of thousands of GPUs. Our system utilizes a non-work-conserving scheduling algorithm capable of achieving high batch efficiency while also enabling robust autoscaling. Additionally, we developed an epoch-scale algorithm that allocates models to sub-clusters based on the compute and memory needs of the models. Through extensive experiments, we demonstrate that Symphony outperforms prior systems by up to 4.7x higher goodput.