 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYUV20K: A Complexity-Driven Benchmark and Trajectory-Aware Alignment Model for Video Camouflaged Object Detection
Apr 11, 2026Video Camouflaged Object Detection (VCOD) is currently constrained by the scarcity of challenging benchmarks and the limited robustness of models against erratic motion dynamics. Existing methods often struggle with Motion-Induced Appearance Instability and Temporal Feature Misalignment caused by complex motion scenarios. To address the data bottleneck, we present YUV20K, a pixel-level annoated complexity-driven VCOD benchmark. Comprising 24,295 annotated frames across 91 scenes and 47 kinds of species, it specifically targets challenging scenarios like large-displacement motion, camera motion and other 4 types scenarios. On the methodological front, we propose a novel framework featuring two key modules: Motion Feature Stabilization (MFS) and Trajectory-Aware Alignment (TAA). The MFS module utilizes frame-agnostic Semantic Basis Primitives to stablize features, while the TAA module leverages trajectory-guided deformable sampling to ensure precise temporal alignment. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art competitors on existing datasets and establishes a new baseline on the challenging YUV20K. Notably, our framework exhibits superior cross-domain generalization and robustness when confronting complex spatiotemporal scenarios. Our code and dataset will be available at https://github.com/K1NSA/YUV20K
High-Resolution Underwater Camouflaged Object Detection: GBU-UCOD Dataset and Topology-Aware and Frequency-Decoupled Networks
Feb 03, 2026Underwater Camouflaged Object Detection (UCOD) is a challenging task due to the extreme visual similarity between targets and backgrounds across varying marine depths. Existing methods often struggle with topological fragmentation of slender creatures in the deep sea and the subtle feature extraction of transparent organisms. In this paper, we propose DeepTopo-Net, a novel framework that integrates topology-aware modeling with frequency-decoupled perception. To address physical degradation, we design the Water-Conditioned Adaptive Perceptor (WCAP), which employs Riemannian metric tensors to dynamically deform convolutional sampling fields. Furthermore, the Abyssal-Topology Refinement Module (ATRM) is developed to maintain the structural connectivity of spindly targets through skeletal priors. Specifically, we first introduce GBU-UCOD, the first high-resolution (2K) benchmark tailored for marine vertical zonation, filling the data gap for hadal and abyssal zones. Extensive experiments on MAS3K, RMAS, and our proposed GBU-UCOD datasets demonstrate that DeepTopo-Net achieves state-of-the-art performance, particularly in preserving the morphological integrity of complex underwater patterns. The datasets and codes will be released at https://github.com/Wuwenji18/GBU-UCOD.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025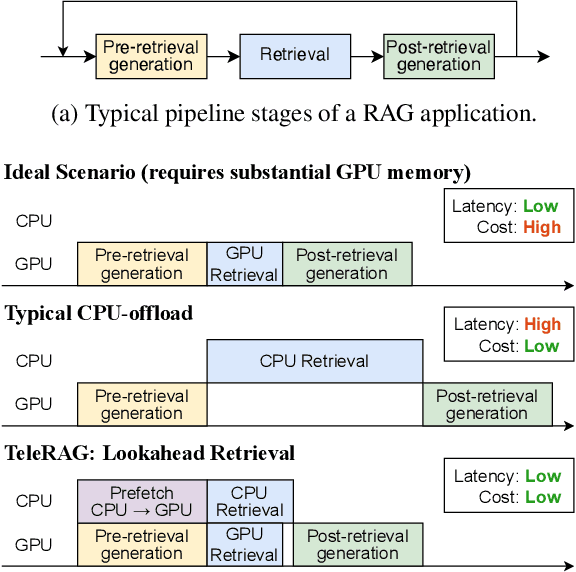



Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
Concept-Aware Denoising Graph Neural Network for Micro-Video Recommendation
Sep 28, 2021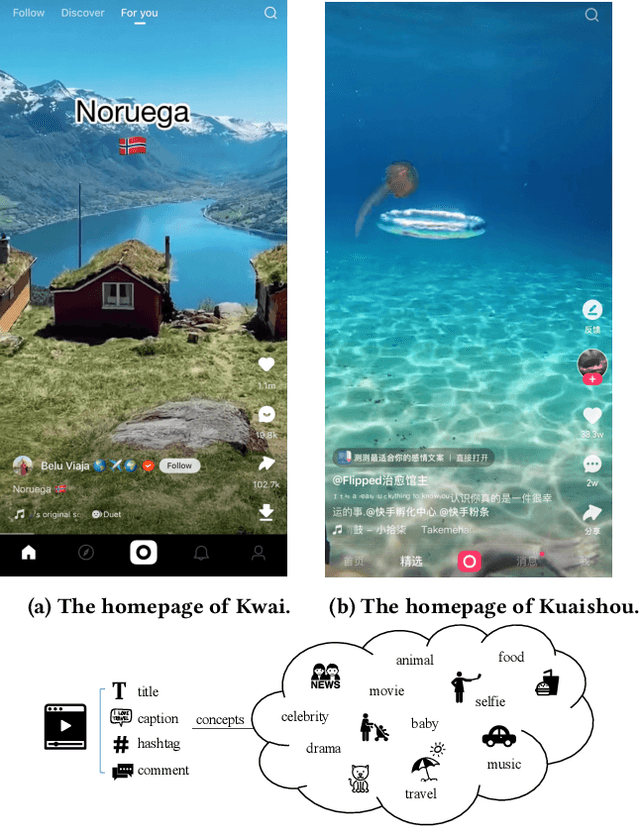

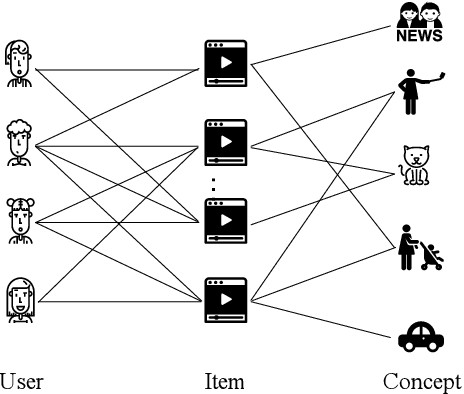
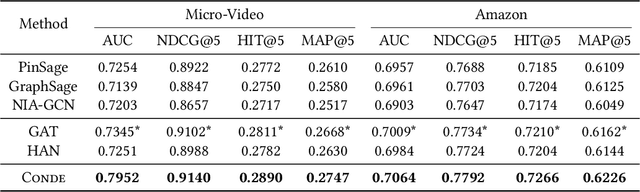
Recently, micro-video sharing platforms such as Kuaishou and Tiktok have become a major source of information for people's lives. Thanks to the large traffic volume, short video lifespan and streaming fashion of these services, it has become more and more pressing to improve the existing recommender systems to accommodate these challenges in a cost-effective way. In this paper, we propose a novel concept-aware denoising graph neural network (named CONDE) for micro-video recommendation. CONDE consists of a three-phase graph convolution process to derive user and micro-video representations: warm-up propagation, graph denoising and preference refinement. A heterogeneous tripartite graph is constructed by connecting user nodes with video nodes, and video nodes with associated concept nodes, extracted from captions and comments of the videos. To address the noisy information in the graph, we introduce a user-oriented graph denoising phase to extract a subgraph which can better reflect the user's preference. Despite the main focus of micro-video recommendation in this paper, we also show that our method can be generalized to other types of tasks. Therefore, we also conduct empirical studies on a well-known public E-commerce dataset. The experimental results suggest that the proposed CONDE achieves significantly better recommendation performance than the existing state-of-the-art solutions.
MATINF: A Jointly Labeled Large-Scale Dataset for Classification, Question Answering and Summarization
May 23, 2020
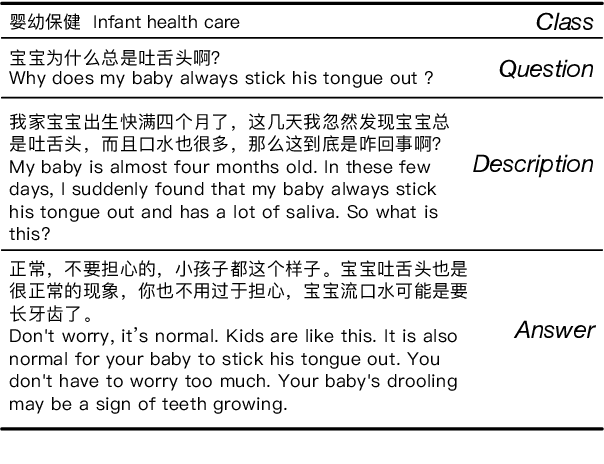
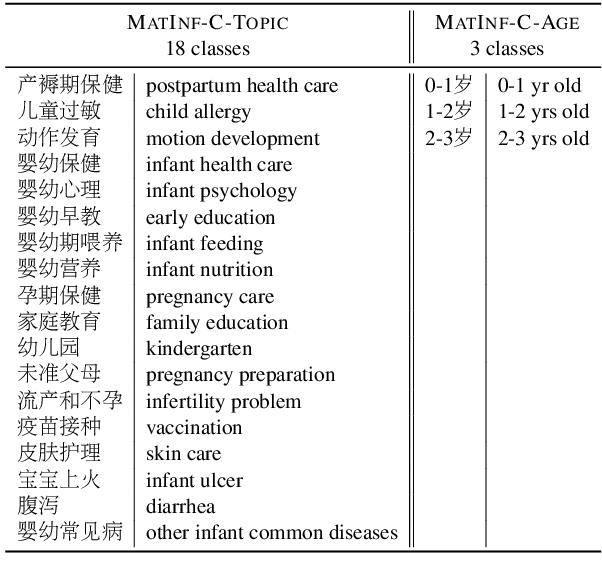
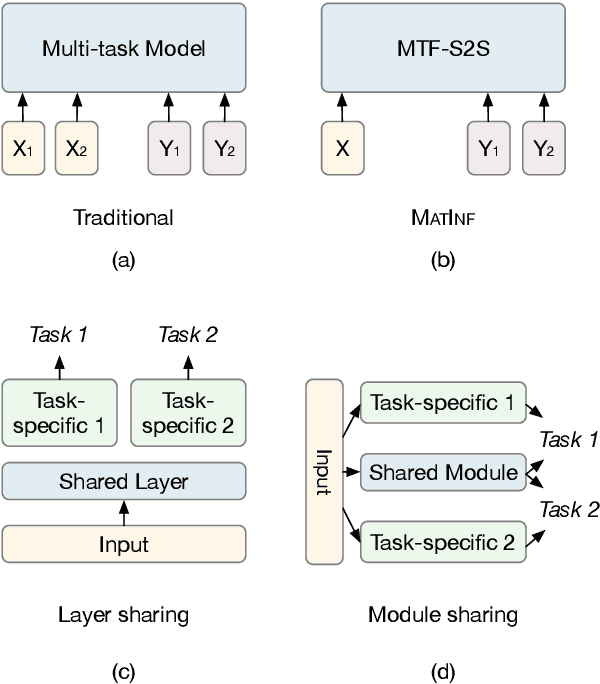
Recently, large-scale datasets have vastly facilitated the development in nearly all domains of Natural Language Processing. However, there is currently no cross-task dataset in NLP, which hinders the development of multi-task learning. We propose MATINF, the first jointly labeled large-scale dataset for classification, question answering and summarization. MATINF contains 1.07 million question-answer pairs with human-labeled categories and user-generated question descriptions. Based on such rich information, MATINF is applicable for three major NLP tasks, including classification, question answering, and summarization. We benchmark existing methods and a novel multi-task baseline over MATINF to inspire further research. Our comprehensive comparison and experiments over MATINF and other datasets demonstrate the merits held by MATINF.